序言
序言
本书适合谁
本书适合那些负责的产品有代码库但自己不去读的产品经理。
如果你曾经为了等待工程回答"这个功能是怎么工作的?"而苦等,或者花了数小时手动综合那些本可以程序化处理的客户反馈,本书将为你展示一条更好的路径。
你不需要专业写代码,也不需要深厚的 CLI 经验。你需要接受一个观念:有些 PM 任务由拥有文件系统访问权限的 Agent 来完成,比对话式 AI 更好。
你将学到什么
读完本书后,你将能够:
- 为每项 PM 任务选择合适的 AI 工具(Claude.ai vs. Claude Code)
- 安全地安装和配置 Claude Code,并带有费用控制
- 独立调查你的代码库来回答问题
- 将研究和反馈综合为结构化的产出物
- 为重复性的 PM 任务构建可复用的工作流(Skill)
- 通过 MCP 连接到你的 PM 技术栈(Jira、Slack、Figma)
- 在使用 AI 工具的同时与工程团队有效协作
本书不是什么
这不是一本全方位的 Claude Code 手册,不是技术参考,也不是写给工程师看的。
本书严格聚焦于 PM 用例。如果某个问题你实际上并不会遇到,它就不会出现在本书中。
如何使用本书
如果你是 Claude Code 新手:阅读第一部分(基础)来理解工具选择和安装,然后跳到你最迫切需要的部分。
如果你已经在使用 Claude Code:跳转到第二部分(代码库情报)或第四部分(Skill),取决于你是想调查还是想自动化。
如果你持怀疑态度:阅读第 1 章。如果决策框架没有打动你,那这个工具可能暂时还不适合你。
每章都包含你可以直接复制的确切 Prompt、费用估算和失败模式。在页边空白处做笔记,跳过不相关的章节,等需要时再回来翻看。
关于时效性的说明
AI 工具演进迅速。本书聚焦于持久的概念——工具选择的决策框架、可重复工作流的结构、与工程团队协作的模式——同时提供具体的示例,这些示例可能随着 Claude Code 的变化而需要调整。
当功能改变时,原则不变:为任务选择合适的工具,控制你的成本,优雅地失败,尊重工程专业知识。
让我们开始吧。
第1章
为什么 PM 要用 Claude Code——而非 Claude.ai
1.1 选对工具,每周节省数小时
一位客户报告了你结账流程中的严重 bug。工程团队正在全力冲刺季度路线图。你需要分类判断:真实 bug 还是用户操作失误?影响范围多大?归属哪个团队?你只能等工程团队切换上下文、完成调查、提交报告。两天过去了,这个 bug 仍然停留在分类状态。
或者:你在自己的仓库中打开 Claude Code,问一句"结账验证是如何工作的?请展示一下空支付方式可能绕过校验的位置",10 分钟内就能获得附带纯英文解释的文件引用。你把调查结果连同具体代码位置整理成文。工程团队直接确认并修复,无需额外发现阶段。总耗时:15 分钟。
这两种情形的差异在于工具选择。大多数 PM 因为熟悉而默认用 Claude.ai 处理一切,然后困惑为什么 AI 没有改变自己的工作流。网页界面能很好地处理对话式任务,但在对 PM 最重要的那些工作中却力不从心:深入调查代码库、生成属于仓库的制品、构建可重复的流程。
你有三种访问 Claude 的方式:Claude.ai 网页界面、API,以及 Claude Code。API 是给构建集成的工程师用的。Claude.ai 和 Claude Code 都面向 PM,但二者解决的是不同问题。选错工具代价高昂。
Claude Code 是一个智能体,拥有文件系统访问权限、shell 命令执行能力,并且能跨会话持久化上下文。当你的工作涉及文件、代码仓库或可重复流程时(无论你是否专业写代码),这些能力就格外重要。
选错工具的隐性成本如下:你在 Claude.ai 上花 30 分钟解释代码库上下文,要求它分析存储在 CSV 中的客户反馈,并生成一份综合文档。它给了你一份深思熟虑的回复。你复制粘贴到 Google Doc 中。两周后,你需要对新一轮反馈运行同样的分析。一切从零开始:同样 30 分钟的背景说明,同样的手动导出,同样的复制粘贴。至此你在这项任务上花了一个小时,而 Claude Code 通过一个可复用的 skill 只需 5 分钟。
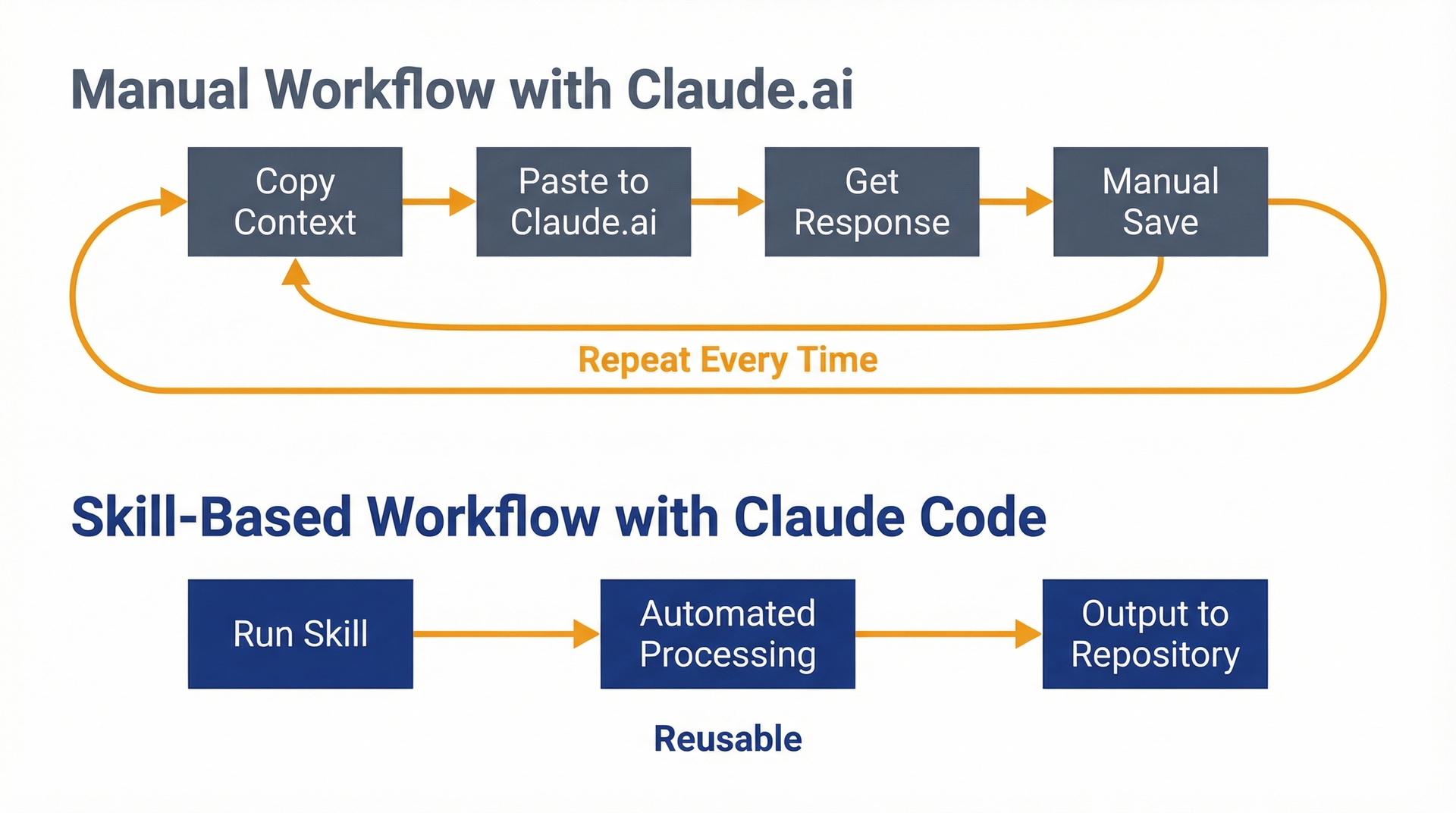
图 1.1:工作流对比——用于理解选错工具的隐性成本。左侧:手动复制粘贴工作流,每次都重复上下文说明、手动导出和重新格式化。右侧:基于 skill 的自动化,设置只需一次,后续每次运行只需 5 分钟而非 30 分钟。
或者,你需要理解结账流程的工作原理,因为有一个严重 bug 报告送来了。你去问工程团队,但他们正在冲刺规划中。你尝试用 Claude.ai,但你不可能上传整个代码库,缺乏上下文时它的回答只能泛泛而谈。你只能等。工程团队明天才能回复你。这个 bug 又多搁置了一天。如果你用了 Claude Code,10 分钟内你就能得出一个有根因假设的调查结论,并附上相关文件和函数的具体引用。
工具选择问题的核心在于任务持久性和数据访问能力。当工作存在于文件中、需要迭代、或者要做不止一次时,网页界面强加的手动开销会在每次重复中叠加放大。Claude Code 通过直接在你的工作空间中运行,消除了这种开销。
大多数 PM 是通过浪费来发现这一点的。他们用 Claude.ai 好几周,后来才意识到自己一直在把相同的上下文复制到每段对话中,手动重新格式化输出,重做本应自动化的工作。切换成本看似很高:安装、学习命令、理解权限模式。但浪费成本更高,而且是在无声地累积。
决策不在于技术能力的高低,而在于你的工作是否涉及需要反复操作的文件,或者这只是一次性问题。诚实地回答这个问题,工具选择自然就清晰了。
1.2 Claude Code 如何工作:自主行动胜过对话
Claude Code 是一个智能体运行时。这是技术术语。对于产品经理来说,这意味着 Claude 能够行动而不仅仅是回应。当你向 Claude.ai 提问时,它思考并回答。当你向 Claude Code 提问时,它思考、读取文件、运行命令、生成制品、检查自己的工作,然后才回答。区别在于自主性。
这一点非常重要,因为 PM 的工作很大程度上是关于跨分散来源的信息综合。需求在 Jira 中,客户反馈在 Zendesk 导出文件中,实现细节在代码库中,市场研究在书签 URL 和凌乱的笔记中。获得一个连贯的答案需要从所有这些来源提取信息,而手动完成这一切会耗费好几个小时。
Claude Code 在你的项目目录中运行,拥有 Claude.ai 从根本上缺少的五项能力。理解这些能力,你就能判断何时需要智能体而不仅仅是对话。
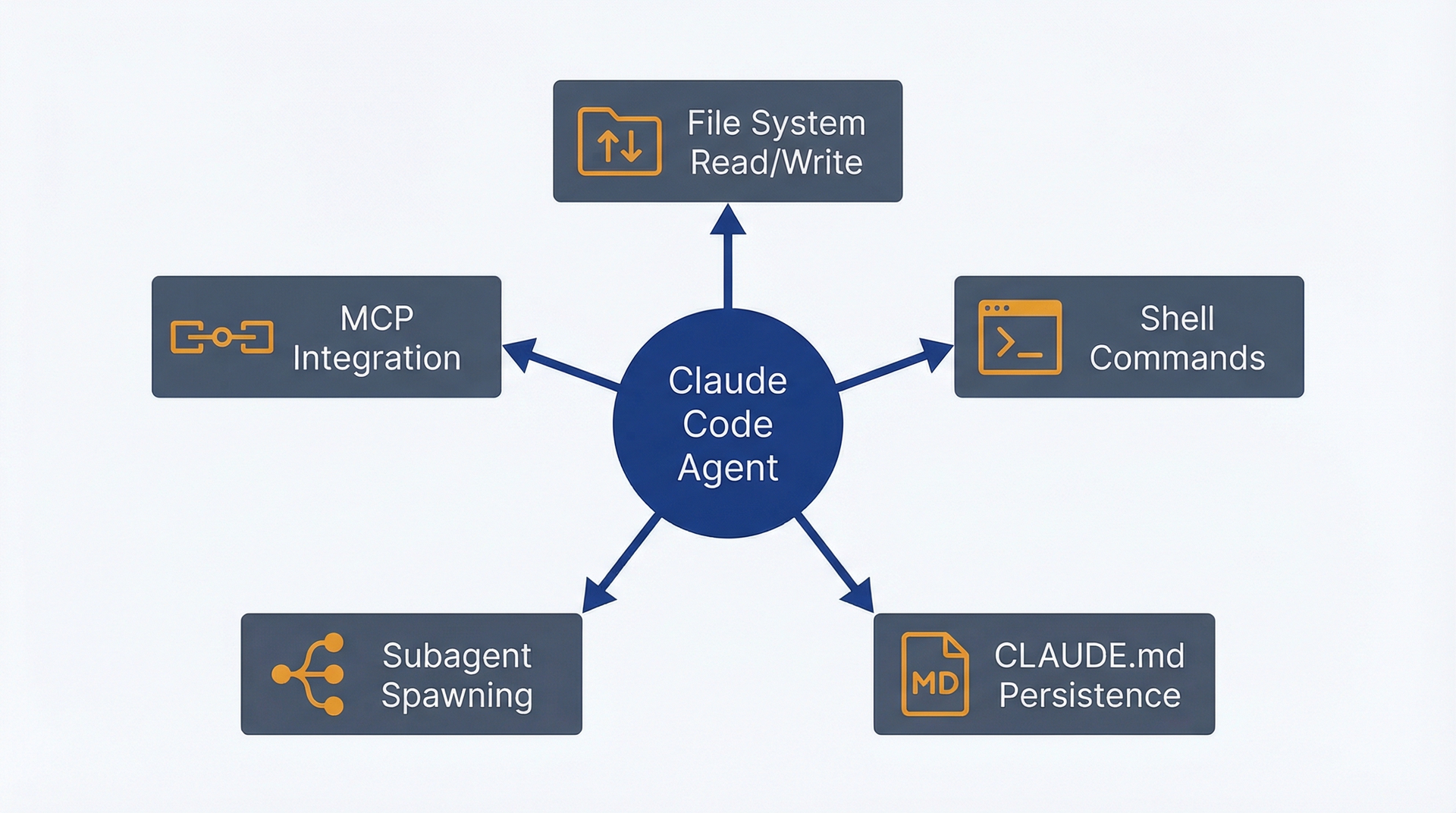
图 1.2:五大核心能力——用于理解 Claude Code 能做到而 Claude.ai 做不到的事情。文件系统读写访问、shell 命令执行、通过 CLAUDE.md 实现持久化项目上下文、用于并行工作的子智能体派发,以及通过 MCP 集成外部系统。这些能力实现了代码库调查、制品生成和可重复工作流。
文件系统读写访问。Claude Code 可以打开项目中的任何文件,阅读、理解并写入新文件或修改现有文件。这听起来很基础,直到你意识到 Claude.ai 需要你复制粘贴一切。分析反馈时需要引用 PRD?用 Claude.ai 的话,你要粘贴 PRD、粘贴反馈、请求综合分析,然后手动保存输出。用 Claude Code,你只需指向 docs/prd.md 和 data/feedback.csv,它就会直接在仓库中生成 analysis/synthesis.md。无需剪贴板,无需手动格式化,不会出现粘贴错误。
对于 PM 来说,这意味着调查输出会保留在它们应该在的地方:在版本控制中,与它们引用的代码并列,对团队可访问。你的代码库分析变成了一份 markdown 文件,工程团队可以阅读、评论和更新。
Shell 命令执行。Claude Code 可以运行终端命令。对于 PM 来说,这主要意味着 git 操作(查看历史记录、比较分支、查看谁改了什么)以及运行那些你自己不会写但能说清需求的分析脚本。
具体例子:你需要了解某个功能是什么时候引入的、谁参与了开发。你可以请工程团队运行 git log 并解读结果,也可以直接问 Claude Code:"结账流程的二步验证是什么时候添加的,当时的理由是什么?"它运行 git 命令,读取相关提交记录和文件变更,然后告诉你来龙去脉。无需打扰工程团队。
这让终端能力通过自然语言变得可用,无需专业知识。
通过 CLAUDE.md 实现持久化项目上下文。每次打开 Claude.ai,你都是从头开始。每次在项目目录中启动 Claude Code,如果存在 CLAUDE.md 文件,它就会读取这个文件:该文件包含跨所有会话持久化的项目特定上下文。
对于 PM 来说,这个文件可能包含你的产品领域词汇表、映射到代码区域的关键用户旅程、团队约定、外部文档链接,以及常见调查问题的答案。你只需构建一次这样的上下文,后续每次会话开始时就已拥有充分的信息。不再需要每次对话都加一段"这是我们产品做什么"的开场白。
这就是聪明助手和团队成员的区别。团队成员有上下文。拥有维护良好的 CLAUDE.md 的 Claude Code 就有上下文。
子智能体派发。Claude Code 可以启动额外的 Claude 实例来并行处理子任务或以专门聚焦的方式工作。作为 PM,你很少直接调用它,但它支撑着复杂的工作流。
例如:你要求 Claude Code 准备一份竞品分析,将你的产品与三个竞争对手在功能、定价和定位方面进行比较。它不是按顺序依次处理,而是可以派发三个子智能体(每个竞品一个)并行研究,然后将结果汇总为对比矩阵。原本需要你花三个小时在各标签页间切换的工作,10 分钟即可完成。
这里的成本是真实的(你在同时运行多个 Claude 实例),但对于高价值的研究任务,节省的时间往往值得投入。
通过 MCP 集成外部系统。Model Context Protocol 让 Claude Code 能够连接到外部工具:Jira、Slack、Figma、数据库、分析平台。这是最新的能力,也是入门时最不必要的能力,但它消除了扼杀动力的导出-导入循环。
无需将 Jira 工单导出为 CSV、上传到 Claude.ai、再将结果复制粘贴回来,Claude Code 可以直接查询 Jira、就地分析,并将结果更新到工单中。整个工作流保持在同一个环境中。第 10 章会详细讨论这点,但目前你只需要知道这是可行的,而且在掌握基础后非常强大。
这五项能力有一个共同模式:它们消除了思考和行动之间的手动交接。Claude.ai 负责思考,你来完成工作。Claude Code 思考并行动,然后把结果展示给你审批。一次性问题用哪个都可以。可重复的 PM 工作流则受益于自主性。
智能体循环是 Claude Code 的实际运行方式。你给它一个目标。它规划一个方案。它执行一步(读取文件、运行命令、生成制品)。它观察结果。它决定是继续迭代还是停止。然后向你汇报。

图 1.3:智能体循环——用于理解 Claude Code 的运行方式。持续循环:接收目标 → 规划方案 → 执行步骤(读取文件、运行命令、生成制品)→ 观察结果 → 决定继续迭代或停止 → 汇报。正是这个循环让 Claude Code 的会话体验与对话不同——你看到的是智能体在逐步解决问题。
正是这个循环让 Claude Code 的会话体验不同于 Claude.ai 的对话。你看着智能体逐步解决一个问题,能看到每一步,并且对关键操作保持否决权。一开始可能会觉得它过于啰嗦("现在我要读取这个文件"),但这能建立信任。你看到它在做什么,然后它才去执行。
对于习惯了要么每一步都需要手动操作、要么像黑箱一样运行的工具的 PM 来说,这种中间状态需要适应。Claude Code 在展示其工作过程的同时完成工作本身。这是一种你保持监督的协作模式。
Claude Code 是一个拥有工作空间访问权限和持久化能力的智能体。它和 Claude.ai 使用同一个模型,但拥有不同的能力:文件操作、shell 命令和上下文保留。这些能力解决的是特定的 PM 问题,因此下一节将提供一个选择正确工具的决策框架。
1.3 何时使用哪个工具的决策方法
在 Claude.ai 和 Claude Code 之间做选择归结为三个问题:这个任务需要读取或写入文件吗?你会再次做这个任务吗?输出需要存放在版本控制中吗?如果任何一个答案是"是",就用 Claude Code。如果三个答案都是"否",就用 Claude.ai。
大多数 PM 都搞反了。他们因为熟悉而默认使用 Claude.ai,然后在需要引用文件或重复工作流时才发现摩擦。从一开始就选对工具能省去后面的迁移成本。
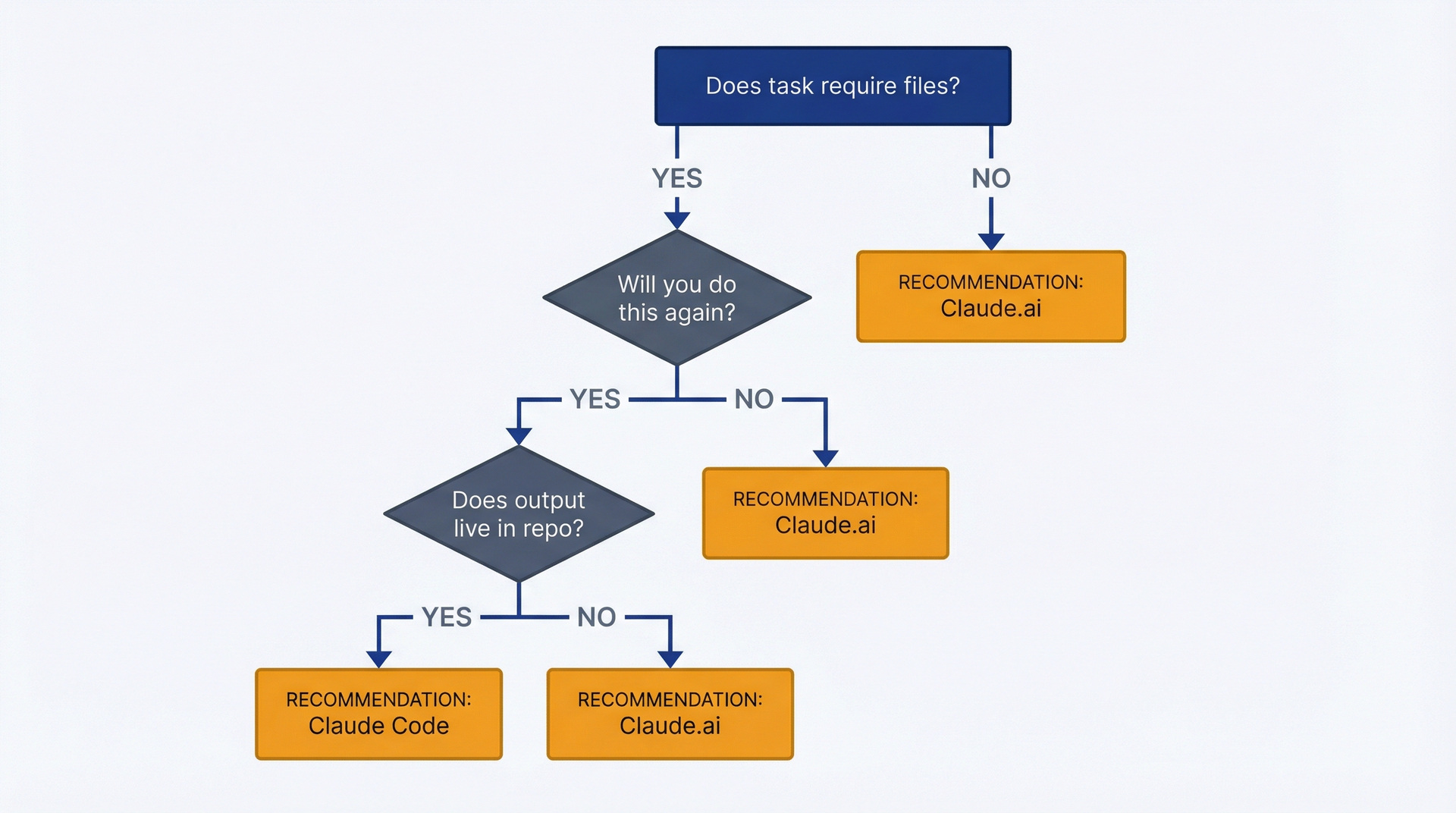
图 1.4:工具选择决策树——用于为每个任务选择合适的工具。三个问题:需要文件吗?会再做一次吗?输出需要版本控制吗?任一答案为"是"→ Claude Code。全部为"否"→ Claude.ai。不确定时默认以只读模式使用 Claude Code。
以下是十二种常见 PM 场景的参考表。收藏本页。
| 任务 | 工具 | 理由 |
|---|---|---|
| 起草利益相关者邮件 | Claude.ai | 一次性对话任务,不需要文件 |
| 利用代码库调查 bug 报告 | Claude Code | 需要读取代码、git 历史记录、生成制品 |
| 头脑风暴功能创意 | Claude.ai | 探索性对话,不需要持久性 |
| 分析客户反馈 CSV | Claude Code | 文件输入、结构化输出、可能重复使用 |
| 从文档中解释技术概念 | Claude.ai | 快速回答,无需文件操作 |
| 从 git 历史生成发布说明 | Claude Code | 需要 git 命令、文件输出、每月可重复 |
| 基于研究笔记撰写 PRD 章节 | Claude.ai | 如果笔记在脑子里用 Claude.ai;如果在文件里用 Claude Code |
| 理解功能 X 是如何实现的 | Claude Code | 需要代码库导航和上下文持久性 |
| 竞品功能对比 | Claude Code | 如果可重复用 Claude Code;一次性用 Claude.ai |
| 综合用户访谈转录文稿 | Claude Code | 多文件输入、结构化输出制品 |
| 审阅并改进 API 文档 | Claude Code | 需要读取仓库中的文档、建议文件编辑 |
| 从零创建用户画像 | Claude.ai | 初始草稿用对话方式;如果是数据驱动的用 Code |
规律:Claude.ai 负责思考,Claude Code 负责执行。需要将输出复制到另一个工具的任务,说明更适合用 Claude Code。
"我会再做一次吗?"这个启发式问题是最快的决策规则。如果你会每周运行这个分析、每月创建这份报告、或者反复调查这类问题,Claude Code 的初始设置成本能立即获得回报。即使第一次运行花费更长时间(学习命令、构建提示词、保存 skill),第二次运行就能快 10 倍。
PM 总是低估重复性。你以为只是在做一份竞品分析,实际上你正在建立一个季度评审流程。你以为只是在写一个用户故事,实际上你正在定义一个将用于后续 50 个故事的模板。如果存在任何重复此任务的可能性,倾向于用 Claude Code,现在就构建可复用工作流。
反过来,如果这确实是一次性的(起草某条特定消息、探索一个模糊概念、获取快速答案),Claude.ai 更快。无需设置,无需学习曲线,问了就走。在目录中启动 Claude Code、授权权限、构建文件输出的开销,只有在你能分摊这些成本时才有意义。
当你真的不确定时,默认以只读模式使用 Claude Code。用 --permission-mode plan 标志启动它,这会阻止任何修改。提出你的问题。如果 Claude Code 的回答涉及"我会读取这些文件并生成这个制品",说明你选对了工具。如果回答纯粹是对话性质的,没有任何文件引用,那你本可以用 Claude.ai。久而久之,这种判断会变得本能。
一个边缘情况:协作工作。如果输出需要由工程团队审阅、存放在仓库中、或融入 CI/CD 流程,那么无论重复性如何,都需要 Claude Code。一份存放在 docs/ 中的调查总结,与它引用的代码并列,比 Slack 消息中的同样内容有价值得多。基于文件的制品能持久存在,链接到具体提交,并与团队工作流集成。对话式输出则会消失。
这个框架帮助你根据任务需求匹配合适的工具能力。两个工具使用同一个模型。区别在于文件访问、命令执行和持久性。大多数 PM 的工作涉及文件、迭代和协作。Claude.ai 优雅地覆盖了 30% 的 PM 用例,而 Claude Code 处理另外 70% 能真正改变你工作方式的用例。
1.4 PM 需要 Claude Code 的三大用例
三类 PM 工作需要 Claude Code 的能力。如果你的任务属于以下任何一类,选择就已经明确。
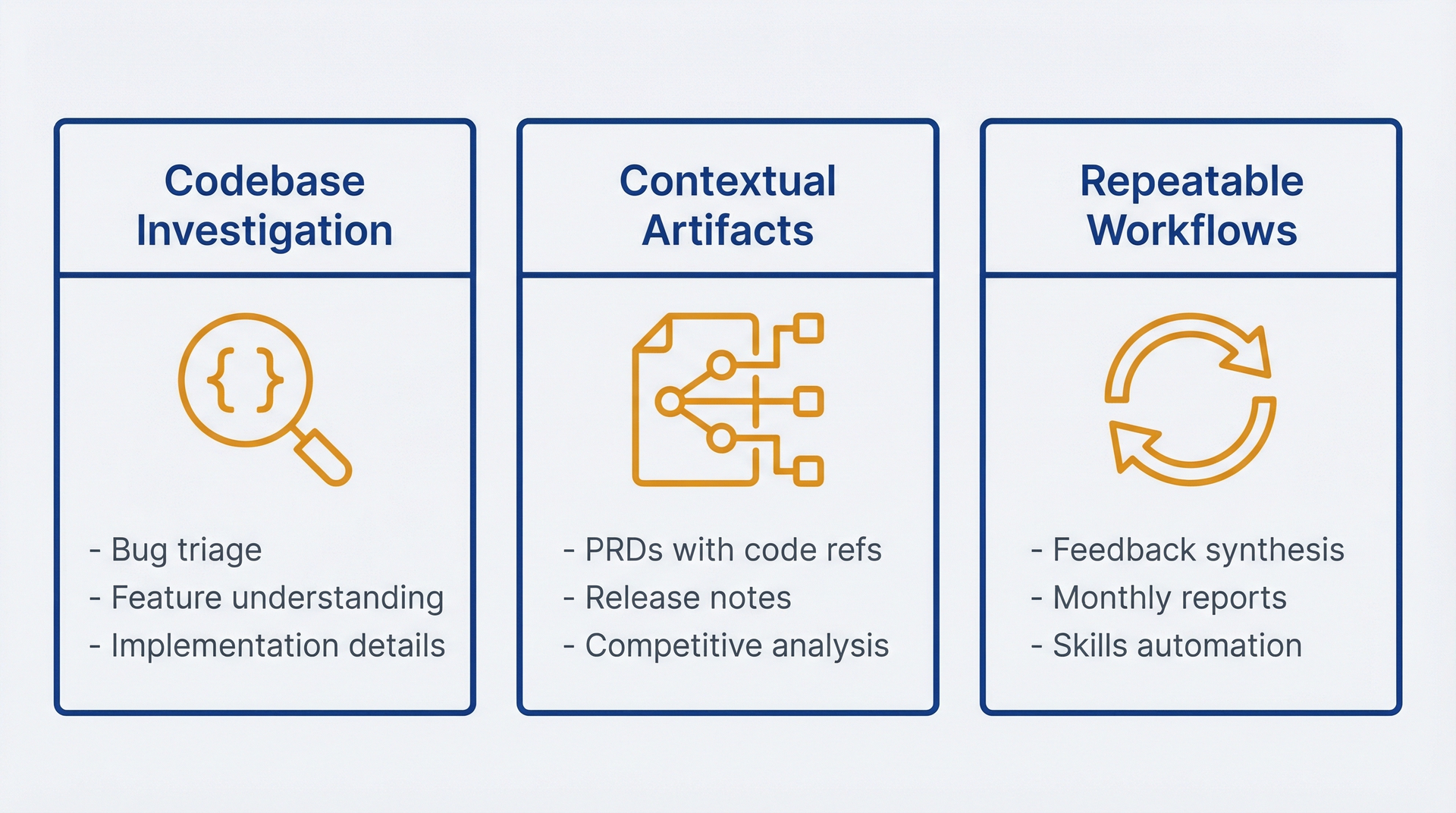
图 1.5:三大 PM 用例——用于识别何时 Claude Code 必不可少。代码库调查(无需亲自阅读代码即可理解实现)、上下文制品生成(引用并与代码同步的文档),以及可重复工作流(编码了 PM 周期性流程的 skill)。如果你的工作涉及以上任何一项,Claude Code 就成为必不可少的基础设施。
代码库调查。你需要理解某些东西的工作原理,但你不会流畅阅读代码,而工程团队有其他优先事项。这是 Claude Code 对 PM 最经典的用例。
一位客户报告说折扣码在不该叠加的时候叠加了。工程团队正全力冲刺季度目标。你需要分类判断:这是真实 bug 还是用户操作失误?如果是真的,有多严重?大概的影响范围是什么?
在仓库中打开 Claude Code。提问:"折扣码验证是如何工作的?请展示在单个订单中可能叠加应用多个折扣的位置。"几分钟内,你就能获得文件引用、用通俗英文解释的函数功能,以及关于这个 bug 的假设。你把包含具体代码位置的调查报告整理出来。工程团队看到报告,确认问题,无需通常的发现阶段即可修复。PM 总耗时:15 分钟。节省的工程时间:一小时调查加上多轮来回沟通澄清。
这种模式不断重复。"认证是如何工作的?""支付失败时会发生什么?""应用在哪里检查订阅状态?"这些问题需要阅读代码、追踪数据流、理解实现细节。Claude Code 通过自然语言查询提供这些能力。
输出存放在 docs/investigations/ 或相关工单旁。当类似问题再次出现时,未来的你会受益。未来加入的团队成员受益于被记录下来的机构知识。调查结果变成了一个制品,而不是一段丢失的对话。
上下文制品生成。你需要创建一份引用你的代码库、引用外部研究、或者需要与代码变更保持同步的文档。文档的价值来自于它与仓库的集成。
例子:一份引用当前 API 能力并链接到相关文件的 PRD。从 git 历史记录和 Jira 工单生成的发布说明,用你的产品风格撰写。竞品分析,每季度以相同结构更新并存放在 research/competitors/ 中。随实现演进而保持更新的文档。
Claude.ai 可以撰写这些文档,但你需要手动提供上下文、手动保存输出,并在发生变化时手动更新。Claude Code 从你的仓库读取信息,通过 MCP 从外部来源拉取数据,就地生成制品,并且能在你需要下次更新时重新运行工作流。
第一次季度竞品分析作为 skill 设置需要 30 分钟。第二次只需要 5 分钟运行。第三、四、五次各只需 5 分钟。你构建了一个生成一致输出的可重复流程,而且制品存放在版本控制中,团队可以看到它的演进。
可重复工作流。你定期做同类任务:每周反馈综合分析、每月发布规划、每季度路线图更新、按功能的用户故事生成。具体输入每次不同,但流程是稳定的。
这就是 skill 发挥作用的地方。skill 是存储在 .claude/skills/ 中的文档化工作流,Claude Code 按需执行。你定义一次流程:所需输入、执行的步骤、输出格式、质量标准。然后你调用它:"对 data/customer-feedback-nov-2024.csv 运行 feedback-synthesis",Claude Code 执行这个工作流。
没有 skill 时,你每次都要重复相同的指令(解释分类方案、输出格式、综合深度)。有了 skill,工作流被编码。你只需关注输入和审查输出。认知负担从"准确记住上个月我是怎么做的"降低为"运行那个东西"。
第 8 章和第 9 章深入介绍了 skill。目前你只需要知道:如果某件事你做超过两次,你就该考虑构建一个 skill。投入的努力在第三次运行时就回收了。
这三大用例——代码库调查、上下文制品生成和可重复工作流——涵盖了 PM 应用 Claude Code 的大部分高价值场景。如果你的工作中不涉及这些,Claude.ai 可能就足够了。如果你的工作三样都涉及,Claude Code 就成为必不可少的基础设施。
1.5 开始之前,了解得失
Claude Code 解决了真实的问题,但它带来的成本和约束是 Claude.ai 可以避免的。
学习曲线。你需要安装它、理解权限模式、学习基本命令,并培养何时使用哪些能力的直觉。这需要数小时的动手练习。网页界面无需安装,开箱即用。对于那些偶尔需要 AI 协助但很少与代码仓库打交道的 PM 来说,切换成本可能超过收益。
预期第一周会感觉效率低下。你会手忙脚乱地操作命令,忘记在想用只读模式时设置了可写模式,然后怀疑这么做是否值得。到第二周,如果你用在正确的任务上,效率提升就会变得显而易见。到第四周,你会抗拒使用 Claude.ai,因为相比之下它显得太受限了。但最开始那几次会话确实会让人不太适应。
成本可见性和预算管理。Claude.ai 采用订阅定价:固定月费,在速率限制内无限使用。Claude Code 采用 API 定价(按消耗的 token 付费)。对于探索性较强的 PM 工作,token 消耗可能难以预测。读取大型代码库、派发多个子智能体、或运行复杂的综合分析任务,可能会以订阅定价掩盖的方式快速消耗你的月度预算。
第 2 章详细介绍了成本管理。简短版:为典型的 PM 使用量预算 $50-150/月,每次会话后用 /cost 监控,成本攀升时用 /compact 减少上下文。如果你对可变成本感到不安或没有预算审批权,尽管有局限性,Claude.ai 的固定定价可能更适合你。
企业部署。许多组织限制 API 访问,要求对具有文件系统访问权限的工具进行安全审查,或禁止连接到外部服务。Claude Code 需要一个 Anthropic API 密钥并以本地文件权限运行。如果你所在组织的安全策略禁止这样做,你就只能使用他们批准的官方工具(很可能只有网页界面)。
这不是 Claude Code 的限制,而是企业 IT 治理的现实。去争取批准使用是有可能的,尤其是你能先在个人项目上证明其价值,但要做好多周审批流程的准备。
何时 Claude.ai 确实更好。快速问题、头脑风暴讨论、你把内容粘贴进去希望获得对话式反馈的草稿审阅、任何尚未定义输出或不需要文件操作的探索性事务。网页界面打开更快,无需为权限操心,可以在任何设备上使用而无需安装。
如果你发现自己在用 Claude Code 处理更适合网页界面的任务,那说明你在优化错误的事情。两个工具的存在是因为它们服务于不同的需求。为每个任务选择合适的工具,而不是把一切强行塞进你偏好的界面。
1.6 双工具思维模型
两个工具,相同的智能,不同的能力。基于任务需求选择,而非基于哪个界面让人更熟悉。
Claude.ai:对话式助手。你说话,它回应。每次对话从头开始。输出保留在对话历史中,除非你手动复制到别处。适合思考问题、获取快速答案、起草不需要与文件或代码仓库集成的内容。零设置成本、零学习曲线、固定订阅定价。
Claude Code:拥有工作空间访问权限的自主智能体。你设定目标;它读取文件、运行命令、生成制品并报告结果。对话建立在 CLAUDE.md 的持久化项目上下文之上。输出写入你的文件系统,经过版本控制,对团队可访问。适合代码库调查、制品生成和可重复工作流。需要安装和学习,可变 API 成本,更高的认知负担。
决策框架:
- 这个任务涉及文件吗?→ Claude Code
- 我会再做一次这个任务吗?→ Claude Code
- 输出需要存放在代码仓库中吗?→ Claude Code
- 这是一次性的对话式任务吗?→ Claude.ai
- 我是在做没有明确输出的头脑风暴吗?→ Claude.ai
大多数 PM 会定期使用两个工具。Claude.ai 用于 30% 的任务,Claude Code 用于 70%。错误在于因为感觉更容易所以对所有事情都用 Claude.ai,然后疑惑为什么 AI 其实并没有改变你的工作流。能带来改变的工作流,是那些制品重要、重复性重要、与你的代码仓库集成重要的工作流。
Claude Code 处理这些。这就是本书存在的原因:向你展示如何识别那些工作流,正确构建它们,并随着时间推移让价值不断叠加。第 2 章涵盖设置和安全性。让我们先让你跑起来。
第2章
设置、安全模式与成本管理
2.1 15 分钟内让 Claude Code 跑起来
你已经决定 Claude Code 能解决你面临的问题。现在你需要在不搞砸任何东西的情况下让它跑起来。本节让你在 15 分钟内从零到能正常工作的会话,假设你有一个终端并且能跟从命令操作。
安装使用各平台特定的命令。选择对应你操作系统的那个:
macOS、Linux 或 WSL:
curl -fsSL https://claude.ai/install.sh | bash
Windows(PowerShell):
irm https://claude.ai/install.ps1 | iex
macOS 使用 Homebrew:
brew install --cask claude-code
任何安装了 Node.js 18+ 的平台:
npm install -g @anthropic-ai/claude-code
推荐使用 curl/irm 方法。它下载一个开箱即用的原生二进制文件。npm 选项需要 Node.js 18 或更高版本,耗时更久但跨平台通用。如果你的组织限制软件安装,你需要先获得 IT 批准才能继续。
安装大约需要两分钟。如果在 macOS 或 Linux 上用 curl 方法看到权限错误,脚本会提示输入密码。Windows PowerShell 可能需要以管理员身份运行。
认证在安装后的 Claude Code 内完成。你有两个选项:
选项 1:Claude 订阅(Pro、Max 或 Team 方案)。启动 Claude Code 后,系统会提示你进行认证,或者你可以使用:
/login
这个斜杠命令会打开浏览器,用你的 Claude 账户凭据进行认证。使用量包含在你的订阅中,没有按 token 计费,也没有意外账单。对大多数 PM 来说这是更简单的选项。
选项 2:Anthropic API,按使用量计费。如果你没有 Claude 订阅,请在 console.anthropic.com/settings/keys 获取 API 密钥。创建一个密钥,立即复制(你不会再见到它),然后设置为环境变量。关于如何永久设置环境变量,请查阅你的操作系统文档。
严重警告:如果你设置了 ANTHROPIC_API_KEY 环境变量,Claude Code 会自动使用它进行 API 计费(按量付费),并忽略你的订阅,即使你有 Pro 或 Max 方案也如此。你将被按照 API 费率计费,而不是使用你的订阅。如果你在用订阅,请确保这个环境变量没有被设置。使用 /status 验证当前激活的认证方式。
认证信息存储在本地你的用户目录配置中。绝不要将 API 密钥提交到版本控制或分享给团队成员。每个人都需要自己的认证,以便使用量追踪和账单清晰。
验证安装:导航到任意目录并运行:
claude doctor
这会检查你的安装,显示版本号,并确认所有配置正确。如果看到"command not found",说明安装失败。尝试重新安装,或者检查安装目录是否在你的 PATH 中。
常见安装失败原因:
网络限制。公司防火墙有时会阻止从 claude.ai 或 npm 源下载。如果安装卡住或因网络错误失败,你可能需要配置组织的代理或请求例外。IT 通常能在一天内解决,只要你提供了安装 URL。
权限被拒绝。在 macOS 和 Linux 上,curl 安装脚本可能需要提升权限才能在系统目录中安装二进制文件。脚本会提示输入密码。如果使用 npm,可能需要 sudo npm install -g @anthropic-ai/claude-code 进行全局安装。
Windows 执行策略。PowerShell 可能因执行策略限制而阻止安装脚本。如果遇到此错误,请在安装命令之前运行 Set-ExecutionPolicy RemoteSigned -Scope CurrentUser,或请 IT 调整策略。
Node.js 版本不匹配。如果使用 npm 安装方式,Claude Code 需要 Node.js 18 或更高版本。用 node --version 检查。如果你有旧版本,请先用版本管理器(macOS/Linux 用 nvm,Windows 用 nvm-windows)更新 Node.js。
认证失败。如果 /login 打开了浏览器但认证失败,请检查你是否有活跃的 Claude Pro、Max 或 Team 订阅。如果使用 API 密钥,请验证你复制了完整的密钥,没有多余空格或换行符。必要时重新生成,旧密钥不会自动过期。
配置使用三层级设置系统:
- 全局:~/.claude/settings.json(适用于所有项目)
- 项目:.claude/settings.json(团队共享,提交到 git)
- 本地:.claude/settings.local.json(个人覆盖,由 gitignore 忽略)
刚入门时你很少需要直接编辑这些文件,但了解结构对后续有帮助。这些文件存储认证信息、默认权限模式和其他偏好设置。
要设置默认权限模式(推荐 PM 使用),创建 ~/.claude/settings.json,内容为:
{ "defaultMode": "plan"}
这会让每个会话都以只读模式启动,直到你手动覆盖,是学习期间的安全默认值。第 2.3 节解释了为什么这很重要。
安装到此完成。你已经安装了 Claude Code,完成了认证,并做好了配置。如果你遇到这些常见问题之外的其他困难,请查看 code.claude.com/docs 获取故障排除指南。大多数 PM 都能顺利完成安装。最耗时的地方通常是等待 IT 审批,而不是技术困难本身。
2.2 运行你的第一次调查
打开终端并导航到你正在使用的任意 git 仓库。这可以是你的产品主仓库、文档仓库,甚至是个人项目。Claude Code 在任何有文件的目录中都能工作,但在你需要理解的代码仓库中最有用。
cd /path/to/your/repository
claude
会话启动。你会看到欢迎信息、关于 Claude Code 可以访问什么的信息(当前目录及其子目录),以及等待输入的提示符。
会话界面刻意设计得很简洁。包含三个要素:
- 提示符:一个 > 符号,你可以在此输入自然语言请求。无需特殊语法。就像在给一个能读取文件和运行命令的同事发消息一样写就行。
- 输出和状态指示:Claude Code 会显示它正在做什么。"正在读取文件 X。" "正在运行命令 Y。" "正在生成制品 Z。" 一开始会觉得这些信息过于啰嗦(你知道自己问的是什么),但这能建立信任。你在每个操作发生之前看到它,当操作会修改文件时这一点很重要。
- Token 用量指示:每次回复后,你会看到消耗的 token 数和大概成本。这是你的预算感知反馈循环。在第一次会话时忽略它;到第三次会话时开始关注,此时你已经了解什么因素驱动成本。
理解 Claude Code 启动时能看到什么:你当前目录中的每个文件和子目录。如果你在仓库中的话还有 git 历史记录。任何 CLAUDE.md 文件提供持久化上下文。它被允许访问的环境变量。它不会自动读取每个文件(那会消耗海量 token),但它可以读取你引用的或它判断与你的请求相关的任何文件。
试试这个第一个请求:
这个仓库是做什么的?用三句话概括它的功能。
Claude Code 会读取像 README.md、package.json 或类似的元数据文件,然后给出总结。回复会显示它查看过哪些文件。这让你学到这个模式:你提问,它决定要读什么,它展示读了什么,然后它回答。
你需要立即掌握的基本命令:
/help:显示可用命令。你不会全部记住,但第一周你会经常参考这个列表。
/status:显示当前会话状态,包括权限模式、已修改的文件、已消耗的 token 数和预估成本。
/exit:结束会话。对话历史会保存在本地供查阅,但上下文不会延续到下一个会话,除非你创建了 CLAUDE.md 文件。
试试第二个请求:
显示这个仓库中最近修改过的五个文件。
Claude Code 运行 git 或文件系统命令,显示结果,并解释它找到了什么。你正在看到 shell 命令访问能力在行动:你通过自然语言拥有的能力,无需知道确切的命令语法。
你的第一次会话应该持续大约五分钟。就你所在的仓库问两到三个探索性问题。用 /status 查看 token 消耗。用 /exit 退出。就这样。你已经确认安装成功并体验了核心交互模式。
下一次会话会感觉不再那么陌生。到第三次会话时,你会停止关注界面而专注于工作本身。基本使用方式的学习曲线以小时计而非以天计,前提是你在用那些在产品层面已经理解的代码仓库进行操作。
2.3 控制 Claude Code 能做什么
Claude Code 可以修改文件、运行任意 shell 命令,如果你要求的话,还能删除东西。这种能力在你还不熟悉的时候需要防护栏。
四种权限模式控制 Claude Code 能自主执行哪些操作。作为 PM,你主要使用其中三种。
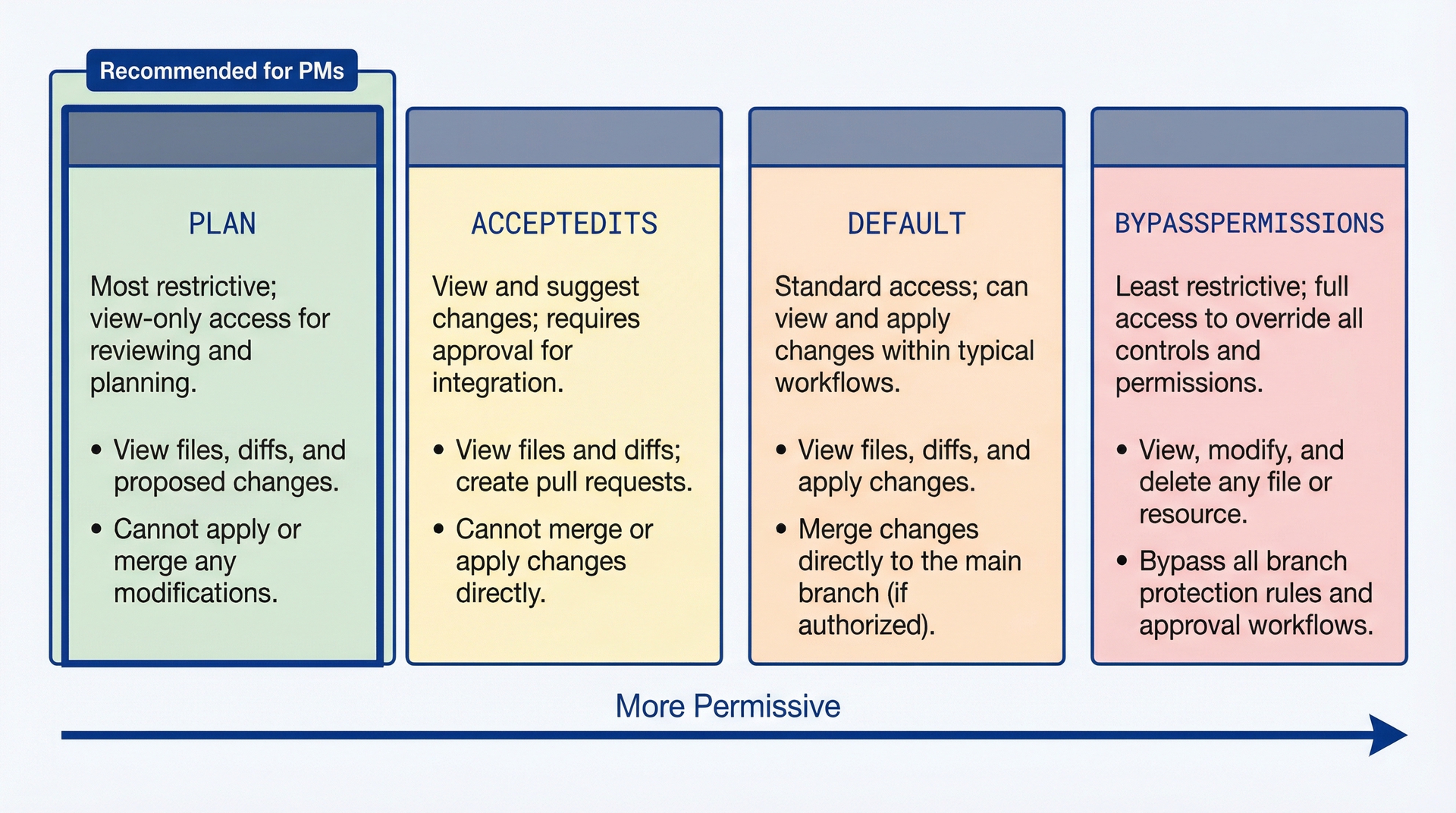
权限模式图谱,展示从最严格(plan)到最宽松(bypassPermissions)的四个级别。plan 模式:读取文件、运行只读命令。acceptEdits 模式:额外允许文件修改。default 模式:额外允许带提示的 shell 命令。bypassPermissions 模式:完全自主,无需提示。
上图展示了权限层级。每种模式包含其上所有模式的能力,外加额外权限:
plan 模式(只读分析):Claude Code 可以读取文件、运行只读命令如 git log 或 ls,并回答问题。它不能修改文件、安装依赖、运行测试或执行改变状态的命令。这是推荐你作为 PM 使用的默认模式,直到你有修改文件的具体需求。
使用场景:调查代码库、分析数据、理解实现、分类 bug。90% 的 PM 工作都属于这个范畴。
acceptEdits 模式(自动批准文件修改):Claude Code 可以读取文件并修改它们,无需每次编辑都提示。在运行 shell 命令前仍会提示。当你信任 Claude Code 进行文件变更但希望在命令执行时保持监督时,此模式效率较高。
使用场景:生成发布说明、创建 PRD 文档、更新 CLAUDE.md、构建 skill。这些任务需要文件输出但不涉及运行构建或测试。
default 模式(所有操作都提示):Claude Code 在修改文件或运行命令前会提示获取权限。这提供了最大控制(你批准每个操作),代价是更多中断。
使用场景:正在学习 Claude Code、希望看到每个操作发生之前的样子,或处理敏感变更时希望获得明确批准。
bypassPermissions 模式(完全自主):Claude Code 可以不需提示地执行任何你能在终端做的操作。运行测试、安装软件包、启动服务器、git 提交、推送到远程仓库。此模式功能强大但风险也大。
使用场景:作为 PM 很少使用。主要用例是与工程师协作测试或调试问题时,需要完全系统访问权限并且完全信任 Claude Code 的情况下。大多数 PM 工作流永远不需要此模式。启动时需要使用 --dangerously-skip-permissions 标志来启用。这是故意设计成难以开启的。
设置权限模式有几种方式:
- settings.json 中的默认值(第 2.1 节)适用于所有会话
- 会话期间按 Shift+Tab 在三种常用模式间循环:default → acceptEdits → plan
- 启动时的命令行标志:claude --permission-mode plan
进入会话后,Shift+Tab 循环是最快的方式。如果你以 default 模式启动,后来意识到你只是想调查而不想冒被修改的风险,按两次 Shift+Tab 就切换到 plan 模式。注意,bypassPermissions 模式不能通过 Shift+Tab 启用。你必须使用 --dangerously-skip-permissions 标志来启动,这本身就是一种安全机制。
用于安全探索的 plan 模式是你的辅助轮。如果你将它配置为默认值(第 2.1 节),每个会话都以安全方式启动。你随时可以按 Shift+Tab 切换到更宽松的模式,如果发现需要文件修改能力的话。操作一旦完成,你无法撤销已完成的文件修改或已执行的命令。
具体场景:你正在调查一个 bug,要求 Claude Code 向你展示认证是如何工作的。在 plan 模式下,它读取相关文件并解释。完美——你得到了需要的东西。在 bypassPermissions 模式下,如果你的请求措辞含糊,Claude Code 可能会尝试运行认证流程,这可能会访问外部服务或修改数据。这在明确的请求下不太可能发生,但 plan 模式完全消除了这种可能性。
作为 PM 何时使用每种模式:
| 你的任务 | 模式 | 原因 |
|---|---|---|
| 理解功能 X 的工作原理 | plan | 只读调查 |
| 分类 bug 报告 | plan | 仅读取代码和 git 历史 |
| 生成发布说明文档 | acceptEdits | 需要写入文件输出 |
| 在 .claude/skills/ 中创建新 skill | acceptEdits | 编写 skill 配置文件 |
| 分析客户反馈 CSV | plan | 读取数据、回答问题,无需文件输出 |
| 用新上下文更新 CLAUDE.md | acceptEdits | 修改仓库文件 |
| 运行测试以复现 bug | default 或 acceptEdits | 执行测试命令需要批准 |
| 调查数据库 schema | plan | 只读,除非需要运行数据迁移 |
在配置中设置默认模式已在 2.1 节介绍过,但值得重复:在 ~/.claude/settings.json 中添加 "defaultMode": "plan",让每个会话都以安全方式启动。当需要文件修改或命令执行时,你随时可以按 Shift+Tab 切换到更宽松的模式。默认使用最严格的模式能防止事故。
"事故"长什么样:你在 bypassPermissions 模式下要求 Claude Code "修复 README 中的拼写错误"。它读取 README.md,找到拼写错误,纠正它,然后(因为你没有另外说明)创建一个自动生成消息的 git 提交并推送到当前分支。这可能有帮助,但也可能违反你团队的提交约定,需要用强制推送来撤销。在 acceptEdits 模式下,它只会在文件中修正拼写错误然后停止,让你在提交前审阅。
这些模式的存在是因为 Claude Code 足够强大,可能在使用不慎时导致问题。作为 PM,你很少接近它能做的事情的边缘地带,所以严格的默认设置在让你安全学习。
一个澄清:"安全"的意思是"不会意外地修改东西"。Claude Code 在任何模式下都会基于它读取的内容准确回答问题,但无法保证它的理解是正确的。如果你问"认证是如何工作的?"而它误解了代码流程,给了你错误信息,这不是安全问题——这是准确性的问题。权限模式防止的是意外操作,而不是错误答案。第 3.6 节讨论了代码库调查的局限性。
2.4 理解你在为什么付费
每次使用 Claude Code 都要花钱,但付费方式取决于你的认证方式。如果你使用的是 Claude 订阅(Pro、Max 或 Team),使用量已包含在内,你可以忽略本节大部分内容。如果你是通过 API 按使用量计费,请仔细阅读。
对于 Claude 订阅用户:你的使用量已包含在你的月费中。没有按 token 收费,没有意外账单,也不需要刻意跟踪成本。/cost 命令(第 2.5 节)仍然会显示 token 消耗供你参考,但不会转化为额外费用。跳到第 2.5 节。
对于 API 用户:Claude 读取或写入的一切都计入你的 token 预算。输入 token 是你发送的文本(你的提示词和 Claude 为回答而读取的任何文件)。输出 token 是 Claude 生成的文本(回复、写入的文件内容、解释)。Anthropic 的 API 定价大约是每百万输入 token $3,每百万输出 token $15(针对 Claude Sonnet 标准模型)。Opus 更贵,Haiku 更便宜,但 Sonnet 是 Claude Code 的默认模型,能很好地处理 PM 任务。
将 token 转换为实际使用量:一个 token 大约相当于四分之三个英文单词。一篇 500 词的文档大约 650 token。一个典型的代码库文件根据长度可能在 200-2,000 token。你要求 Claude Code 调查某件事的提示词约 50-200 token。回复约 200-1,000 token。
算一算:要求 Claude Code 读取五个文件(5,000 token 输入)并提供总结(500 token 输出)大约花费 $0.02。要求它读取五十个文件并生成一份全面报告大约花费 $0.50。一次深度调查会话,你在几十个文件中多次迭代,可能总共消耗 200,000 token,花费 $1-2。
上下文窗口:它是什么,为什么重要。每个活跃的 Claude Code 会话维护一个上下文窗口:对话的运行历史、所有已读文件和所有已生成的输出。这个上下文就是 Claude Code "记住"你之前在会话中讨论了什么的方式。上下文窗口有大小限制(出版时 Claude Sonnet 为 200,000 token,但这个限制会定期提高)。
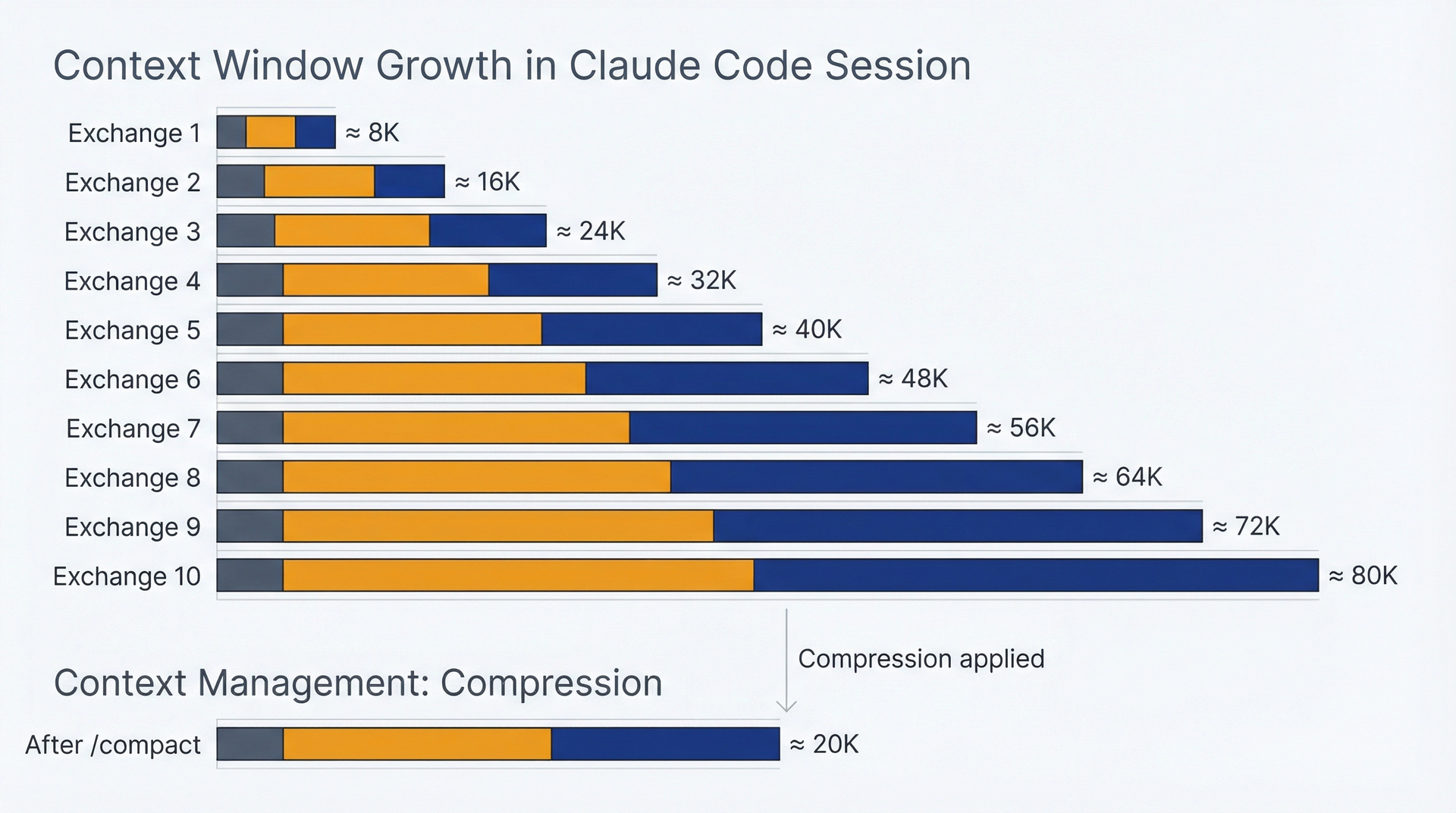
会话中上下文窗口的增长。显示一个柱状图,每次对话交换都增加上下文:初始提示词(少量)、文件读取(中等)、回复(中等)、追问(累积)。到第 10 次交换时,上下文已显著增长。第二组柱子显示了 /compact 的效果,将累积的上下文缩减为压缩摘要。
该图说明了为什么长会话会变贵。每次交换都会增加上下文,而每条新消息都必须处理整个累积的历史记录。十次交换后,你提出每个新问题都要重新读取之前的所有内容。
对于 PM 来说,这体现为两个现实约束:
- 长会话会变贵。你发送的每条消息和 Claude 生成的每条回复都留在上下文中。二十次交换后,你可能已有 50,000 token 的上下文。每条新提示词在回复前都要读取整个上下文,所以你每次请求都在为重新处理先前的对话历史付费。这会悄然累积。
- 会话可能超出上下文窗口。如果你调查一个大型代码库、要求 Claude Code 读取大量文件并大量迭代,你最终会达到上下文限制。Claude Code 会发出警告,可以使用 /compact 来总结和减少上下文,但要知道极长的会话需要管理。
每种任务类型大约的成本:
| 任务 | Token 数 | 成本 | 时长 |
|---|---|---|---|
| 关于某文件的快速问题 | 2,000 - 5,000 | $0.01 - $0.02 | 1 分钟 |
| 功能调查(X 是如何工作的?) | 20,000 - 50,000 | $0.10 - $0.25 | 5-10 分钟 |
| 结合代码库分析的 bug 分类 | 30,000 - 100,000 | $0.15 - $0.50 | 10-20 分钟 |
| 从 git 历史生成发布说明 | 40,000 - 80,000 | $0.20 - $0.40 | 5-10 分钟 |
| 综合客户反馈 CSV | 50,000 - 150,000 | $0.25 - $0.75 | 10-15 分钟 |
| 构建新 skill 并迭代 | 60,000 - 120,000 | $0.30 - $0.60 | 15-30 分钟 |
| 深度代码库探索会话 | 100,000 - 300,000 | $0.50 - $1.50 | 30-60 分钟 |
这些是估算。你的实际消耗取决于代码库大小、问题复杂度和迭代深度。在头几次会话后使用 /cost(第 2.5 节)来校准你的直觉。
为什么 PM 比工程师消耗 token 更快。工程师知道自己在找什么。他们问有针对性的问题:"显示 user.authenticate() 的实现。"他们得到答案,凭此行动,然后退出。总 token 数:10,000。成本:$0.05。
PM 是在探索。你不知道哪个文件包含相关逻辑。你问宽泛的问题:"这个应用的认证是如何工作的?"Claude Code 读取多个文件来构建完整图景。你追问以澄清边界情况。你反复推敲解释直到你理解了。总 token 数:80,000。成本:$0.40。
这不是低效,这是 PM 调查的性质使然。你从零开始构建理解,而工程师是在已有知识上增强。请为探索成本做好预算。另一个选择是反复打断工程师,这在团队生产力方面也有它自己的成本。
典型 PM 使用模式的月度预算(仅限 API 用户):
来自 Claude Code 用户的真实数据展示了典型支出:- 平均使用量:每日活跃用户约 $100-200/月 - 轻度使用(5-10 次/月,多为快速问题):$10-30 - 中度使用(15-25 次/月,调查和生成混合):$50-100 - 重度使用(每日会话,深度调查,skill 构建):$100-200 - 高强度使用(每日多次会话,大量代码库工作):$200-400
如果你作为 PM 每月花费超过 $400,要么你在处理海量代码库,要么你在不必要地运行过长会话,要么你在用 Claude Code 处理更适合其他工具的任务。第 2.5 节介绍成本管理策略。
成本在你看到 Anthropic 账单之前都是抽象的。开始时预算 $100/月,并通过 /cost 监控实际使用量。根据交付的价值上下调整。如果 Claude Code 一个月帮你节省了五小时工作,$100 与你完全负担的时薪相比只是零头。如果你花了 $100 却获得的价值微乎其微,说明你用错了,很可能是在用 Claude Code 做 Claude.ai 处理得更好的任务。
对于订阅用户:你的成本固定在订阅费用上(出版时 $20/月的 Pro 或 $40/月的 Max)。token 消耗数据在了解会话效率方面有意义,但不影响你的账单。
无论你是按 token 付费还是使用订阅,token 意识都很重要。订阅用户同样受益于高效的会话:更短的对话意味着更快获得答案和更少的上下文需要管理。API 用户则有直接成本控制的额外激励。无论哪种方式,你都会学会提出更好的问题,在得到所需内容后退出会话,而不是在提供边际收益递减的对话中绕来绕去。
2.5 追踪和控制支出
Claude Code 提供三个命令让你在会话内监控和控制支出。养成使用习惯,直到成本意识变得自然而然。
/cost:查看当前会话花费。随时运行此命令可以看到已消耗的 token(输入和输出分别列出)、当前会话成本预估,以及上下文窗口使用情况。这是你的预算仪表盘。
对于订阅用户,显示的金额是如果按 API 费率该会话的预估成本。这对于了解会话效率有帮助,尽管你不是按 token 付费。对于 API 用户,这些是实际收费。
在每次会话的前几个问题后用 /cost 建立基准。在问那些你知道会很贵的事情之前——比如读取五十个文件做全面分析——再用一次。在会话结束时用它来培养对不同工作类型开销的直觉。
输出会显示 token 计数和预估成本:
会话成本:
输入 token:45,230 ($0.14)
输出 token:12,100 ($0.18)
总计:$0.32
对于 API 用户:这精确地告诉你花了多少。如果你进入会话十分钟就已经 $2 了,那就有什么不对。要么是你在调查海量代码库、迭代过度,要么是在问需要读取远超必要的上下文的问题。调整你的方法,或者在价值足以证明合理的情况下接受这个成本。
对于订阅用户:这告诉你会话效率。高 token 计数意味着更长的会话和更多需要管理的上下文,这会影响响应速度,即使不影响你的账单。
/compact:压缩上下文以减少 token。当会话成本攀升(或上下文变得难以驾驭)而你需要继续工作时,/compact 触发 Claude Code 总结到目前为止的对话历史和已读文件内容,用压缩版替换完整上下文。这减少了上下文窗口大小,降低了后续消息的 token 成本。
你可以选择性地指定要保留的内容:/compact 重点关注保留认证实现细节会告诉 Claude Code 在摘要中什么最重要。
具体来说:你花了 30 分钟调查一个复杂功能,积累了 80,000 token 的上下文。每个新问题现在都要处理整个上下文。对于 API 用户,即使简单请求也可能花费 $0.25。对于订阅用户,这意味着响应更慢。运行 /compact,Claude Code 将上下文压缩到 20,000 token,保留关键信息并去除冗余。后续问题更快更便宜。
何时使用 /compact:
- 会话成本超过了你对该任务的预算
- 你在会话内切换话题,不需要之前的上下文
- 你想继续工作但降低每条消息的成本
- /cost 显示上下文大小接近窗口限制
权衡:压缩会丢失细节。如果你压缩了广泛的调查笔记,之后又问了一个需要那些细节的问题,Claude Code 就不会有了。你可能需要重新读取文件,这又要消耗 token。在你完成了一个工作阶段转向另一个阶段时使用 /compact,而不是在迭代调查的中途。
/clear:在不丢失所学的情况下全新开始。此命令结束当前会话并在同一目录中开始一个新会话,此前对话的上下文全部归零。与 /exit 后重新启动不同,/clear 更快,并且让你保持相同的工作状态。
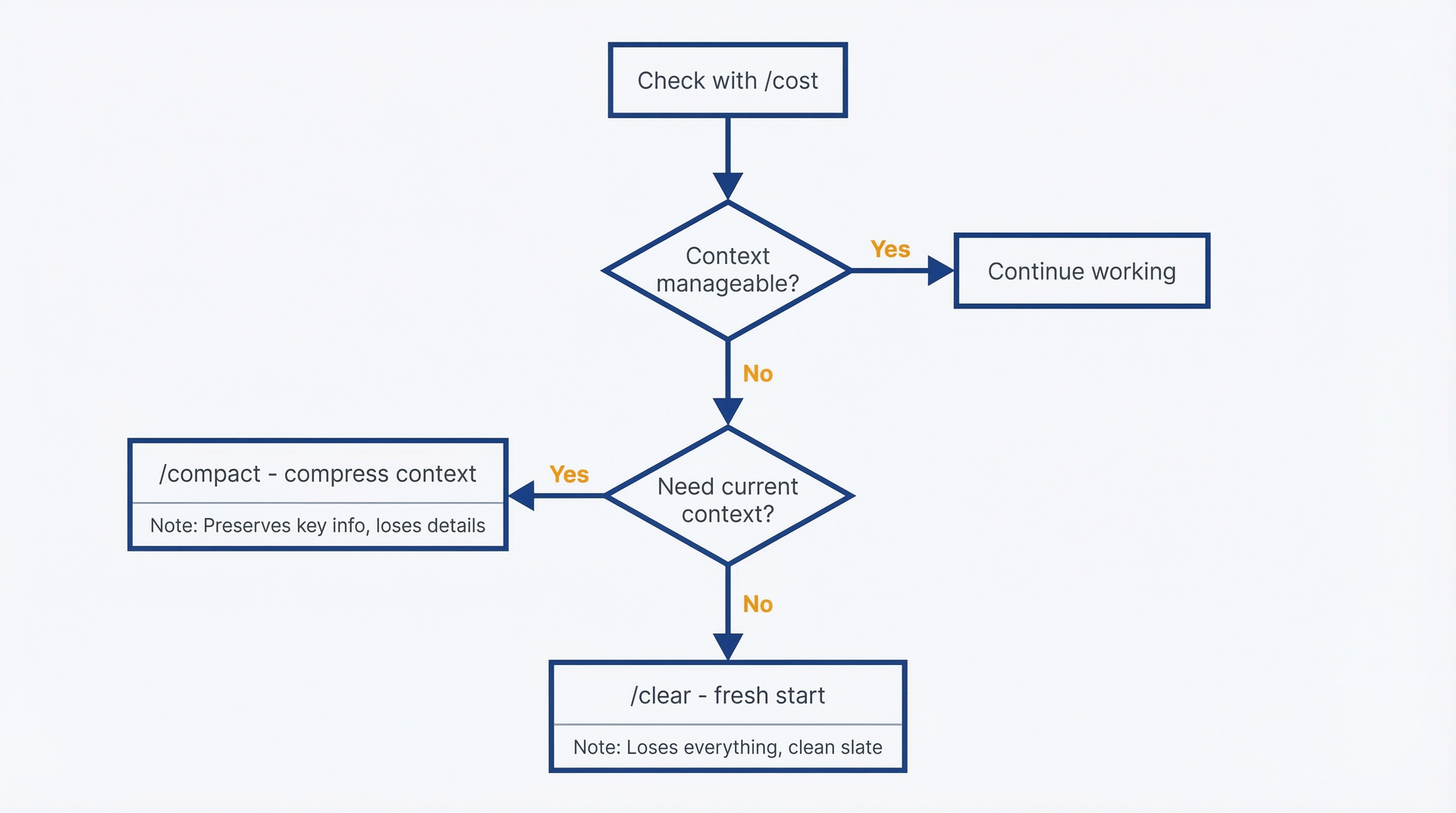
成本命令决策流程图。开始:用 /cost 检查会话状态。如果上下文可管理且成本可接受,继续工作。如果成本高但需要继续同一主题,用 /compact 压缩。如果切换到不相关的任务或上下文过于臃肿,用 /clear 全新开始。展示权衡:/compact 保留关键上下文但丢失细节;/clear 丢失一切但获得干净状态。
使用 /clear 的时机:
- 你完成了一个任务,想开始另一个不相关的任务
- 会话成本很高且 /compact 不够用
- 你走进了一条低效路径,想要一张白纸
- 先前讨论的上下文正在干扰当前回复
权衡:你丢失了所有对话历史。如果你没有把输出保存到文件中,那些输出就没了。在运行 /clear 之前,确保会话中有价值的信息已被捕获到文件或笔记中。
设置支出提醒和限制(API 用户):Claude Code 没有内置的支出提醒,但你可以通过 console.anthropic.com 上的 Anthropic 账户仪表盘监控使用量。在那里设置账单提醒,在月度支出超过你定义的阈值时通知你:$100、$200、$300,任何适合你预算的金额。
第一个月每周检查你的仪表盘来校准预期。大多数 PM 在调查大型代码库或频繁使用时会对使用量累积如此之快感到惊讶。这都在预期之内。目标是有意识地在高价值工作上花钱,而不是以牺牲生产力为代价来最小化成本。
月度预算工作流(API 用户):
- 基于预期使用量决定你的月度预算(第 2.4 节的指导)
- 在 Anthropic 仪表盘中设置预算 80% 的账单提醒
- 每次会话后用 /cost 追踪每日消耗
- 第一个月每周审查实际与预算的对比
- 根据交付的价值调整预算或使用模式
如果你每月一致地碰到预算上限,要么增加预算(如果价值足以证明),要么减少会话频率和范围。如果你只花了预算的 30%,要么你过于保守,要么高估了自己的需求。考虑更主动地使用 Claude Code。
订阅用户:你的成本是固定的。用 /cost 了解会话效率,但不必担心显示的金额。它们是估算,不是收费。
成本管理的关键在于有意识而非最小化。对于 API 用户,每月花 $200 在能节省你 10 小时工作的工具上,ROI 是惊人的。对于订阅用户,你的 $20-40/月已经花了,所以积极使用 Claude Code 从中获取价值。使用这些命令来保持意识、就会话范围做出明智决策,并且(对于 API 用户)避免账单冲击。第一个月之后,成本管理会变成自然而然的习惯。你会直觉地知道哪些任务消耗 token,以及这种效率是否证明了方法的合理性。
你已经安装了 Claude Code,了解如何运行安全的会话,也知道如何监控成本。第 3 章将向你展示如何将这些能力用于代码库调查:这是对 PM 价值最高的用例,也是能改变你与工程团队协作方式的技能。
第3章
理解你的产品实现
3.1 PM的代码库困境
你拥有这个产品,但你看不懂代码。这会形成一个拖慢一切的依赖循环。某位客户反馈你的定价计算器出现了令人困惑的行为,而工程团队正处于冲刺中期。你需要答案——这到底是个bug还是符合设计预期?如果是bug,严重程度如何?修复复杂度有多高?你自己回答不了这些问题,只能去打断工程团队。他们切换上下文、调查问题、然后汇报。他们花两小时,你要等两天。这个bug就这样躺在triage里。
工程团队不应该是你了解自己所负责代码库的唯一途径。你不需要流利地阅读代码,但你需要能够提出问题并获得准确答案,同时不打断别人的冲刺进度。这正是Claude Code所提供的。
工程师上下文切换带来的延迟成本十分高昂,高到不会直接体现在冲刺面板上。每个"快速问题"加上上下文切换的成本后,实际上是一个15分钟的中断。每天五个问题,就等于一小时工程时间加上你自己的等待时间。一个季度下来,你会在那些本可以自己回答的问题上浪费数周的生产力。
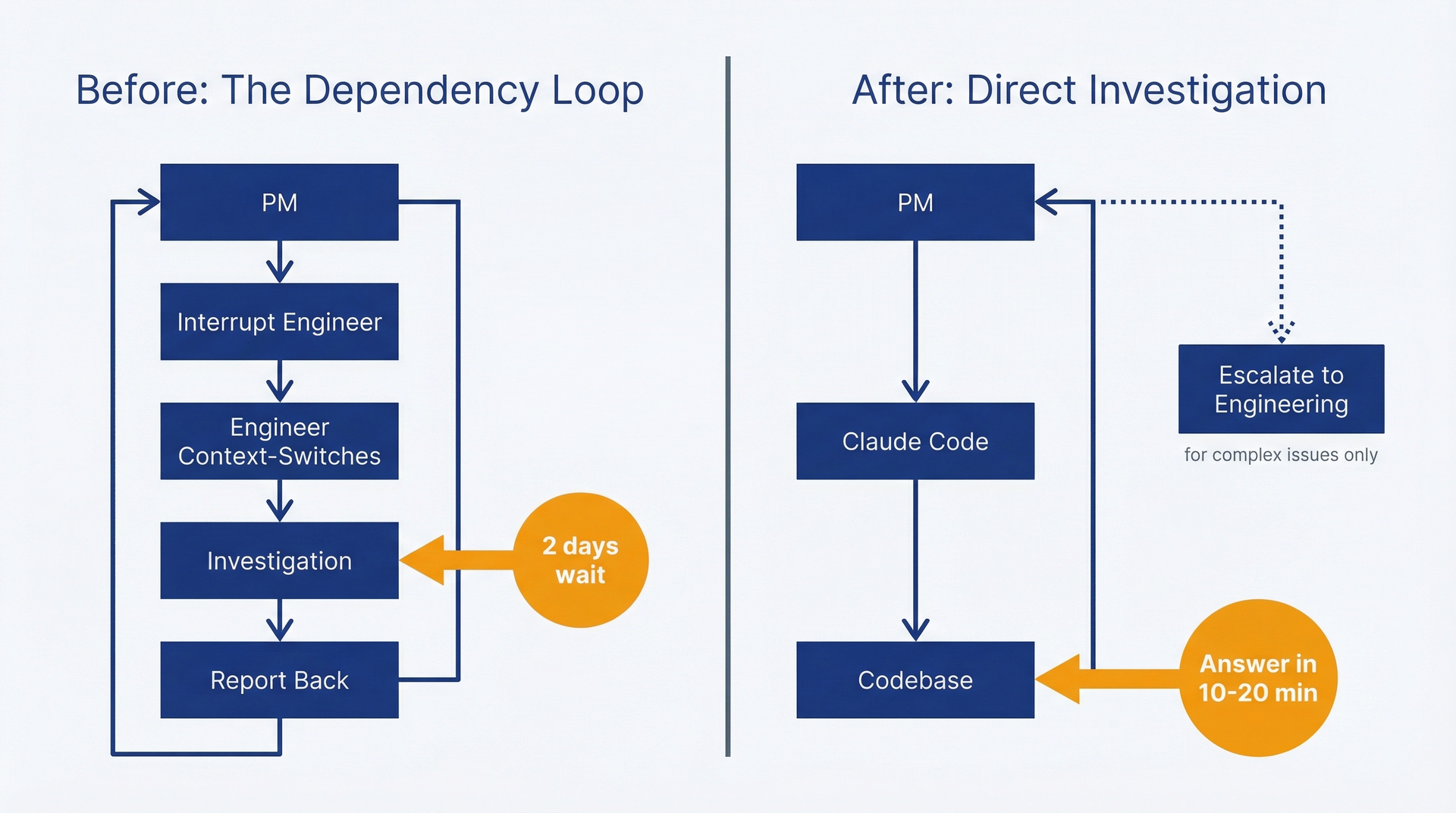
图 3.1:调查工作流对比——用于理解直接进行代码库调查相对于传统工程依赖循环所节省的时间。左侧显示旧的工作流需要两天时间,且涉及多次上下文切换。右侧显示通过Claude Code由PM直接进行调查只需10-20分钟。
替代方案不是去学编程。替代方案是通过一个能把实现翻译成产品语言的agent来直接向代码库提问。复杂问题仍然要向上反馈给工程团队,但第一轮调查由你自己完成。本章将教你如何做到这一点。
3.2 构建你的代码库心智地图
在深入调查具体功能之前,花20分钟了解代码库是如何组织的。这是你的地图。没有它,每一次调查都从零开始。有了它,你就知道该去哪里找,知道该问什么问题。
当你首次在某个新仓库中使用Claude Code时,运行一次这个会话。每季度更新一次,或者在重大架构变更时更新。输出结果会成为一份参考文档,为之后的每一次调查节省时间。
在仓库根目录下以plan模式启动Claude Code:
cd /path/to/your/repositoryclaude --permission-mode plan
Plan模式在这里至关重要(你是在学习,不是在修改)。使用以下prompt:
Prompt:架构总览
向一位产品经理解释这个代码库的架构。涵盖以下内容:
- 主要组件有哪些,各自负责什么
- 数据如何在系统中流动
- 面向用户的功能通常位于何处
- 前端与后端如何连接(如适用)
- 我应该了解的关键抽象或模式
保持非技术性的解释。重点关注那些能帮助我在调查功能时导航代码库的心智模型。
Claude Code会读取关键文件(通常是README.md、包配置文件、目录结构以及一些核心模块的采样),然后提供一个摘要。回复需要5-10分钟,对于典型仓库的成本约为$0.10-0.25。
在输出中可以预期获得以下内容:
组件分解。"前端是位于src/client/中的一个React应用,处理所有用户界面。后端是位于src/server/中的一个Express API,管理业务逻辑和数据库访问。src/shared/目录包含两端共用的代码。"
数据流说明。"当用户提交表单时,React组件会向/api/endpoint发送请求,该请求被路由到src/server/controllers/中的一个控制器,调用src/server/services/中的一个服务来处理业务逻辑,并通过src/server/models/中的模型查询数据库。"
功能定位模式。"面向用户的功能通常实现为src/client/components/中的React组件,对应src/server/routes/中的API端点,以及src/server/services/中的业务逻辑。"
关键抽象。"代码库使用了repository模式:数据库访问通过src/server/repositories/中的repository类进行,而非直接执行查询。身份认证使用JWT令牌,由src/server/middleware/auth.js中的中间件验证。"
这不是一份面面俱到的文档,而是一份入门导向。你在逐步建立关于事物所在位置以及它们如何协作的直觉。当你之后调查"结账流程是如何运作的"这类问题时,你自然会知道去查看客户端组件、服务端路由以及支付服务的集成。
保存输出以供将来参考。将回复内容复制到一个文件中,例如docs/architecture-overview.md,或将其添加到你的CLAUDE.md中(参见3.5节)。这将成为你的快速参考指南。三个月后需要重温记忆时,直接阅读这份文档即可,无需重新运行会话。
有价值的跟进问题:
在获得初始概览之后,针对与你产品领域相关的部分提出澄清性问题:
用户认证在哪里处理?如何确定已登录用户可以访问什么内容?
支付是如何处理的?我们集成了哪些第三方服务?
定价逻辑在哪里实现?是在前端、后端,还是两者兼备?
这些问题再多花5-10分钟和$0.10-0.20,但它们能为你填充与产品相关的具体细节。相比于知道关键业务逻辑在哪里,通用的架构信息重要性要低得多。
什么时候这个会话不太够用:小型仓库(50个文件以下)、结构清晰的,不需要这样做。你可以在调查过程中逐步了解布局。超大型单体应用(数千个文件)则需要多次聚焦的会话,而不是一个总览就能解决的。你需要分别理解特定的子系统。
这种对齐会话是你的基础。当你第一次调查某个功能时,由于已经知道该关注哪些目录,它的回报是立竿见影的。工程师们因为在代码库中每日工作,所以对此习以为常。你也在构建同样的心智地图,只是通过对话而非代码阅读来实现。
3.3 几乎能解答一切问题的四个提问模式
PM关于代码库的大多数问题都可以归入以下四个模式。掌握这些模式,你几乎可以在无需工程协助的情况下调查任何问题。
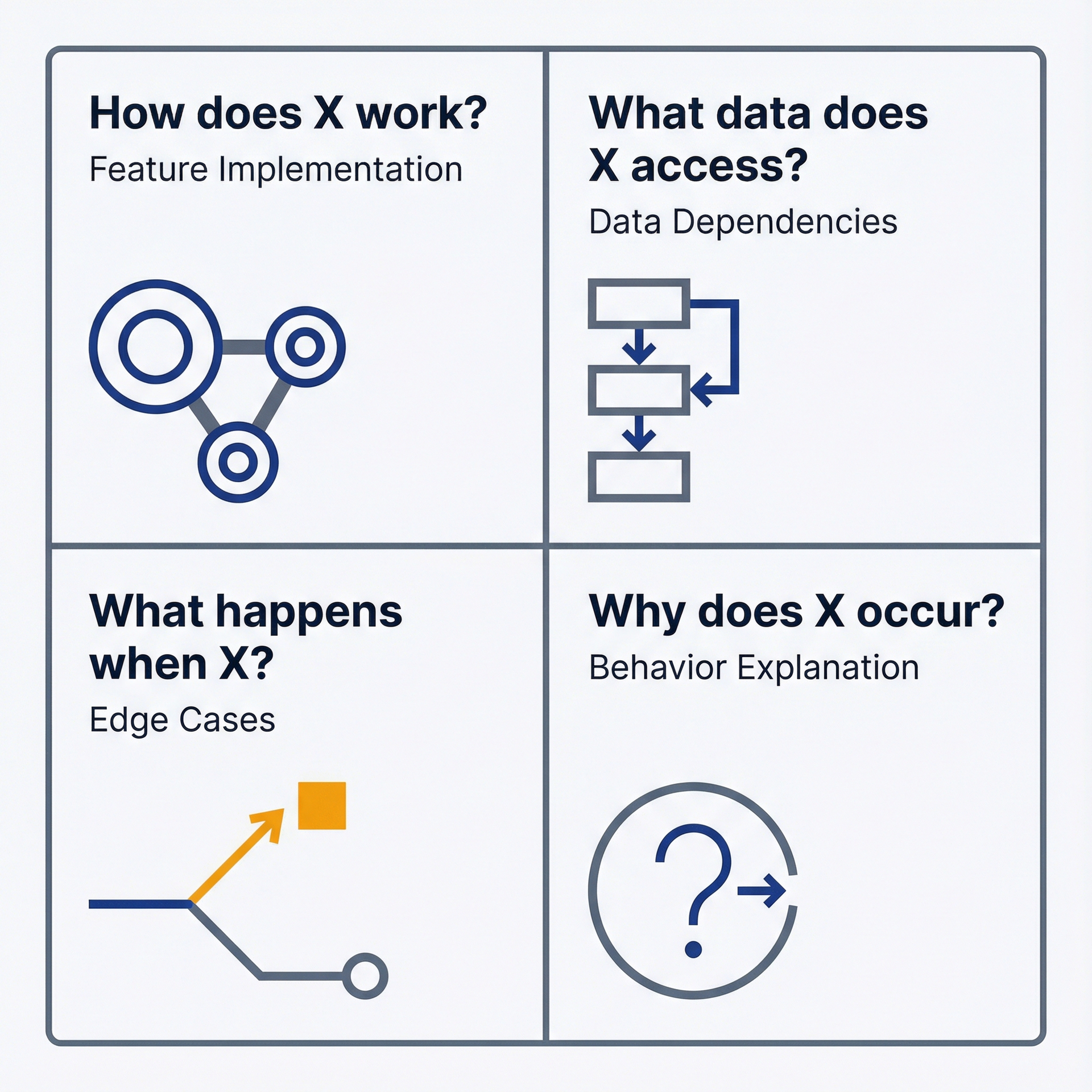
图 3.2:四种调查模式——用于组织你的代码库查询。这个2x2网格涵盖了:"X是如何工作的?"(功能实现)、"X访问了哪些数据?"(数据依赖)、"当X发生时会发生什么?"(边缘情况),以及"为什么会发生X?"(行为解释)。这四种模式覆盖了90%的PM调查场景。
模式1:"[功能]是如何工作的?"
你需要了解实现情况才能回答产品问题。有客户问为什么折扣码不能与促销活动叠加使用。工程团队构建了这个功能,但你不了解其设计原因。与其去问工程团队解释,不如直接问代码库。
以plan模式启动Claude Code并使用以下prompt:
Prompt:功能实现
折扣码验证在这个应用中是如何工作的?具体来说:
- 折扣码逻辑在哪里实现?
- 哪些规则决定了折扣码是否可以应用?
- 折扣码能否与其他促销活动叠加使用?为什么可以或不可以?
- 当用户输入无效代码时会发生什么?
请使用产品语言解释,而非代码细节。
Claude Code会从用户操作(输入代码)开始,一直追踪到验证逻辑再到最终结果(折扣生效或显示错误)。你会得到带有文件引用的通俗解释。"折扣验证在src/services/discount-validator.js:45-78中处理。系统会检查代码是否活跃、是否未过期、是否满足最低购物车金额要求。禁止与促销活动叠加使用的规则位于第92行的一个业务规则中——当cart.hasActivePromotion为true时拒绝应用折扣码。"
这为你提供了答案(因为显式的业务逻辑导致不能叠加)以及向客户或利益相关者解释的上下文。它还告诉你了当需求变更时应该去哪里查看。现在你知道了哪个文件负责折扣逻辑。
模式2:"[功能]访问了哪些数据?"
理解数据依赖关系有助于你评估变更的影响,并识别隐私或性能方面的顾虑。假如你正在规划一个需要用户购买历史的功能,那有哪些数据可用?它们从何而来?有哪些隐私方面的考虑?
Prompt:数据访问调查
购买历史功能访问了哪些用户数据?请展示:
- 具体读取了哪些数据字段(订单详情、支付信息、收货地址等)
- 这些数据存储在哪里(数据库表、外部API、本地存储)
- 代码中谁有权访问这些数据(哪些服务或组件)
- 我应该了解的任何隐私或安全方面的考虑
你会了解到:购买历史从orders表中拉取数据(订单ID、日期、商品、金额),并与products表做连接以获取当前商品名称,同时出于安全考虑排除支付详情。数据只能由已认证用户查看自己的历史记录,由src/middleware/auth.js:34中的中间件强制执行。这告诉你对于你的新功能,什么是可行的以及有哪些约束条件适用。
模式3:"当[条件]发生时会发生什么?"
边缘情况和错误场景对产品质量至关重要,但如果不看实现,很难发现这些情况。当支付在结账中途失败时会发生什么?当用户会话在表单提交过程中过期时会怎样?当库存从加入购物车到完成购买之间耗尽时又如何?
Prompt:边缘情况调查
当支付在结账过程中失败时会发生什么?请带我逐步了解:
- 用户会看到什么(错误消息、页面状态)
- 他们的购物车和订单会发生什么
- 我们是否会重试,还是用户必须重新开始
- 如何处理部分完成的情况(如果订单已创建但支付失败)
Claude Code会阅读错误处理代码、支付集成逻辑以及状态管理来解释具体行为。你可能会发现支付失败时会显示一个通用错误,保留购物车,允许重试而不丢失进度。或者你可能会发现边缘情况未被妥善处理的漏洞,这些就会变成backlog条目。
模式4:"为什么会发生[某行为]?"
用户反馈了一些令人困惑或反直觉的现象。在归类之前,你需要知道这是有意为之还是一个bug。为什么点击"显示更多"时搜索筛选条件会重置?为什么时间戳显示的是UTC时间而不是用户所在时区?为什么表单会接受无效电话号码?
Prompt:行为解释
用户反馈说,当他们点击"显示更多"来加载额外结果时,搜索筛选条件会重置。为什么会这样?是故意如此设计还是一个bug?
请解释代码中是什么导致了这种行为,以及是否有产品层面的原因。
你会了解到:"显示更多"触发了整页刷新(这是遗留实现),这会重置所有组件状态,包括筛选条件。这不是故意的,而是旧代码的技术限制造成的。现在你可以把它归类为bug,并为工程团队提供关于根因的上下文。
如何让这些模式奏效:
Prompt要具体。"认证是如何工作的?"这个问题太宽泛了。Claude Code可能会读取20个文件,然后给你一个系统概览,而你只需要了解一个细节。"当用户访问受保护页面时,应用如何判断用户是否已登录?"这个问题则更聚焦,能得到直接答案。
要求使用产品语言。始终包含"请使用产品语言解释"或"重点关注面向用户的行为",以防止出现你无法理解的代码密集型解释。除非你特别说明,否则Claude Code默认会输出技术细节。
提出跟进问题。第一个回答为你指明方向。后续问题则深入挖掘:"你提到第92行有一个业务规则。这条规则背后的设计理由是什么?"或者"你说支付失败时会保留购物车。那个逻辑实现在哪里?"
引用文件位置。Claude Code会提供文件路径和行号。当你需要工程团队帮助时,可以使用这些信息。"我调查了折扣码问题,在discount-validator.js:92找到了相关逻辑。你能解释一下禁止促销组合的设计理由吗?"这比"嘿,折扣码是怎么工作的?"要有效得多。
这四种模式覆盖了90%的功能调查场景。你不是在读代码,而是在提出有见地的问题,并获取被翻译为产品上下文的实现细节。每次调查可能花费10-20分钟和$0.15-0.50,但它能回答那些否则需要通过打断工程团队或对实现现实保持无知才能解决的问题。
3.4 不读代码也能"读"懂代码
你可以在不解析语法的情况下理解实现。Claude Code将代码翻译成概念、图表和通俗易懂的语言。本节介绍的技巧能帮助你从自己无法直接阅读的代码库中构建心智模型。
要求提供通俗摘要。代码是精确但不透明的,自然语言是可解释但可能模糊的。让Claude Code弥合这一差距:
Prompt:通俗摘要
用通俗语言总结processCheckout函数做了什么。重点关注:
- 按顺序执行的步骤
- 它需要哪些输入
- 它返回或产生什么
- 可能出错的地方以及它如何处理错误
输出示例:"该函数接收一个购物车对象和支付信息。首先,它验证购物车有商品且金额正确。其次,它通过Stripe集成处理支付。如果支付成功,它在数据库中创建订单记录,发送确认邮件,并清空购物车。如果支付失败,它记录错误并返回失败而不创建订单。如果支付成功后数据库写入失败,它将订单加入队列以进行人工对账。"
你现在无需阅读一行代码就理解了结账流程。你可以向利益相关者解释它,识别改进机会,并就边缘情况提出有意义的问题。
请求流程图和时序图。可视化表示通常比文字更能清晰地呈现复杂逻辑。Claude Code无法生成真正的图片,但可以生成展示流程的文本图表:
Prompt:流程图请求
创建一个基于文本的流程图,展示当用户提交结账表单时会发生什么。显示决策点、成功/失败路径以及外部服务调用。
可能的输出:
用户提交结账表单
↓
验证购物车(商品存在,价格最新)
├─ 无效 → 返回错误给用户
└─ 有效 → 继续
↓
通过Stripe API处理支付
├─ 支付失败 → 记录错误,显示用户消息,保留购物车
└─ 支付成功 → 继续
↓
在数据库中创建订单
├─ DB错误 → 加入人工对账队列,通知团队
└─ 成功 → 继续
↓
发送确认邮件
├─ 邮件失败 → 记录警告(订单仍然已创建)
└─ 成功 → 继续
↓
清空购物车,重定向到确认页面
这向你展示了每一个决策点、失败模式和依赖项。你可以逐一走查客户场景。"如果支付成功但邮件发送失败怎么办?"图表显示订单会创建,邮件失败会被记录但不会阻塞流程。这是重要的产品知识。
识别某个功能的"重要"文件。大型代码库有数百个甚至数千个文件,其中大部分与任一给定功能都无关。让Claude Code来筛选:
Prompt:关键文件识别
我需要理解结账功能。我应该了解哪五个最重要的文件?对每个文件,解释它负责什么以及为什么它对结账至关重要。
Claude Code分析代码库并排出优先级:"1. CheckoutForm.tsx——用户交互的React组件,处理表单提交并显示错误。2. checkout.service.js——包含处理结账的业务逻辑,验证购物车并编排支付。3. stripe-integration.js——处理所有用于支付处理的Stripe API调用。4. order.model.js——订单的数据库模型,定义了我们存储哪些数据。5. email-notifications.js——发送确认邮件并处理模板渲染。"
现在,当你调查结账问题或规划改进时,你就知道该去哪里看了。你不再是盲目导航,而是带着上下文开始。
无需了解语法就能构建心智模型。你的目标不是阅读代码,而是理解功能如何运作、数据如何流动以及在何处做出决策。将你的问题聚焦在概念上:
- "用户注册流程中的主要步骤是什么?"
- "应用如何决定向用户展示哪个定价层级?"
- "搜索功能依赖于哪些外部服务?"
- "用户偏好存储在哪里?如何加载?"
这些问题揭示了系统的行为和架构,而无需你解析函数语法、理解循环或追踪变量赋值。Claude Code负责解析,并为你提供概念模型。
AI生成解释的局限性。Claude Code基于它读取的内容来解释代码,但它无法运行代码,也不能保证其解释是正确的。如果逻辑复杂、存在细微的bug或者依赖于Claude Code无法看到的运行时条件,解释可能不完整或错误。
将解释视为高置信度的假设,而非绝对真理。当准确性至关重要时(调试关键问题、评估安全影响、规划重大变更),请与工程团队验证。当需要一般性理解时(回答利益相关者的问题、对bug进行triage、评估可行性),Claude Code的解释足够可靠,可以据此采取行动。
你通过提出正确的问题并以摘要代替语法,做到了"不读代码也能读懂代码"。这足以满足80%的PM需求。剩下的20%(深度调试、安全审计、性能优化)仍然需要工程专家的参与。认清这个边界,你就不会越过界限。
3.5 让Claude Code记住你的上下文
每个Claude Code会话启动时,如果项目中存在CLAUDE.md,它都会先读取该文件。这个文件包含了能够在所有会话之间持久存在的上下文:你的项目中那些不适合放在代码注释或外部文档中的隐性组织知识。
对于PM来说,一个精心维护的CLAUDE.md能将Claude Code从一个聪明的助手转变为了解你产品的团队成员。没有CLAUDE.md的第一次会话需要你解释自己的领域,而有CLAUDE.md的每一个会话从一开始就具备了充分的上下文信息。前期投入的安装时间会立即得到回报。
目的:在会话之间持久存在的上下文。关闭窗口时,Claude.ai会忘记一切。退出会话时,Claude Code会忘记对话历史。但CLAUDE.md会持续存在。你希望Claude Code在每个会话中都知道的任何内容都放在这里。
这不是一个存放所有文档的堆积场,而是能提升调查质量并减少重复性解释的聚焦式上下文。把它想象成一位AI队友的上岗培训文档。
针对PM工作流应该包含的内容:
产品领域术语表。你的产品中有一些在你的领域内模糊或特定的术语,一次性定义清楚:
Product Terminology- Credit:用户通过推荐获得的内部货币,与支付积分无关。- Workspace:一个团队共享的环境。用户可以属于多个工作区。- Pipeline:销售管道,而非数据管道。指CRM中的交易阶段。- Activation:当用户完成个人资料设置并创建第一个项目时。与账户激活(邮箱验证)不同。
这可以防止Claude Code误解具有多重含义的术语。当你问到"activation rates"时,它知道你指的是个人资料完善,而非邮箱验证。
关键用户旅程与代码区域的映射。将产品流程与实现关联起来:
User Journeys### New User Onboarding1. 用户注册 → src/auth/signup.js2. 邮箱验证 → src/services/email-verification.js3. 个人资料设置 → src/components/ProfileSetup.tsx4. 创建第一个项目 → src/services/project-creator.js### Checkout Flow- 入口点:src/components/Checkout/CheckoutForm.tsx- 支付处理:src/services/payment-processor.js- 订单创建:src/models/order.js- 确认:src/services/order-notifications.js
当你需要Claude Code调查onboarding的某一部分时,它无需探索就能直接找到对应位置。这既节省token又节省时间。
团队约定与沟通规范。你的团队如何工作?Claude Code应该了解你的哪些实践?
Team Conventions- 所有面向客户的字符串均使用src/locales/中的i18n系统。不要建议硬编码字符串。- 定价逻辑仅存在于src/services/pricing/中。前端永远不会计算价格。- 我们在commit message中使用Jira ticket ID:"Fix checkout bug (PM-1234)"- 数据库迁移在运行前需要获得数据团队的审批- 功能开关在src/config/features.js中管理
这可以防止Claude Code提出违反团队实践的变更建议。如果你需要帮助生成发布说明,它知道要去commit中查找Jira ID。
指向外部文档的链接。指向Claude Code无法访问但你经常参考的资源:
External Resources- API文档:https://docs.internal.com/api- 设计系统:https://www.figma.com/design-system- 产品策略文档:[Google Docs链接]- 分析面板:https://analytics.internal.com在讨论功能时,请考虑与设计系统保持一致以及与产品策略相契合。
这些链接不会直接帮助Claude Code(它无法跟踪这些链接),但它们会提醒你在做出决策时查阅这些资源。
放置位置:CLAUDE.md应该放在哪里。主要且推荐的位置是项目根目录:/path/to/your/repo/CLAUDE.md。这使得文件对浏览仓库的任何人都可见,并将其确立为团队文档。
Claude Code按照层级结构读取CLAUDE.md文件。首先从你的主目录(~/.claude/CLAUDE.md,用于存放跨项目适用的个人偏好),然后从项目根目录。你也可以在子目录中放置CLAUDE.md文件,以提供针对代码库该部分的特定上下文,不过这种情况比较少见。
大多数PM的用例适合在项目根目录中放置一个单一的CLAUDE.md。你所要添加的内容(领域知识、用户旅程映射、团队约定)不仅是Claude Code能从中获益的,对工程师和设计师也同样有用。让它公开可见,并将其视为由团队共同维护的活文档。
随着理解的深入更新CLAUDE.md。将这个文件视为活文档。当你调查一个功能并学到了有价值的信息时,添加进去。团队约定变更时,更新它。当你注意到Claude Code反复犯同样的错误(曲解某个术语、遗漏某个模式)时,添加澄清说明。
当它能够防止一次重复性的解释,或者帮助新PM通过阅读你的CLAUDE.md来理解产品上下文时,这个文件就值回了它的投入成本。版本控制会追踪变更,你可以看到理解是如何随时间演进的。
面向PM的CLAUDE.md结构示例:
Product Context for Claude Code## About This Product[2-3句话:这个产品是做什么的?谁在使用它?]## Product Terminology[关键术语及其在你的领域中的具体含义]## User Journeys[映射到代码位置的关键用户流程]## Business Rules[代码中不明显的重要产品逻辑:- 为什么我们将X限制为Y?- Z行为背后的设计理由是什么?- 功能A有哪些约束条件?]## Team Conventions[我们如何工作,避免建议什么,遵循哪些实践]## External Resources[文档、设计、策略、分析的链接]## Common PM Questions[经常调查的话题及其快速答案或指引:- "定价是如何工作的?" → 参见 src/services/pricing/- "邮件内容在哪里管理?" → src/templates/email/]
从最小化起步。先添加术语表和一个或两个关键用户旅程。随着时间推移,当你发现哪些上下文能提升调查质量时再逐步扩展。一份50行、内容聚焦且高价值的CLAUDE.md,胜过一份500行的全能知识库。
3.6 知道何时应该向上反馈给工程团队
Claude Code读取代码、解释代码,并用通俗语言表达出来。对于大多数PM需求来说,这表现得非常出色,但你需要认识到它的边界所在。对AI生成的解释过于自信,会在你依据不完整或错误信息采取行动时造成问题。
运行时行为与静态分析。Claude Code读取的是源代码——你的应用程序的静态文本。它无法运行代码、观察实际行为或查看运行时状态。当行为依赖于配置、环境变量、数据库状态或外部服务响应时,这一点就很重要了。
具体例子:你问应用如何决定用户可以访问哪些功能。Claude Code读取权限检查代码并解释逻辑:"应用检查user.role是否为'admin',如果是,则授予对管理员功能的访问权限。"但它无法告诉你生产环境中实际分配了哪些角色、是否存在数据质量问题导致角色值不正确,或者环境变量是否在某些部署中覆盖了该逻辑。
对于理解某事物应该如何工作,Claude Code是可靠的。对于理解它在当前生产环境中实际如何工作,你需要运行时数据:日志、数据库查询、监控面板,或者工程团队的帮助。
配置和环境依赖。应用程序的行为会根据配置文件、环境变量和部署上下文的不同而不同。开发环境、暂存环境和生产环境可能运行相同的代码,但由于配置不同而有不同的表现。
Claude Code可以读取配置文件并识别依赖项,但如果没有被明确告知,它无法告诉你哪个配置在哪个环境中生效。如果你问"我们如何处理支付失败?",答案取决于Stripe是处于测试模式还是生产模式,那么Claude Code会解释两条代码路径,但可能不会明确指出哪个适用于什么环境。
在调查对环境敏感的功能时,明确指明配置。"在生产环境中我们如何处理支付失败?"这个问题会促使Claude Code去查找生产配置。
何时需要向上反馈给工程团队。你可以独立调查,但某些情况需要工程专家的参与:
安全敏感的问题。"这个认证实现安全吗?"或"一个用户能否访问另一个用户的数据?"这些问题需要安全专家的判断,而不仅仅是代码阅读。Claude Code可以识别明显的问题(明文存储密码、明显的SQL注入漏洞),但细微的安全问题需要人工审查。
性能问题。"为什么这个功能很慢?"这类问题涉及性能分析、数据库查询分析以及运行时行为观察。Claude Code可以通过阅读代码识别潜在的高成本操作(嵌套循环、N+1查询),但实际性能取决于数据量、数据库索引以及它无法看到的底层基础设施。
复杂调试。如果一个bug是间歇性的、依赖于数据的,或者涉及竞态条件,Claude Code的静态分析将无法找到根本原因。你可以利用它进行初步调查(缩小相关代码区域),然后带着上下文移交给工程团队。
架构决策。"我们应该将其重构为微服务吗?"或"对于我们的规模来说,这是合适的数据库吗?"这些问题需要工程团队在权衡各方面利弊、团队能力和长期维护成本后做出判断。Claude Code可以解释当前架构并识别痛点,但它无法做出战略性的技术决策。
生产系统访问。任何需要数据库查询、日志分析或监控面板审查的事情都在Claude Code的能力范围之外。它与代码和文件打交道,而不是与实时系统。
避免对解释过于自信。将Claude Code的解释视为高置信度的解读,而非绝对真理。当准确性至关重要时(面向客户的沟通、路线图决策、安全评估),在行动之前与工程团队验证你的发现。
使用这个心智模型:Claude Code就像一位初级工程师,能读代码并解释所看到的内容,但没有生产经验,也没和原作者交流过。你信任他阅读的结果,但对任何关键信息都要进行核实。
PM使用的实操边界:
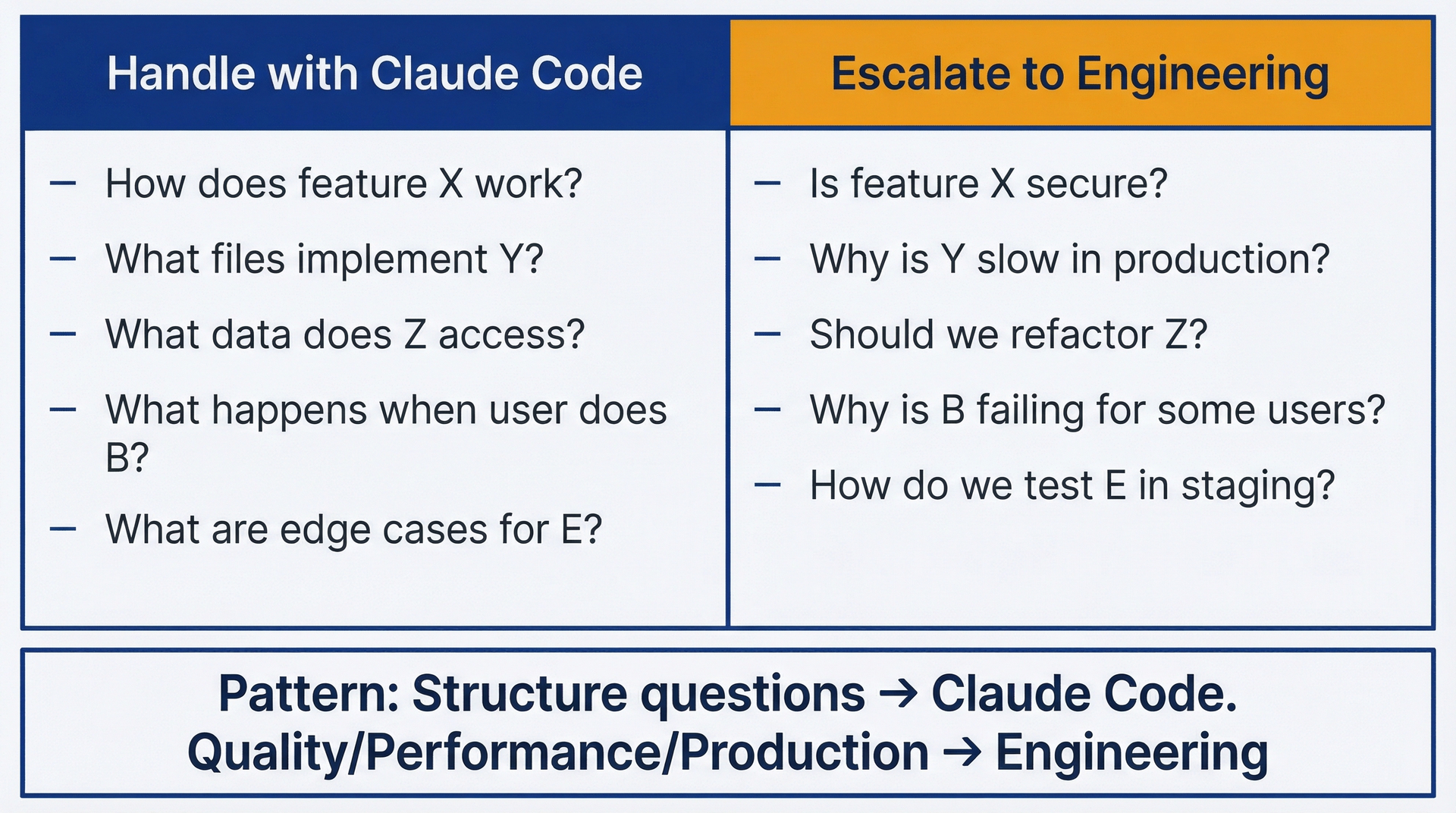
图 3.3:反馈升级边界——用于了解何时自行调查以及何时需要工程团队参与。左侧列显示Claude Code的领域(结构和行为问题):X是如何工作的、哪些文件实现了Y、Z访问了哪些数据。右侧列显示工程领域(质量、性能、生产问题):X是否安全、为什么Y在生产中很慢、我们是否应该重构Z。
你可以通过Claude Code处理向工程团队升级功能X是如何工作的?功能X是否安全?哪些文件实现了Y?为什么Y在生产中很慢?Z访问了哪些数据?我们是否应该重构Z?配置A在哪里定义?配置A在生产环境中是什么?用户执行B时会怎样?为什么B对某些用户失败?能否将功能C与D结合?我们应该如何构建C+D的集成?E的边缘情况有哪些?我们如何在暂存环境中测试E?
其中的规律是:关于存在什么以及结构如何的问题是Claude Code的领域;关于质量、性能、正确性和生产行为的问题则需要工程团队介入。
这并不会削弱Claude Code的价值,而是将你的使用聚焦在高回报的调查上,同时对AI的局限性保持适当的谦逊。你仍然可以通过自己处理第一轮调查来节省大量工程时间,只是要避免将AI的解释视为神谕般的真理这个陷阱。
现在,你可以在不必依赖工程团队回答每个问题的情况下调查你的代码库了。你理解了如何通过架构总览定位自己、应用功能调查模式、在不阅读代码的情况下构建心智模型、在CLAUDE.md中创建持久化上下文,以及识别何时需要向上反馈。第4章将向你展示如何将这些能力具体应用于bug调查——在这一PM工作流中,代码库的访问能力能带来立竿见影、可衡量的价值。
第4章
调查 Bug 与用户问题
4.1 无需工程协助即可进行的Triage
一张支持工单到了:"我的付款没有通过,但被扣款了。"工程团队正在为发版打包。客户正在向你的VP升级投诉。你需要进行triage:这到底是个真实的bug、用户操作错误,还是边缘情况?你需要判断影响范围:是只影响这一个客户,还是系统性问题?你需要了解上下文:工程团队在开始调查之前应该知道什么?
传统PM的响应方式:把工单转发给工程团队,附上一句"可以看一下吗?",然后就是等待。工程师切换上下文、调查问题、然后汇报。如果是用户操作错误,你就为一个毫无意义的事情打断了冲刺。如果是真实的bug,你除了原始的客户投诉外没提供任何额外上下文。不管哪种情况,反馈循环都要几个小时甚至几天。
替代方案:打开Claude Code,自己调查支付流程,识别可能导致该行为的代码路径,然后在分配给工程团队之前整理好发现。总用时:20分钟。工程团队收到的是附带文件引用和假设的聚焦式调查。他们只需要确认和修复,无需经历发现阶段。
bug调查是Claude Code能够提供立竿见影、可衡量的PM价值的地方。你不是在修复bug——那是工程团队的工作。你是在收集上下文、形成假设并减少来回沟通。好的triage每周能节省数小时的工程时间。糟糕的triage则因为不完整且需要追问的交接而浪费所有人的时间。
你在bug调查中的角色:
是真实的bug还是用户操作错误?许多所谓的"bug"其实是用户不理解预期行为、配置错误或会话过期。调查往往会揭示系统运行正常而用户产生了误解。发现这一点就能避免工程团队浪费一个不必要的调查周期。
影响范围和严重程度如何?只影响一个客户还是很多客户?涉及数据丢失还是只是外观问题?间歇性的还是可复现的?这些上下文决定了优先级。Claude Code能帮助你理解什么条件会触发该问题,以及这些条件的波及范围可能有多广。
工程团队需要什么上下文?文件位置、相关的代码路径、类似的过往问题、你已识别的复现步骤。你提供的上下文越多,工程团队解决问题的速度就越快。未经调查的原始客户投诉只会制造更多工作,而非更少。
你不是被期望去修复bug,而是被期望进行智能化的triage、提供有用的上下文,并避免将工程时间浪费在那些你本可以自行解决或澄清的问题上。Claude Code让你无需阅读代码就能做到这一点。
4.2 将用户投诉转化为可测试的查询
用户的语言和代码的语言不匹配。客户描述的是症状:"页面坏了。""我的折扣没生效。""我登录不了。"工程师需要的是具体信息:错误消息、复现步骤、环境详情、数据状态。你的工作就是翻译。
将用户语言转化为技术查询。从模糊中提取具体信息。一份报告说"结账页面坏了"。具体是哪里坏了?他们看到了错误消息吗?他们当时正在尝试做什么?实际发生了什么,而不是他们预期应该发生什么?
如果你能访问原始的支持工单,提取这些细节。如果不能,就做合理的假设并在调查中注明。然后让Claude Code帮助识别什么可能导致所描述的症状。
以plan模式启动Claude Code:
claude --permission-mode plan
Prompt:症状翻译
一位用户反馈:"[粘贴确切的投诉内容]"
哪些代码路径可能导致这种行为?请识别:
- 哪些文件处理此功能
- 每一步可能出现什么问题
- 用户可能遇到哪些错误状态
- 什么数据或条件可能触发此问题
举个例子,针对"我的折扣码明明有效却没有被应用":
一位用户反馈:"我的折扣码明明有效却没有被应用。我正确输入了,它只显示'invalid code'。"
在折扣或结账流程中,哪些代码路径可能导致这种行为?识别潜在的故障点:代码验证逻辑、过期检查、使用次数限制、购物车要求、大小写敏感性。
Claude Code读取相关文件并返回类似这样的内容:"折扣验证在src/services/discount-validator.js中处理。代码检查:(1) 代码在数据库中存在,(2) 基于valid_until日期未过期,(3) 使用次数低于max_uses,(4) 购物车满足minimum_cart_value。任一检查为false时返回'invalid code'且没有具体的提示信息。大小写敏感性已强制执行,所以'SUMMER20'和'summer20'是不同的代码。"
你现在有了一个可测试的假设。那个通用的"invalid code"消息掩盖了实际的失败原因。客户的代码可能已过期、超出使用限制,或者输入的大小写不对。所有这些在用户看来都像是有效的代码,但都会被系统拒绝。
识别相关的日志模式和错误消息。如果你的应用记录了错误,问Claude Code存在什么日志:
折扣码验证有哪些日志或错误追踪?我在哪里可以找到折扣应用失败的日志?
Claude Code会识别日志语句、错误处理器以及错误详情被捕获的位置。你会了解到失败的验证带有原因代码被记录到logs/discount-errors.log,或者失败根本没有被记录。日志的缺失本身就是改进调试的有用信息。
区分前端 vs. 后端 vs. 数据层面的问题。并非所有bug都是代码层面的bug。有些是配置问题、数据质量问题或环境不匹配。
Prompt:问题层面识别
一位用户经历了[症状]。请帮我判断这最可能是以下哪一类:
- 前端问题(显示、客户端逻辑、浏览器兼容性)
- 后端问题(服务端逻辑、API响应、业务规则)
- 数据问题(数据库状态、用户记录问题、缺失数据)
- 配置问题(环境设置、功能开关、第三方服务)
什么证据能够区分这些类别?
对于折扣码的例子,Claude Code可能会解释:"如果代码没有被正确发送,则是前端问题(检查网络请求)。如果验证逻辑存在bug,则是后端问题(我们审查过的代码)。如果数据库中折扣码记录格式错误或缺失,则是数据问题。如果该环境中折扣服务被禁用或Stripe未正常处理,则是配置问题。"
这会缩小你的调查范围。如果客户说"我输入了代码,立刻收到了错误提示",那很可能是前端或后端验证的问题。如果他们说"好像生效了,但折扣没有显示在我的收据上",那很可能是后续的处理步骤出了问题,也许是后端计算或数据持久化方面的问题。
复现调查的成本和时间。一次典型的复现调查会话(翻译用户投诉、识别相关代码、缩小到可能的原因)需要10-20分钟,消耗15,000-40,000 token。API用户的成本:$0.08-0.20。订阅用户的成本:已包含在内。与之对比的替代方案是:一张模糊的工单被工程团队退回要求更多信息,使解决时间增加一天。
4.3 从用户反馈到工程交接,30分钟内完成
结构化的调查胜过临时性的探索。遵循以下工作流,从用户反馈过渡到可执行的工程交接。
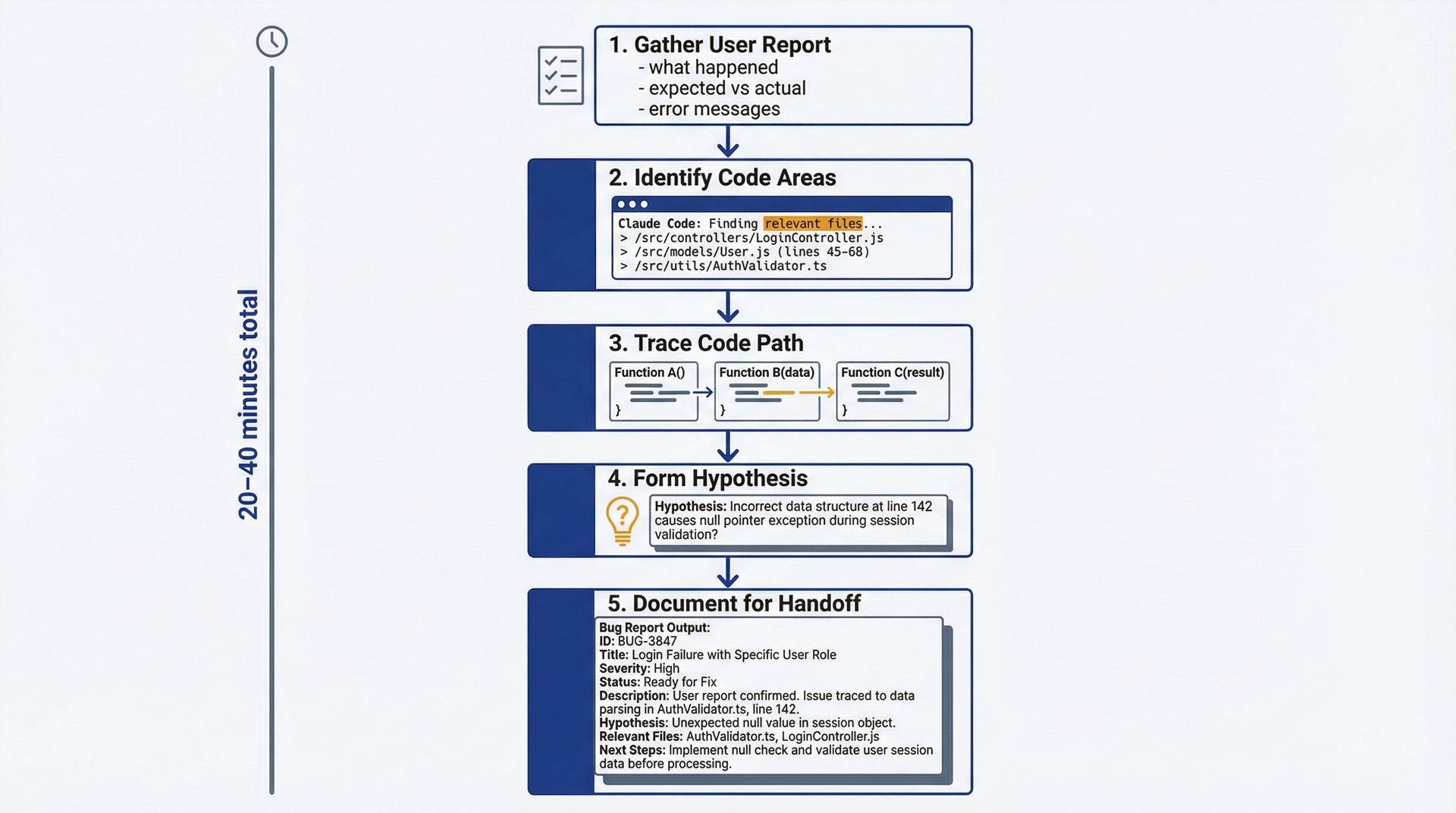
图 4.1:Bug调查工作流——用于组织你的bug triage流程。五个步骤:1) 收集用户反馈详情(5分钟),2) 利用Claude Code识别相关代码区域,3) 追踪代码路径,4) 形成可测试的假设,5) 记录发现以交接给工程团队。总用时:20-40分钟。
第1步:收集用户反馈详情。在接触Claude Code之前,从反馈中提取你能提取的一切信息:
- 用户试图做什么
- 他们预期会发生什么
- 实际发生了什么
- 他们看到的任何错误消息(尽可能获取确切文本)
- 发生的时间
- 他们使用的浏览器/设备/环境
- 他们能否复现,还是只是一次性发生的
这需要五分钟,并且能够防止在无效的调查循环上浪费时间。如果因为不知道用户使用的是过时的浏览器就去调查"登录有问题",你追踪的代码实际上运行正确。
第2步:让Claude Code识别相关代码区域。在收集了上下文之后,开始你的调查会话:
claude --permission-mode plan
Prompt:代码区域识别
我正在调查一个用户反馈的问题:[一句话摘要]
上下文:
- 用户操作:[他们当时在做什么]
- 预期:[本应该发生什么]
- 实际:[实际发生了什么]
- 错误消息(如有):[确切文本]
请识别可能涉及的代码区域。展示给我:
- 入口点(该用户操作在代码中的起始位置)
- 执行路径中的关键文件
- 错误在哪里被捕获和处理
- 哪里可能会失败
Claude Code会绘制出相关的代码区域。对于支付失败的调查,你可能会得到:"用户点击支付 → CheckoutButton.tsx分发action → checkout.service.js验证购物车 → payment-processor.js调用Stripe API → 响应在payment-response-handler.js中处理 → 订单在order.service.js中创建。每一步都有错误处理;Stripe集成在stripe-errors.js中有特定的错误映射。"
第3步:请求对可疑代码路径进行解释。一旦知道了该看哪里,就进一步问细节:
请逐步解释payment-processor.js做了什么。重点关注:
- 什么可能导致它失败
- 当Stripe返回错误时会发生什么
- 用户看到的是具体的错误消息还是通用消息
- 支付失败时记录了什么日志
Claude Code读取文件并翻译:"该处理器验证支付方式存在,检查购物车总额与扣款金额一致,调用Stripe的charge API,然后处理响应。Stripe错误被捕获并映射。'card_declined'变为'Your card was declined','insufficient_funds'出于隐私原因也显示相同消息。所有失败都将Stripe错误代码记录到payments.log,但向用户显示通用消息。如果Stripe返回成功但之后的订单创建失败,存在一个对账队列来捕获这些孤立的支付。"
现在你开始有进展了。用户说他们被扣款了但支付"没有通过"。这可能意味着:Stripe成功扣款,但订单创建失败,触发对账队列。客户被扣了款却看到了错误,因为失败发生在支付之后。
第4步:形成假设。基于你的调查,形成一个可测试的假设:
"用户很可能已被Stripe成功扣款,但随后的订单创建失败了。这可能是数据库错误、超时或验证问题。系统在支付成功的情况下显示了通用错误消息。对账队列中应该有这个案例。如果是这样,该笔支付存在于Stripe中,用户需要手动创建订单或退款。"
这是可执行的。工程团队可以检查对账队列,在Stripe中验证,并解决这个具体案例,同时调查订单创建失败的原因。
第5步:为工程团队整理调查发现记录。整理你的调查:
Prompt:调查摘要
总结我对这个bug的调查以供交接给工程团队。包含:
- 用户反馈了什么
- 我调查了什么
- 我审查了哪些文件和代码区域
- 我对根本原因的假设
- 给工程团队的具体问题
- 建议的后续步骤
Claude Code生成的摘要可以粘贴到Jira、Slack或邮件中。附上它找到的文件引用、你的假设,以及工程团队应该验证的内容。这种交接尊重了工程团队的时间,他们不需要从零开始。
完整工作流耗时:中等复杂度的bug约20-40分钟。Token消耗:30,000-80,000 token。对于API用户,成本为$0.15-0.40。一次能够为工程团队节省一小时发现时间的彻底调查,其价值远超此数。
4.4 在工程团队之前识别Bug类型
某些bug类别在不同产品中反复出现。识别这些模式能帮助你更快地调查问题,并与工程团队更精确地沟通。你不是在调试代码,而是在将症状与已知的问题类型进行模式匹配。
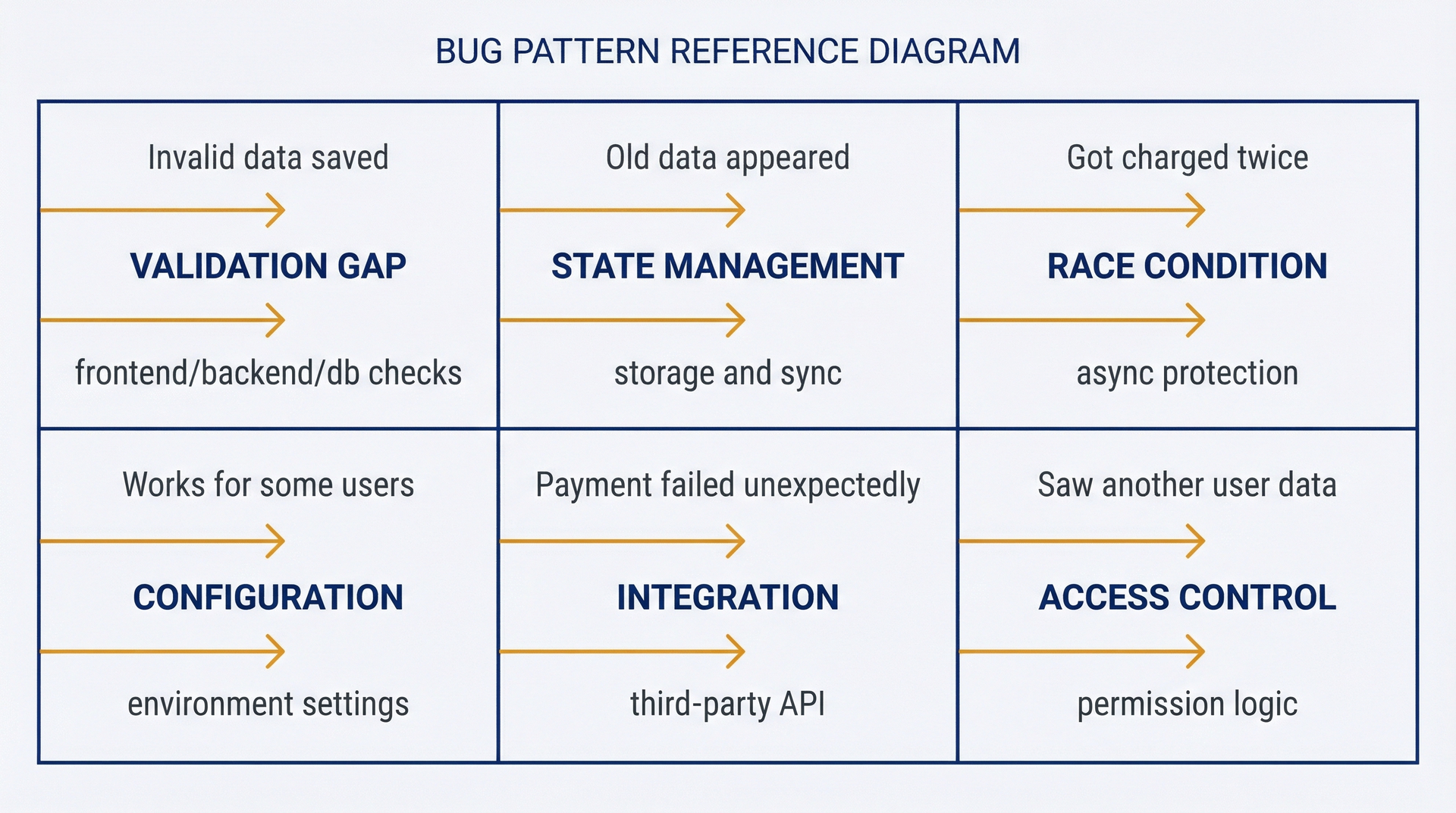
图 4.2:Bug模式参考——用于快速分类用户反馈的问题。六种常见模式:验证缺陷(无效数据被保存)、状态管理(旧数据显示出来)、竞态条件(被重复扣款)、配置不匹配(对某些用户有效)、集成失败(支付意外失败)、访问控制(看到了其他用户的数据)。将症状与模式匹配以加快调查速度。
数据验证缺陷。不应该通过的用户输入却通过了。表单接受无效的邮箱地址。价格字段允许负数。必填字段可以被绕过。这些bug源于不完整或前后端不一致的验证逻辑。
Prompt:验证调查
在这个功能中,[字段/输入]是如何被验证的?请检查:
- 前端验证(表单在提交前检查什么)
- 后端验证(服务器在接收数据时检查什么)
- 数据库约束(schema强制执行什么)
是否存在无效数据可能通过验证的漏洞?
Claude Code比较每一层的验证。你可能会发现前端检查了邮箱格式,但后端没有,允许API调用绕过前端验证。这就是你的假设:症状(数据库中的无效数据)匹配了模式(验证缺陷)。
状态管理问题。UI显示过时数据。导航后更改没有持久保存。用户看到了别人的数据。这些bug涉及应用如何追踪和同步状态。
Prompt:状态调查
[功能]的状态是如何管理的?请追踪:
- 状态存储在哪里(本地、会话、服务器)
- 用户操作后状态如何更新
- 状态何时被刷新或同步
- 什么可能导致状态过时或不正确
状态bug很微妙,因为代码"能运行",只是没有正确地协调好。Claude Code可以发现:用户资料被缓存到本地,但更新发生在服务端,而缓存在更新时没有被无效化。症状匹配了模式。
竞态条件(概念性识别)。两个不应该同时发生的操作发生了冲突。用户双击按钮被重复扣款。并发编辑互相覆盖。这些是时序bug,需要特定条件才会触发。
虽然无法通过静态分析来调试竞态条件,但可以识别其潜在的易发性:
[功能]可能存在竞态条件吗?请查找:
- 触发异步操作的用户操作
- 没有点击保护机制的按钮或表单
- 对共享资源的并发访问
- 应该是原子操作但实际上不是的操作
Claude Code可能会发现:"结账按钮触发了异步支付处理,但在点击时没有禁用。多次点击可能会发起多次支付调用。Stripe调用中没有幂等性key来防止重复扣款。"
在缺乏运行时测试的情况下,你无法确认这就是根本原因,但你已经识别出了这个模式。你的bug报告写道:"怀疑是竞态条件。结账按钮缺少点击保护,支付调用可能不具备幂等性。用户可能双击了。"
配置不匹配。功能在某些环境中有效但在其他环境中无效。暂存环境的行为与生产环境不同。某些用户体验到问题而其他人没有。这些bug源于环境特定的设置。
Prompt:配置调查
什么配置控制着[功能]?请展示:
- 影响行为的环境变量
- 功能开关或切换标志
- 不同环境之间有差异的设置
- 用户特定或账户特定的设置
你会了解到该功能使用了一个第三方API,该API在不同环境中具有不同的凭证,而生产环境的凭证已过期。或者一个功能开关只为beta用户启用了该功能,而受影响的用户不在beta组中。
第三方集成失败。外部服务返回错误、超时或行为异常。支付处理器拒绝有效的银行卡。邮件服务静默失败。分析事件未出现。
Prompt:集成调查
这个功能如何与[第三方服务]集成?请展示:
- API调用在哪里发起
- 如何处理来自该服务的错误
- 失败是否被记录以及如何记录
- 当集成失败时用户看到什么
Claude Code追踪集成细节。你会发现Stripe错误被记录了,但用户看到的是通用的"出了点问题"消息。或者邮件发送是fire-and-forget且没有错误处理,所以失败会静默消失。
权限和访问控制方面的bug。用户可以访问他们不应该访问的内容。用户无法访问他们应该访问的内容。仅限管理员的功能出现在普通用户面前。
Prompt:访问控制调查
[功能]的权限是如何被检查的?请展示:
- 访问控制逻辑在哪里
- 什么条件授予访问权限
- 系统如何确定用户角色/权限
- 访问被拒绝时会发生什么
你会发现权限检查只发生在前端,因此用户可以通过直接的API调用来绕过它。或者权限检查中有一个本应是AND的OR。症状匹配了模式:访问控制逻辑有缺陷。
模式参考表:
用户反馈…可能的模式调查重点"无效数据被保存了"验证缺陷比较前端/后端/数据库的验证"旧数据显示出来"/ "更改没有保存"状态管理追踪状态存储、更新、同步"被扣了两次款"竞态条件查找没有保护机制的异步操作"别人能用但我用不了"配置不匹配检查用户特定或环境特定的设置"支付失败,但按理说应该成功"第三方集成追踪外部API调用和错误处理"我能看到其他用户的数据"访问控制审查权限逻辑和执行情况
识别模式能将调查速度从"可能是什么问题"提升到"是不是这个具体的问题?"。你不是在调试,而是在对症状进行分类,以便更精确地与工程团队沟通。
4.5 工程团队真正愿意看的Bug报告
你的调查只有在有效沟通的前提下才有价值。工程团队需要具体信息才能快速行动。一份结构良好且附带调查上下文的bug报告能将解决时间从天缩短到小时。
工程团队需要什么:
复现步骤。他们如何触发该问题?从起始状态到出现错误的编号步骤。"1. 创建新用户账户。2. 将商品加入购物车。3. 使用折扣码'SUMMER20'。4. 点击结账。5. 观察错误消息。"如果你无法复现,就如实说明,并描述用户反馈了什么。
环境。这发生在哪里?生产环境/暂存环境/开发环境。浏览器及版本。设备类型。用户账户类型(新用户 vs. 现有用户,免费 vs. 付费)。任何可能影响行为的因素。
预期与实际行为的对比。应该发生什么?实际发生了什么?要具体。"预期:折扣应用且购物车总额更新。实际:错误消息'Invalid code'出现,尽管该代码在管理面板中是有效的。"
错误消息。确切的文本,而非改写后的。错误代码(如果可见的话)。用户提供的截图。如果你有权限访问,附上日志条目。
利用Claude Code的输出丰富报告。你的调查生成了文件引用、代码解释和假设,把它们包含进去:
Prompt:Bug报告生成
基于我的调查,生成一份bug报告,包含:
- 问题摘要
- 复现步骤(基于我的理解)
- 环境详情
- 技术上下文(涉及的文件、代码路径)
- 我对根本原因的假设
- 给工程团队的建议调查点
- 我无法回答的待解决问题
Claude Code将你的会话综合为结构化的输出。你仍然需要审阅和编辑(添加它未看到的用户反馈细节,删除你没有把握的推测),但它能创建一个扎实的初始草稿。
包含相关的代码片段而不假装自己是专家。你发现discount-validator.js:45-78中的折扣验证可能导致此问题。引用它而不假装你理解每一行代码:
"我调查了折扣验证流程,在discount-validator.js:45-78找到了相关逻辑。根据我的阅读,代码检查了[列出条件]。用户的场景可能在[具体条件]处失败,因为[假设]。我不确定这就是根本原因,但这是我会首先查看的地方。"
这提供了有用的上下文而不越界。你在说"我查看了这里,这看起来相关",而不是"我确切知道问题出在哪里"。工程师会欣赏这种上下文,并不会反感这种恰如其分的谦逊。
模板:经过PM调查的bug报告:
Summary[一句话描述该问题]## User Report- 用户操作:[他们试图做什么]- 预期:[本应发生什么]- 实际:[实际发生了什么]- 错误消息:[如有,提供确切文本]## Environment- 环境:生产 / 暂存 / 等。- 用户类型:[账户特征]- 浏览器/设备:[如已知]- 时间:[相关日期/时间]## Reproduction Steps1. [步骤1]2. [步骤2]3. [观察:具体行为](注明复现是由PM确认的还是基于用户反馈推断的)## PM Investigation### Files Reviewed- path/to/file.js - [该文件处理什么]- path/to/other.js - [该文件处理什么]### Findings[你从阅读代码中学到了什么。流程是什么样的。哪里可能出问题。]### Hypothesis[你对根本原因的最佳猜测,以假设而非结论的形式表述]### Open Questions- [你无法从代码中确定的事情]- [需要运行时验证的事情]## Suggested Next Steps- [ ] 在日志中验证[具体事物]- [ ] 检查[具体状态或数据]- [ ] 测试[具体场景]## Priority Assessment[你的建议:P1/P2/P3及其原因。影响范围评估——影响一个用户还是多个?]
不要包含的内容。不要包含大量你看不懂的代码堆砌。不要把假设当作结论来陈述。不要将责任归咎于特定的commit或工程师。不要对修复方案"有多显而易见"发表评论。坚持观察、假设和问题。
这样一份bug报告能将模糊的"某东西坏了"转变为可执行的工程工作。你已经完成了调查的前30%,工程团队完成剩下的70%,但剩下的工作是聚焦而高效的,而不是从零开始。
4.6 知道何时停下来
调查的回报是递减的。在某个节点之后,进一步的PM调查会浪费你的时间,并延迟工程团队的介入。要认清这些边界。
你已经收集到足够上下文的信号:
你能解释清楚流程。你理解了功能做什么、数据如何在其中移动以及在代码中的哪个位置发生。即使你不能流利地阅读代码,你也能描述从用户操作到结果的路径。
你有了可测试的假设。你已经形成了关于问题可能出在哪里的合理猜测。"折扣验证失败,因为代码区分大小写,而用户输入了小写。""支付成功但订单创建因数据库超时而失败。"假设不一定是正确的——它们给工程团队一个起点。
你已经识别出相关文件。你可以指向问题可能所在的具体文件路径。这为工程团队省去了探索阶段。
你知道自己不知道什么。你的调查遇到了限制:你看不到的运行时行为、你无法验证的数据状态、你无法访问的配置。记录这些空白有助于工程团队聚焦他们的调查。
如果这四条标准都已达到,那么你已经掌握了足够的信息。写出bug报告,然后交接。
你已力不从心的信号:
代码太复杂,无法总结。如果Claude Code的解释即使变成了通俗语言仍然难以理解,那么逻辑可能超出了调查能厘清的范畴。交接给工程团队。
你在原地打转。同样的问题你已经用了三种不同的问法问了三次,没有得到新的信息。这个问题需要运行时调试,而不是代码阅读。
涉及安全敏感性。认证、授权、数据访问、加密:任何处理不当都会产生严重后果的领域。你的假设可能危险地错误。工程安全审查是强制性的。
需要生产环境访问权限。检查数据库状态、读取生产日志、使用真实用户数据测试。Claude Code读的是代码,不是实时系统,你已到达了边界。
你已经花了一个多小时。对于大多数bug,如果一个小时的调查还没有产生明确的假设,那么这个问题已经复杂到应该由工程团队接手了。在这个节点之后,你的时间回报率呈递减趋势。
尊重工程时间的交接方案。当你交接时,清晰沟通:
"我花了30分钟进行调查。以下是我的发现:[摘要]。我的假设是[假设]。我停下来是因为[原因,如需要生产数据或代码过于复杂]。你能从这里接手吗?"
这告诉工程团队你做了什么、你怎么想的,以及从哪里开始。他们不会重复你的工作,也不会疑惑你已经尝试了什么。
回报递减曲线。前20分钟的调查产生了80%的上下文价值。你了解到相关文件,形成了假设,并识别出不足之处。接下来的40分钟大概只产生15%的额外价值:确认细节、排除替代解释、记录边缘情况。超过一个小时后,你可能只是在原地迭代而没有实际进展。
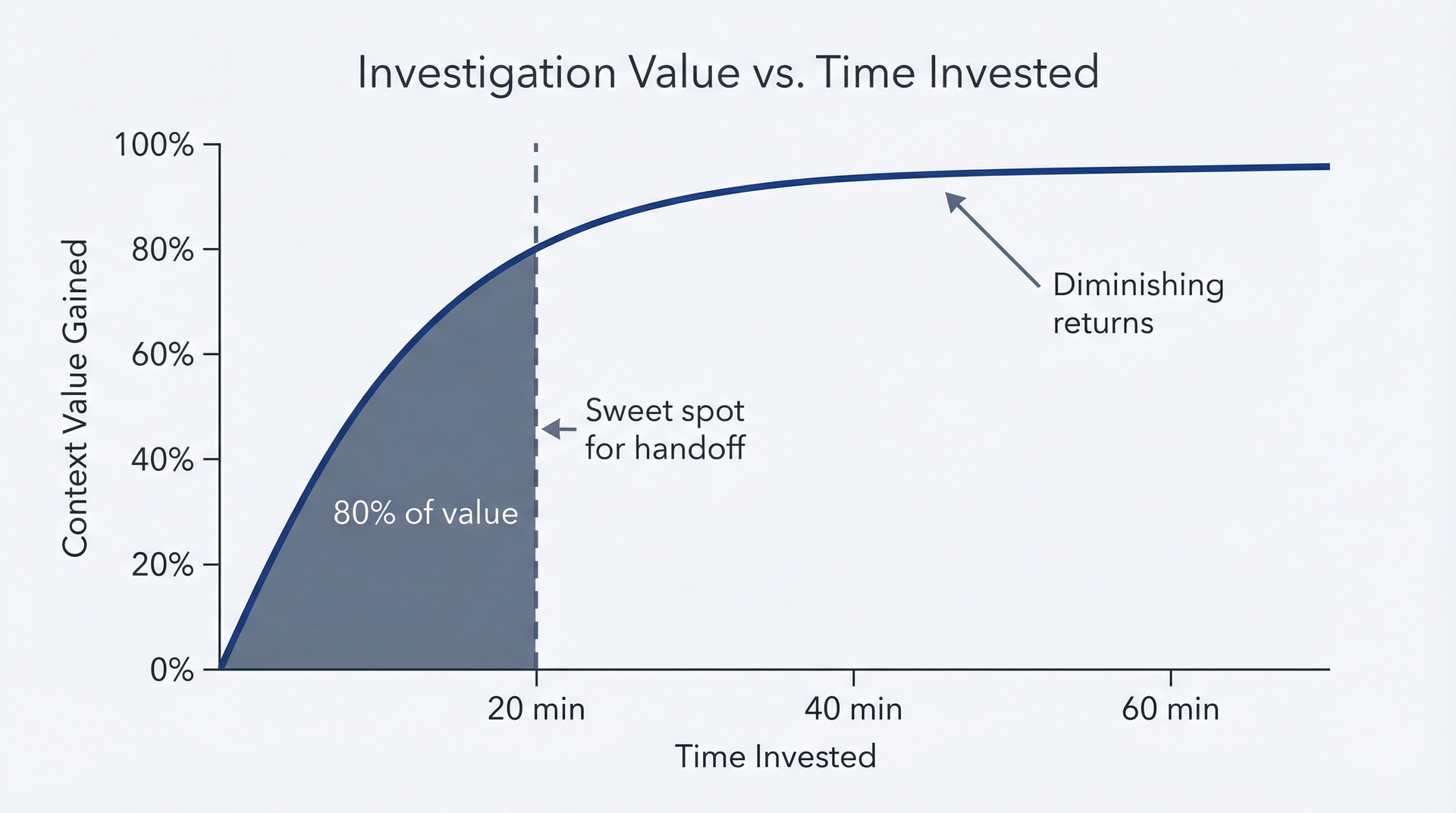
图 4.5:调查价值曲线——用于了解何时应该停止调查并交接给工程团队(20分钟规则)。曲线在前20分钟内急剧上升,捕获80%的上下文价值,随后显著趋于平坦。20分钟处有一条粗体竖线,标注为"交接点",并附有提示:"在此停止——工程师从此处接手。"绿色区域(0-20分钟)表示PM价值高;黄色区域(20-40分钟)表示收益适中;灰色区域(超过40分钟)表示回报递减。
对于简单的bug:15-20分钟的调查,然后交接。
对于复杂的bug:最多30-45分钟,然后带着清晰记录你尝试过什么的文档交接。
对于关键/紧急的bug:10分钟收集初步上下文,然后与工程团队并行工作,而非串行交接。
何时应该完全跳过调查。有些问题不需要PM进行前期调查:
- 用户报告的安全漏洞:立即向安全团队上报
- 生产环境宕机:事故响应由工程团队处理,而非PM
- 需要立即hotfix的问题:调查会延迟行动
- 复现步骤明确且影响显而易见的bug:直接提交工单
当收集上下文所节省的工程时间超过它所耗费的PM时间时,调查才产生增量价值。对于显而易见或紧急的问题,跳过调查直接交接。
现在,你可以在不依赖工程团队进行初步triage的情况下调查bug了。你理解了如何将用户投诉翻译为技术查询、遵循结构化的调查工作流、识别常见的bug模式、撰写有用的bug报告,以及知道何时该停下来。这种能力改变了你与工程团队的关系。你是调查中的合作伙伴,而不仅仅是一个工单转发器。
第5章将焦点从代码库工作转向研究:利用Claude Code进行市场和竞争分析,产出可持久化、可版本化的成果。
第5章
市场与竞争分析
5.1 为什么 Claude Code 在调研方面优于 Claude.ai
你的利益相关者要求在周五前完成一份竞争分析。你有三个选择。第一:花两天时间手动整理信息到一个 Google Doc 中,下个季度就会过时。第二:使用 Claude.ai 进行快速对话,产出不错的输出,但关闭标签页后就会消失。第三:使用 Claude Code 生成结构化的、可版本化的产出物,这些产出物保存在你的仓库中并且可以系统化地更新。
对于一次性问题("竞争对手 X 的定价模式是什么?"),Claude.ai 足够用了。对于需要持久保留、在 PRD 中被引用、每季度更新并在团队间共享的调研,Claude Code 才是正确的工具。区别不在于能力,而在于持久性和可重复性。
为什么使用 Claude Code 而不是 Claude.ai 进行调研?
持久性。调研产出成为仓库中的文件。它们不受会话关闭的影响,可以通过文件路径在文档中引用,并与团队现有的工作流集成。你今天生成的竞争矩阵,下个月当你的 VP 要求再次查看时,它会以 research/competitive-analysis-2026-01.md 的形式存在。
文件输出。Claude Code 会写出结构化的文档:markdown 表格、对比矩阵、格式一致的要点列表。Claude.ai 给你的是需要复制粘贴和重新格式化的文本。Claude Code 生成的是可以直接提交的产出物。
可重复性。你只需要构建一次调研方法论(提示词、输出格式、分析框架),然后就可以持续执行。季度竞争评审使用相同的流程,使结果具有跨期可比性。你不需要每个周期都重新发明调研结构。
可版本化。Git 中的调研产出物会跟踪变更。你可以看到 Q1 和 Q2 竞争分析之间的变化。你可以通过 diff 定价对比来发现趋势。这在向利益相关者汇报时非常重要,因为他们会问"这个格局发生了怎样的变化?"。
基于网页的 Claude 足够用的场景:探索性调研,你还在确定要问什么问题。快速事实核查。头脑风暴调研方向。任何对话本身比产出物生成更有价值的情况。Claude.ai 擅长迭代式对话。用它来思考,用 Claude Code 来记录。
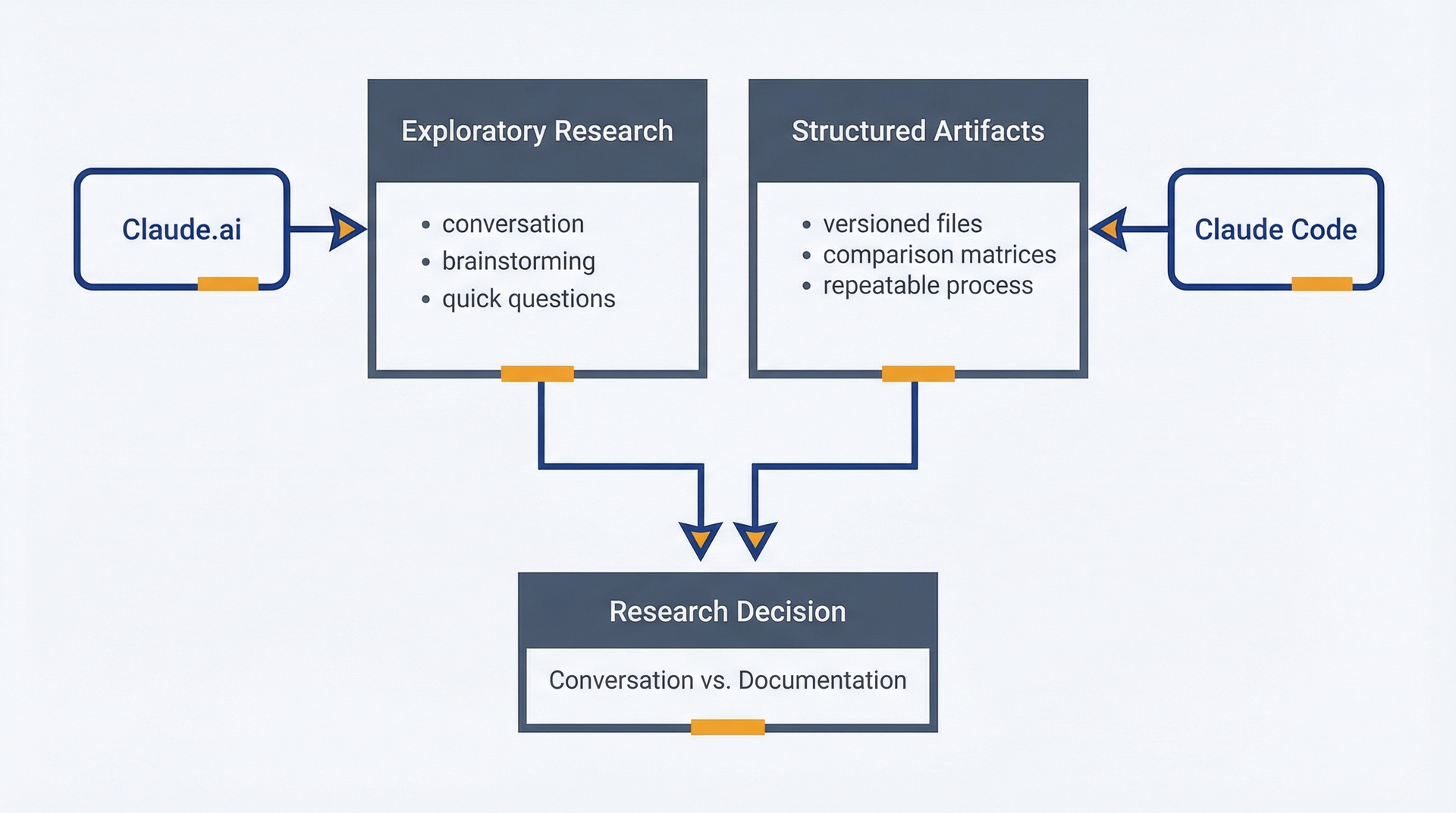
调研工具选择:Claude.ai 用于探索性对话 vs. Claude Code 用于结构化的、可版本化的产出物
生成竞争分析的会话花费 $0.30-0.75,耗时 15-25 分钟。对比两天的体力劳动或过时的调研信息导致糟糕产品决策的成本。只要你每季度做一次以上的市场调研,投资回报立竿见影。
5.2 构建可更新的竞争情报
你需要知道你的竞争对手是谁、他们提供什么、你的差异化在哪里。手动调研意味着浏览竞争对手网站、做笔记、试图把所有信息维护在一个不一致且不完整的电子表格中。Claude Code 系统化了这个过程。
建立竞争分析工作区。创建一个调研目录结构:
mkdir -p research/competitorscd research/competitors
这将调研与代码分开存放,便于查找,也可以按日期或主题来组织。你可以这样结构化:
research/├── competitors/│ ├── competitive-matrix-2026-01.md│ ├── competitor-a-profile.md│ ├── competitor-b-profile.md│ └── competitor-c-profile.md├── pricing/└── market-sizing/
在你的仓库根目录中启动 Claude Code,赋予文件写入权限:
claude
提示词模板:结构化竞争对手画像。做出有用的竞争分析的关键在于一致性。每个竞争对手画像都应该回答相同的问题,使用相同的格式。先定义你的结构,然后重复执行。
提示词:竞争对手画像
通过网页搜索研究[竞争对手名称],并在 research/competitors/[competitor-name]-profile.md 中创建结构化的画像。
包含以下章节:
- 概述:一段话描述他们是做什么的、服务谁、公司阶段
- 产品/服务:核心产品和关键功能(要点列表)
- 定价模式:如何收费、有哪些定价层级、大致的价格范围
- 目标市场:卖给谁(公司规模、行业、用户角色)
- 关键差异化:他们在定位中强调什么(3-5 个要点)
- 优势:相对于我们,他们在哪些方面更强
- 劣势:他们在哪些方面薄弱或有缺口(3-5 个要点)
- 近期动态:产品发布、融资、合作(最近 6 个月)
- 最后更新:[今天的日期]
使用网页搜索收集当前信息。每个章节保持简洁(这是参考文档,不是深度报告)。
Claude Code 搜索网络信息,综合发现,并写出结构化的 markdown 文件。输出预计 5-10 分钟生成,根据网页搜索量花费 $0.15-0.35。
你得到的结果:
一份一致的、结构化的画像,可供参考。每个竞争对手都有相同的章节,使对比变得直接明了。当你的 CEO 问"竞争对手 X 有什么不同的做法?"时,你可以打开他们的画像,查阅差异化章节。
输出格式:对比矩阵和功能表格。单独的画像是很有用的,但利益相关者想要的是对比。一旦你有了 3-5 个竞争对手画像,就可以生成矩阵:
提示词:竞争矩阵
基于 research/competitors/ 中的竞争对手画像,在 research/competitors/competitive-matrix-2026-01.md 中创建一个对比矩阵。
创建一个 markdown 表格,对比:
- 核心功能(行:认证、权限、集成、移动端支持、API 访问、报表等)
- 竞争对手(列:我们、竞争对手 A、竞争对手 B、竞争对手 C、竞争对手 D)
- 数值:✓(完全支持)、~(部分/有限)、x(不支持)、?(未知)
包含一个定价对比表:
- 行:免费版、入门版、专业版、企业版
- 列:同样的竞争对手
- 数值:价格/月 或"联系销售"或"不适用"
在每个表格后面添加简要分析(2-3 句话),突出关键模式。
Claude Code 读取你已有的竞争对手画像,提取相关信息,并格式化为可快速浏览的表格。矩阵会揭示差距:竞争对手有而你没有的功能、你不具备竞争力的定价层级、你应该强调的优势。
示例输出:
Feature Comparison| Feature | Us | Competitor A | Competitor B | Competitor C ||---------|----|--------------|--------------| -------------|| SSO/SAML | ✓ | ✓ | ~ | x || Role-based access | ✓ | ✓ | ✓ | ~ || API access | ✓ | ✓ (limited) | ✓ | x || Mobile apps | ~ | ✓ | ✓ | x || Custom integrations | ✓ | ~ | x | x || Advanced reporting | ✓ | ✓ | ~ | ~ |Analysis: We're competitive on enterprise features (SSO, RBAC, API) but lag on mobile. Competitors A and B have stronger mobile offerings. Competitor C is weak across the board, likely targeting SMB with simpler needs.
将结果保存为可版本化的产出物。将这些文件提交到 git:
git add research/competitors/git commit -m "Add Q1 2026 competitive analysis"
现在你的调研是版本化的。三个月后,更新画像,生成标注 Q2 日期的新矩阵。通过 diff 文件来查看变化:
git diff competitive-matrix-2026-01.md competitive-matrix-2026-04.md
你会看到竞争对手 A 新增了移动端功能,竞争对手 B 提高了价格,还有新的竞争对手进入了市场。这个历史视图展示的是格局的演变,而不仅仅是当前状态。
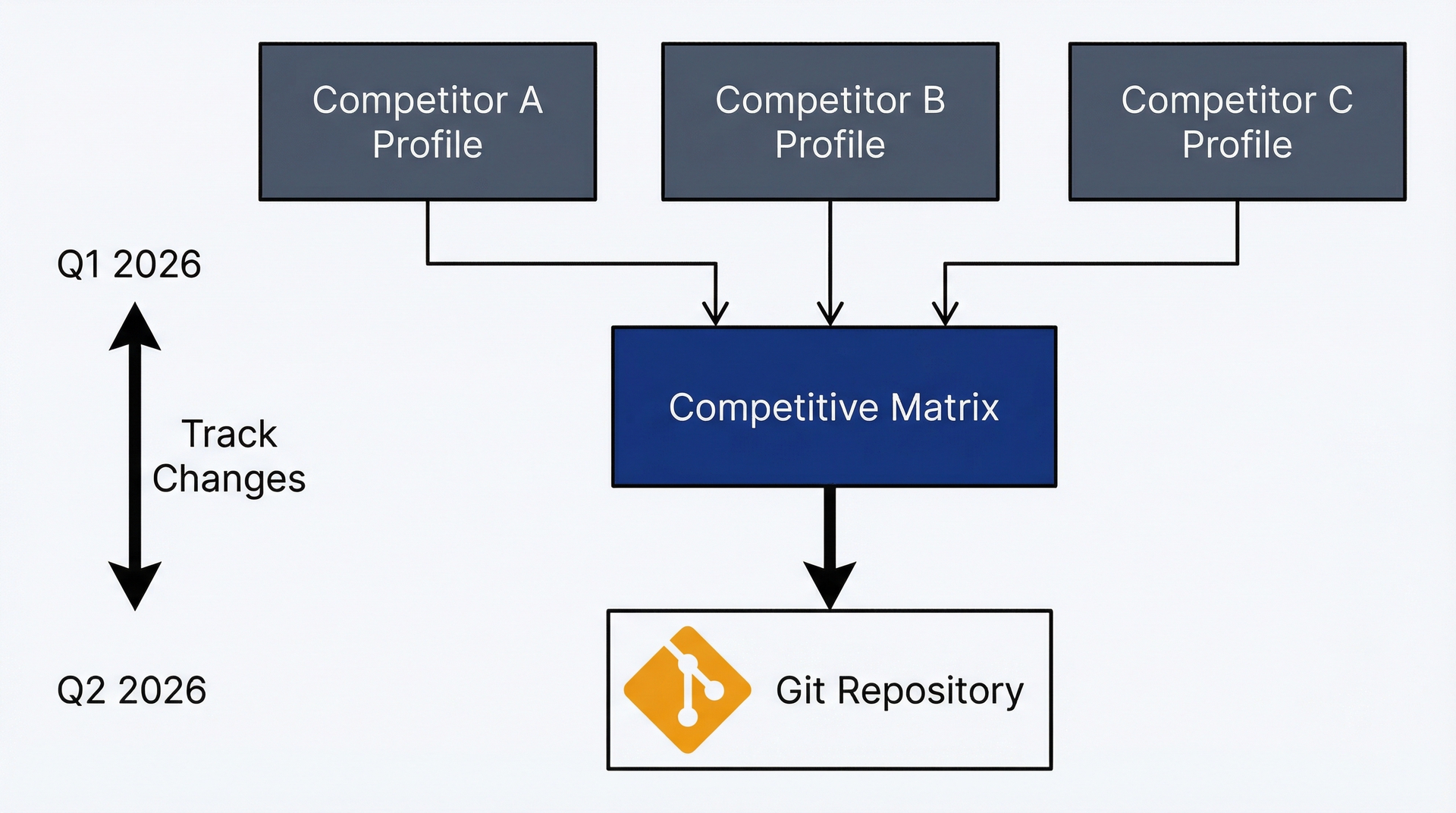
竞争分析工作流:独立画像汇总到对比矩阵,通过版本控制追踪时间变化
竞争格局映射的时间与成本。初始搭建(5 个竞争对手画像 + 矩阵):45-60 分钟,80,000-150,000 token,$0.40-0.75。季度更新(刷新画像 + 重新生成矩阵):20-30 分钟,40,000-70,000 token,$0.20-0.35。对比每周期 8-12 小时的手动调研。
这种方法会失效的情况:公开信息匮乏的利基行业。定价不透明的竞争对手(一切都要"联系销售")。信息每周都会过时的快速变化的市场。在这些情况下,Claude Code 仍然可以结构化你手头已知的信息,但你需要通过销售电话、分析师报告或客户访谈来补充。
5.3 不用电子表格追踪竞争对手定价
定价情报需要系统化的收集和结构化的对比。你的竞争对手收费 $49/月,但包含哪些功能?有什么限制?与你的 $59/月相比如何?手动调研能捕捉价格,但会遗漏上下文。Claude Code 两者都能捕捉。
系统化收集定价情报。定价页面会变化。促销活动会上线。折扣会出现。你需要一种可重复的快照方法,来追踪随时间的变化。
提示词:定价深度分析
通过网页搜索调研[竞争对手名称]当前的定价模式,并在 research/pricing/[competitor-name]-pricing-2026-01.md 中创建详细的分解说明。
包含:
- 定价层级:名称、月付价格、年付价格(如果不同)
- 各层级功能限制:用户数、存储空间、API 调用次数、项目数等
- 关键功能门槛:哪些功能被锁定在更高的层级?
- 附加组件:可选额外项目的价格
- 折扣:年付折扣百分比、批量折扣、非营利/教育优惠
- 免费版:包含什么、有什么限制
- 企业版:定价是公开的还是"联系销售"?包含什么?
- 计费模式:按用户、按功能、按用量、固定费率?
使用网页搜索收集当前信息。如果某些信息没有公开记录,标注为"未披露"。
在顶部添加"最后更新"日期。
Claude Code 搜索定价页面,提取详细信息,并一致地进行结构化。你得到的定价分解远不止"他们收费 $49/月"。你知道那 $49 包含什么、不包含什么,以及与他们其他层级相比如何。
提示词模板:定价模式对比。一旦有了各个竞争对手的定价文档,就可以对它们进行比较:
提示词:定价对比表
基于 research/pricing/ 中的定价文件,在 research/pricing/pricing-comparison-2026-01.md 中创建对比表。
创建一个表,包含:
- 行:定价层级(免费版、入门版/基础版、专业版/标准版、企业版)
- 列:我们、竞争对手 A、竞争对手 B、竞争对手 C
- 数值:每个用户每月的价格(如果不是按用户计费,则填写每月总价格)
在定价表下方,创建功能限制对比:
- 行:关键限制因素(用户数、存储空间、API 调用次数、项目数)
- 同样的列
- 数值:实际限制(例如,"10 users"、"100GB"、"1000/day")
添加分析:
- 每个层级中最便宜/最贵的是哪个竞争对手?
- 我们在哪些层级定价具有竞争力 vs. 偏高 vs. 偏低?
- 每个价格点的价值主张是什么?
这会揭示定价策略差异。也许竞争对手 A 标价更便宜,但按用户计算更贵。也许竞争对手 B 在相同价格下提供了更慷慨的限制,说明你应该重新审视自己的上限。也许你是唯一有真正免费版的,这是一个你没有足够强调的竞争优势。
通过信息传递审计分析定位。定价不仅仅是数字。它是竞争对手如何定位价值。他们强调什么?他们声称解决什么问题?他们引用了哪些客户类型?
提示词:定位分析
通过网页搜索调研[竞争对手名称]的网站,在 research/competitors/[competitor-name]-positioning.md 中分析其定位。
从他们的首页、产品页面和营销内容中提取并分析:
- 核心标题:他们的主要价值主张是什么?
- 关键信息主题:哪些概念反复出现?(例如,"快速"、"安全"、"简单"、"企业级")
- 引用的客户类型:他们说他们服务谁?
- 问题陈述:他们处理哪些客户痛点?
- 差异化声明:什么让他们"不同"或"更好"?
- 社会证明:他们展示哪些案例研究、Logo、客户评价?
- 行动号召:他们希望访问者做什么?(试用、演示、联系销售)
提供 2-3 句话总结他们的定位策略。
你会了解到竞争对手 A 定位为"面向受监管行业的企业级安全",而竞争对手 B 定位为"最快上手的方案(无需设置)"。这些是不同的价值主张,吸引不同的客户。你的定位需要要么与两者区分开来,要么瞄准一个未被充分服务的细分市场。
通过带日期的产出物追踪随时间的变化。定位会变化。竞争对手在进入新市场、融资后或面对竞争时会重新定位。追踪这些变化可以揭示策略。
将定位分析按日期保存:competitor-a-positioning-2026-01.md, competitor-a-positioning-2026-04.md。当你对比不同版本时,你会看到信息传递的演变。也许竞争对手 A 不再提"小团队"而开始强调"企业规模",他们正在向上迁移市场。这也为你的定位决策提供参考。
定价分析的时间与成本:对单个竞争对手定价进行深度分析:10-15 分钟,20,000-35,000 token,$0.10-0.18。5 个竞争对手的定价对比表:10 分钟,15,000-25,000 token,$0.08-0.13。每个竞争对手的定位分析:15-20 分钟,25,000-40,000 token,$0.13-0.20。
会失效的情况:定价复杂且定制化的竞争对手,其公开信息无法反映实际交易。不列出数字的不透明企业定价。在这些情况下,用销售情报来补充 Claude Code 调研:潜在客户告诉你的竞争对手报价、赢单/丢单分析、与前竞争对手客户的对话。
5.4 创建经得起推敲的市场估算
利益相关者想要数字。这个市场有多大?有多少潜在客户?我们的可触达机会是什么?市场规模的确定需要假设、数据源和结构化的推理。Claude Code 不会魔法般地给出准确数字,而是将你的方法论结构化,使你的假设公开透明、经得起推敲。
使用 Claude Code 结构化 TAM/SAM/SOM 分析。总可触达市场、可服务可触达市场、可服务可获得市场:这是经典的 VC 框架。你需要估算这些指标,记录你的推理过程,并使其可被审查。
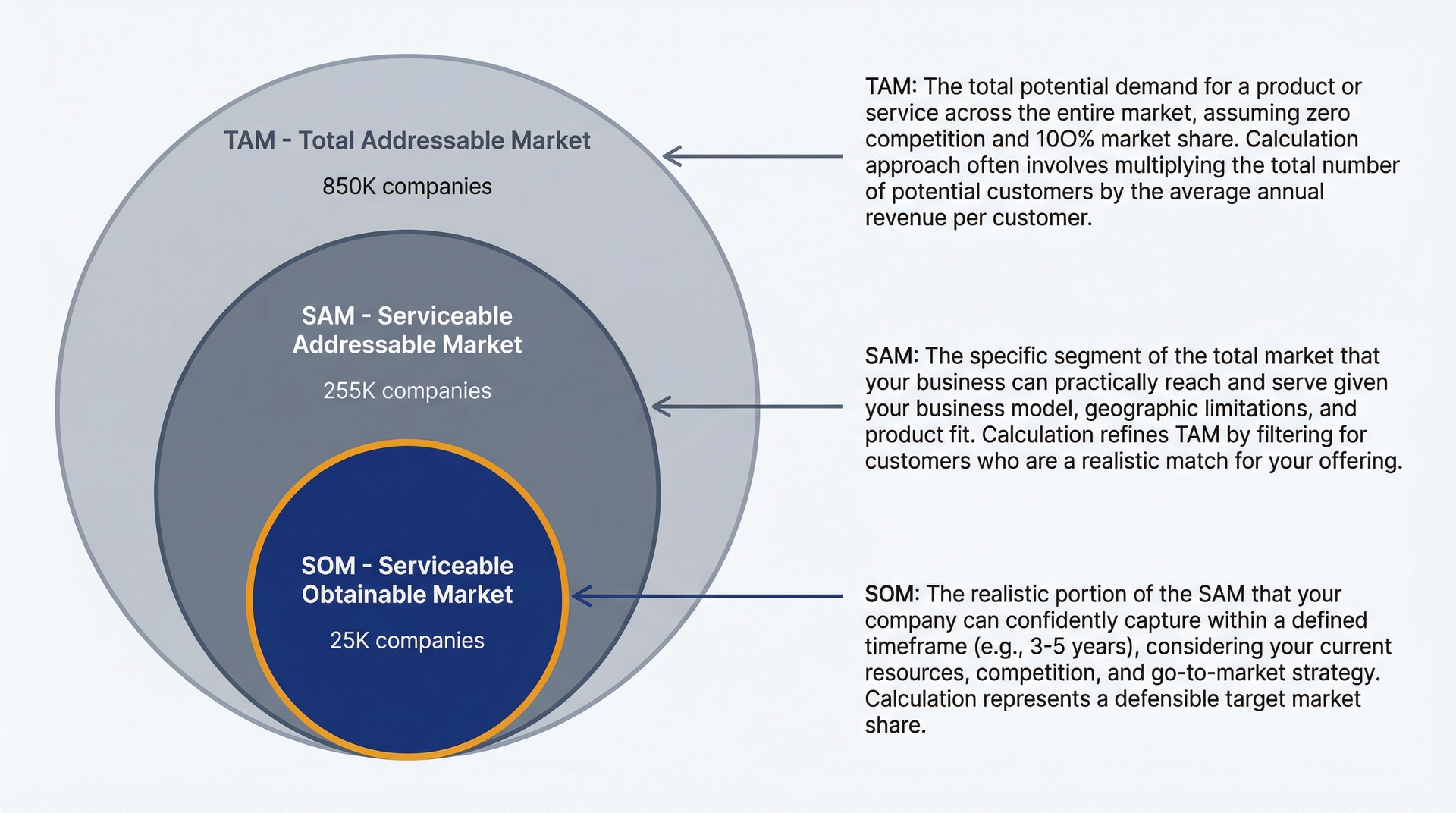
TAM/SAM/SOM 嵌套市场规模:从总可触达市场到可获得的机会
提示词:市场规模框架
帮助我使用 TAM/SAM/SOM 框架评估[产品/品类]的市场规模。创建 research/market-sizing/market-size-2026.md。
对于每个指标,提供:
- 定义:这个指标对我们的产品意味着什么
- 计算方法:我们将如何估算它
- 数据源:数字来自哪里(行业报告、人口普查数据、替代性数据)
- 假设:我们认为哪些前提为真
- 估算范围:低/中/高估算
- 推理:为什么这个计算是合理的
结构:
- TAM - 总可触达市场(如果每一个可能使用的人都在使用)
- SAM - 可服务可触达市场(我们实际可服务的子集)
- SOM - 可服务可获得市场(我们在 1-3 年内可以捕获的)
展示你的推理过程。让假设明确且保守。
Claude Code 帮助你推演逻辑:
Total Addressable Market (TAM)Definition: All companies in North America with 50-5000 employees that need [product category].Calculation approach:- Total companies with 50-5000 employees in North America: ~850,000 (US Census Bureau, 2024)- Percentage needing [product category]: ~30% (industry reports suggest penetration in similar tools)- TAM in companies: 850,000 × 30% = 255,000 companiesRevenue TAM:- Assuming average deal size of $5,000/year- 255,000 companies × $5,000 = $1.275 billionAssumptions:- Company size range captures target market (eliminates too-small and enterprise)- 30% need category based on analogous product adoption rates- $5,000/year is realistic average (mix of SMB and mid-market)Estimated range:- Low: $850M (20% need, $4K average)- Medium: $1.3B (30% need, $5K average)- High: $2.1B (40% need, $6K average)
你没有把假设隐藏在电子表格中。它们是记录在案的、可审查的。当你的 CFO 质疑 30% 的渗透率时,你可以明确地讨论它并更新模型。
提示词模板:带假设的市场规模估算。关键是记录方法论,而不是产生一个"魔法数字"。
提示词:市场规模方法论审查
审查 research/market-sizing/market-size-2026.md 中我的市场规模假设。对于每个假设,评估:
- 数据源是否可信?
- 逻辑是否合理?
- 是否有明显的缺口或值得商榷的跳跃?
- 什么样的敏感性分析会有帮助?(如果这个假设偏差 50% 会怎样?)
提供建设性反馈以增强分析。
Claude Code 会挑战你的推理。它可能会指出:"30% 渗透率的假设没有来源,它只是说'行业报告显示'。能否引用一份具体的报告或提供一个替代性计算?"或者:"这个计算假设所有目标公司花同样的金额,但 SMB 与中端市场的定价可能差异很大。考虑对计算进行细分。"
这种反馈帮助你得出经得起推敲的市场规模估算,而不仅仅是听起来不错的数字。
细分框架及其应用。市场不是铁板一块。你可以按公司规模、行业、地域或用例来进行细分。细分告诉你应该聚焦在哪里。
提示词:市场细分
按[公司规模 / 行业 / 地域 / 用例]细分[产品品类]市场。在 research/market-sizing/segmentation-2026.md 中创建细分分析。
对于每个细分市场,估算:
- 规模:有多少潜在客户?
- 特征:什么定义了这个细分市场?
- 需求:他们最关心什么?
- 支付意愿:价格敏感度(高/中/低)
- 竞争:还有谁瞄准这个细分市场?
- 我们的匹配度:我们今天服务这个细分市场的程度如何?(强/中/弱/无)
按吸引力对细分市场进行排名:规模 × 支付意愿 × 我们的匹配度。
你会得到一个带有清晰推理的、按优先级排列的细分市场列表。也许"中型医疗保健"得分很高,因为它规模大、愿意为你拥有的合规功能支付溢价,且被只专注于 SMB 或企业的竞争对手所忽视。这为 go-to-market 策略提供参考。
为利益相关者审查记录方法论。市场规模文档成为参考依据。你的董事会演示文稿会引用它们。你的销售团队用它们来理解目标市场。记录方法论使数字可信。
在你的市场规模文档中加入一个"如何更新此分析"章节:
How to Update This AnalysisTo refresh these estimates:1. Check US Census Bureau data for updated company counts2. Review [specific industry reports] for updated penetration rates3. Validate average deal size against actual sales data4. Re-run calculations with updated inputs5. Update "Last reviewed" dateReview cadence: Annually, or when entering new markets.
这让其他人(或未来的你)可以在不重新发明方法论的情况下更新分析。
时间与成本:初始市场规模分析:30-45 分钟,50,000-80,000 token,$0.25-0.40。细分分析:20-30 分钟,30,000-50,000 token,$0.15-0.25。用新数据更新:15-20 分钟,20,000-35,000 token,$0.10-0.18。
局限性:Claude Code 没有专有的市场数据。它使用公开可用的信息,这意味着估算可能比较粗略。对于高风险决策如融资或并购,用付费的分析师报告、调查或咨询顾问来补充。对于产品策略和内部规划,Claude Code 的结构化方法是足够的。
5.5 从行业趋势中区分信号与噪音
行业趋势塑造产品策略。AI 能力在进化,隐私法规在收紧,客户期望在变化。你需要追踪趋势、区分炒作与信号,并综合出对你的路线图的影响。这是一项受益于 Claude Code 综合与文档能力的调研工作。
从多个来源聚合趋势数据。趋势不是单篇文章,而是来源中的模式。你阅读分析师报告、技术博客、客户对话、会议演讲。将这些综合成连贯的趋势简报非常耗时。Claude Code 使其系统化。
创建一个趋势工作区:
mkdir -p research/trends
将来源(粘贴文章文本、复制报告段落、总结对话)收集到独立文件中:
research/trends/├── ai-tooling-gartner-2026.txt├── privacy-regulations-summary.txt├── customer-feedback-themes.txt└── saas-trends-2026.txt
然后让 Claude Code 进行综合:
提示词:趋势综合
审查 research/trends/ 中的来源文件,将关键主题综合到 research/trends/trend-brief-2026-01.md 中。
对于每个识别出的主要趋势:
- 趋势名称:简洁标签
- 描述:正在发生什么变化(2-3 句话)
- 证据:哪些来源支持这个?(引用具体文件)
- 时间:这是正在发生、即将发生还是远期发生?(1 年 / 2-3 年 / 3 年以上)
- 与我们的相关性:这对我们的产品影响如何?(高 / 中 / 低)
- 启示:我们应该考虑做什么?(2-3 条要点)
按相关性排序。限制为前 5-7 个趋势以避免简报过于冗长。
Claude Code 读取你的来源文件,识别反复出现的主题,并生成结构化的趋势简报。你得到的是综合,而不仅仅是汇总。
提示词模板:行业趋势综合。关键是将趋势与行动连接起来。
示例输出:
Trend: AI-Powered Productivity Features Becoming Table StakesDescription: Customers increasingly expect AI assistance built into products: autocomplete, suggestions, smart defaults. What was a differentiator 18 months ago is becoming an expected baseline feature across SaaS tools.Evidence:- Gartner report (ai-tooling-gartner-2026.txt) notes 67% of B2B buyers expect AI features- Customer feedback (customer-feedback-themes.txt) includes 12 mentions of "why doesn't this suggest..." or "competitors have AI for this"- SaaS trends report (saas-trends-2026.txt) lists AI features as top 3 investment areaTiming: Happening now. Customers are comparing products based on AI capabilities today.Relevance to us: High. We have minimal AI features and competitors are shipping them.Implications:- Evaluate which workflows would benefit most from AI assistance- Prioritize AI features that improve core workflows vs. novelty- Consider partnership vs. build-in-house for AI capabilities- Monitor customer churn related to "missing features" that might be AI-related
这将跨来源的点连接起来,使趋势变得可操作。你不仅仅是在报告"AI 很火"。你展示的是证据、时间线和对你产品的具体影响。
在趋势报告中区分信号与噪音。不是每个趋势都重要。有些是炒作。有些是真实的但与你的市场无关。有些重要但还很遥远。Claude Code 帮助你过滤。
提示词:趋势验证
审查 research/trends/trend-brief-2026-01.md 中的趋势。对于每个趋势,评估:
- 信号 vs. 噪音:这是有多个可信来源支撑的,还是只是某篇文章的猜测?
- 相关性过滤:这影响我们的目标客户细分,还是影响一个不同的市场?
- 紧迫性:我们需要在本季度、今年采取行动,还是只进行监控?
标记出那些看似缺乏实质内容的炒作趋势。建议哪些趋势值得立即考虑纳入路线图 vs. 长期监控。
这可以防止追逐每一个光鲜的趋势。你获得的是一份现实检查。"'万物皆可区块链'的趋势只在一个来源中出现,没有客户验证。建议降低其优先级。'隐私优先架构'的趋势出现在法规分析、客户反馈和竞争定位中,这是信号。建议进行路线图审查。"
创建可行动的趋势简报。输出成果应该驱动决策,而不是躺在文件夹里。将趋势简报结构化以便利益相关者阅读:
提示词:高管趋势摘要
基于 research/trends/trend-brief-2026-01.md,在 research/trends/trend-summary-exec-2026-01.md 中创建一页高管摘要。
格式:
- 我们必须响应的 3 大趋势:简要描述 + 建议采取的具体行动
- 需要监控的趋势:2-3 个新兴的、尚不紧迫的趋势
- 我们忽略的趋势及原因:1-2 个与我们无关的趋势
保持简洁可快速浏览。高管应能在 3 分钟内读完并理解其影响。
这将成为你的策略评审中的一张幻灯片、路线图规划中的参考文献或执行层团队的一份简报。它是面向行动的,而不仅仅是信息性的。
时间与成本:综合 5-8 个来源文档生成趋势简报:20-30 分钟,40,000-70,000 token,$0.20-0.35。从趋势简报创建高管摘要:10 分钟,15,000-25,000 token,$0.08-0.13。趋势分析周期总计:30-40 分钟,$0.30-0.50。
何时刷新:快节奏行业按季度,慢节奏市场按年度。当发生重大行业事件时临时触发(新法规、主要竞争对手动作、技术突破)。
局限性:Claude Code 综合的是你给它的内容。如果你的来源质量低或偏向某一视角,综合结果也会如此。输入垃圾,输出垃圾。将 Claude Code 的综合能力与多样化、可信的来源结合:分析师报告、客户调研、行业专家、竞争情报。
你现在可以使用 Claude Code 进行系统化的市场调研,生成可版本化、可更新的产出物,而不是生成即消失的一次性文档。第 6 章将类似的综合技术应用于客户反馈和 UX 调研:将原始反馈数据转化为可行动的产品洞察。
第6章
客户反馈与 UX 调研综合
6.1 反馈综合的挑战
你手头有上个季度的 847 张支持工单、200+ 条 NPS 回复、15 份客户访谈转录,还有一个用户每天发布功能请求的 Slack 频道。你的 VP 想要洞察。哪些主题正在浮现?我们应该优先处理什么?客户到底在告诉我们什么?
传统做法:通读所有内容,高亮看起来重要的东西,做一个带分类的电子表格,试图记住三个小时前读到什么,最后产出一份总结——其中 60% 是你清晰记得的内容,40% 是因为新鲜或戏剧性而在脑海中挥之不去的内容。这需要好几天时间,而且会遗漏分散在零散来源中的模式。
你需要系统化的综合:一致的分类、频次分析、主题之间的联系、每个洞察的支持证据。在规模上进行手动综合是不可靠的。你的记忆会优先筛选新鲜度和显著性,而不是实际的频次或重要性。你在阅读过程中理解加深,分类标准前后不一致。你会遗漏隐藏在大量数据中的微弱信号。
Claude Code 系统化了反馈综合。它读取你的所有数据,应用一致的分类标准,追踪频次,识别共同出现的主题,并生成带有支持引述的结构化报告。相同的分析方法论可重复执行。每季度的 NPS 分析每个季度都使用相同的流程,使结果具有跨期可比性。
体量问题:太多反馈,太少模式。随着你的产品增长,反馈体量会压倒手动分析。你需要处理成百上千个数据点来找到信号。Claude Code 穷举而非有选择性地处理数据。它读取全部 847 张工单,而不是抽样。它对全部 200 条 NPS 回复进行一致分类。
格式问题:数据分散在不同工具和格式中。反馈存在于 Zendesk、Intercom、Google Forms、电子邮件、Slack、销售电话记录、Twitter 提及中。不同格式,不同结构。综合首先需要将所有内容转化为可分析的形式:导出、转换、整合。Claude Code 原生支持多种文件格式:来自 Zendesk 的 CSV、来自 Intercom 的 JSON、来自访谈转录的纯文本、来自会议记录的 markdown。
优先级问题:什么最重要?原始反馈不会自带优先级评分。你需要识别什么频繁出现、什么造成实际痛苦而非轻微不便、什么阻塞工作流而非制造麻烦。综合揭示模式。15% 的反馈提到导出速度慢,这可能是客户礼貌地只提过一次的关键路径问题,而不是五个用户反复要求的响亮功能请求。
Claude Code 解决这些问题,每次综合会话花费 $0.40-0.90,耗时 30-60 分钟。对比两天的体力劳动,产出不一致且难以重复或更新的结果。
这种方法大材小用的情况:如果你只有 20 条反馈,自己读。如果反馈已经是高度结构化的(数值型问卷回复、是否题),用电子表格。Claude Code 的价值体现在你有大量非结构化的定性数据(文本反馈、访谈转录、开放式回复),其中模式识别需要真正读完所有内容。
6.2 为分析准备数据
Claude Code 读取文件,而不是直接读取数据库或 SaaS 工具。你需要将反馈数据导出为 Claude Code 可以处理的格式。这需要 10-20 分钟的设置工作,之后在未来的综合周期中就可以重复使用。
从常见来源导出数据:大多数反馈工具都提供 CSV 或 JSON 导出。具体操作因工具而异,但目标是相同的:将数据变成文件。
Zendesk:导航到 Reporting → Explore → Create report → Select tickets → Filter by date range → Export as CSV。导出包含工单主题、描述、评论、状态、标签、自定义字段。每行一个工单,所有交互历史拼接在一起。文件大小因评论量而异:1,000 个工单通常生成 5-15MB。
Intercom:Go to Reporting → Conversations → Export conversations → Select date range and filters → Download CSV or JSON。CSV 格式更简单,适合分析;JSON 包含更丰富的元数据,如果你需要的话。典型导出量:500 个对话 = 3-8MB。
问卷工具(Typeform、Google Forms、SurveyMonkey):都提供 CSV 导出。回复导出为每人一行,每个问题作为一列。开放式文本回复是你需要的:那些段落长度的答案列,而不是选择题。
NPS 工具:导出数值评分和"你为什么给出这个分数?"的文本回复。文本比数字对综合更有价值。你想要理解什么驱动了评分。
Slack:对于频道中的功能请求或反馈,将相关讨论串复制到文本文件中,或使用 Slack 的导出功能。格式不太重要。Claude Code 可以处理频道导出(JSON)或你粘贴对话的纯文本文件。对于小体量,手动复制粘贴到文本文件比搞清楚 Slack 的导出 API 更快。
访谈转录:如果你录制并转录了用户访谈,你可能已经拥有文本文件或 Word 文档。将 Word 文档转换为纯文本(.txt)或 markdown(.md)。Claude Code 两者都能处理。如果你使用 Otter.ai 或 Rev 等转录服务,导出为纯文本。
邮件反馈:将相关的客户邮件转发到一个文件夹,然后导出该文件夹。或者复制粘贴邮件到文本文件中,邮件之间用清晰的分隔符。格式:每个邮件讨论串一个文件,或一个合并文件,用类似 --- 的分隔符在邮件之间。
Claude Code 能很好处理的文件格式:
CSV 是结构化反馈的理想格式,有统一的字段。每行是一个反馈项(工单、问卷回复、NPS 评论)。列是属性(日期、客户姓名、反馈文本、类别、评分)。Claude Code 原生读取 CSV,可以按行系统化地分析。
JSON 适用于包含嵌套数据的更复杂导出。Intercom 导出包含对话讨论串、用户元数据、标签层级。Claude Code 解析 JSON 结构并提取相关字段。
纯文本(.txt)是通用格式。访谈转录、邮件讨论串、Slack 对话:任何内容都可以变成纯文本。最小限度地结构化,用空行或分隔符隔开每个反馈项。如果有用,可以内联添加基本元数据:"User: enterprise_customer_47 / Date: 2026-01-15 / Feedback: [text]"
Markdown(.md)类似纯文本但带有轻量级格式。用标题来区分反馈来源或访谈。对于你想保留发言者标签和问题结构的访谈转录很有用。
Claude Code 不能处理的:未经转换的二进制格式。Word 文档(.docx)、扫描文本的 PDF、手写笔记图片、音频文件都需要先转换为文本。对于 PDF,使用 PDF 导出工具提取文本。对于音频,使用 Otter.ai、Rev 或类似服务进行转录。
分析前清洗数据:你不需要完美的数据,但基本的清洗能改善结果。
移除 PII(个人身份信息)。客户姓名、电子邮件地址、电话号码、账户 ID:任何能识别个人的信息。替换为通用标签:"Customer_1"、"Enterprise_user"、"Trial_account"。你分析的是模式,不是追踪个人。移除 PII 可以防止意外暴露(如果你分享分析输出),并尊重隐私。
如果你的导出有"Name"列,将值替换为通用 ID。如果反馈文本中包含"Hi Sarah"或提到了电子邮件,进行查找替换或涂抹。Claude Code 不会自动清洗 PII。这是你在分析前要做的责任。
标准化文件内的格式。如果你的 CSV 有日期格式不一致(有些是"1/15/2026",有些是"January 15, 2026"),选择一种格式。如果有些反馈用花引号,有些用直引号,这没关系。如果回复混合了多种语言,注意这一点。Claude Code 处理多语言文本,但可能在跨语言分类时产生差异。
删除空行和非反馈数据。CSV 导出通常包含标题行、含导出元数据的尾部行,以及章节之间的空行。删除这些。每一行应该是一个反馈项。文本文件应该只包含反馈,不包含导出时间戳或系统消息。
隐私和 PII 注意事项:反馈数据是敏感的。客户分享意见是因为信任你会用来改进产品,而不是暴露他们的身份。
默认进行匿名化。除非你有特定需要按个人追踪反馈(客户流失风险分析、大客户高接触管理),否则移除身份信息。这使得分享综合输出更安全。你可以在 Slack 中发布主题报告或附加到 PRD 而无需担心隐私问题。
明确说明你在分析什么。如果你通过 API 使用 Claude Code,数据由 Anthropic 的系统处理,不会用于训练。如果你担心敏感反馈(医疗、金融、法律领域),查阅 Anthropic 的数据处理政策或考虑本地部署的替代方案。
不要分析客户在保密协议下提供的反馈。企业客户访谈通常包含 NDA 或保密协议。如果你承诺不将具体反馈对外分享,就不要将其放入数据管理方式你不太确定的系统中。如有疑问,排除该数据或咨询你的法务团队。
典型的准备工作流:
- 从源工具导出数据(多个来源 10-15 分钟)
- 在电子表格或文本编辑器中使用查找替换移除 PII(5-10 分钟)
- 清洗明显的数据问题——空行、格式不一致(5 分钟)
- 将文件保存到项目目录:feedback/2026-q1/,文件名带描述性,如 zendesk-tickets.csv, nps-responses.csv, interview-transcripts.txt
总准备时间:一次典型季度综合需要 20-40 分钟。这是每个综合周期的一次性工作。一旦数据准备好了,分析运行就很快。
数据量多大算太多?Claude Code 可以处理大文件,但 token 消耗随文件大小线性增长。一个包含 1,000 条反馈项(总共约 200,000-500,000 字)的文件完整处理花费 $1.00-2.50。将大型数据集拆分为较小的文件可以帮助管理成本。分别分析每个文件,然后汇总主题。
如果你有超过 2,000 条反馈项,考虑以下之一:- 抽样(分析随机子集,仍然比手动检查更系统化)- 批处理(按时间段或来源拆分,分别分析,然后对比)- 分层综合(按细分分别分析:企业 vs. SMB,新用户 vs. 老用户等)
对于典型的 PM 用例(季度综合、发布后反馈审查、路线图规划的主题分析),你通常处理 100-1,000 条反馈项。这在 Claude Code 的高效处理范围内。
6.3 在数百条回复中寻找模式
你已经准备好了反馈数据。现在需要提取主题:在你的数据中反复出现的主题、问题、请求和情绪。主题分析识别模式并量化每个主题出现的频次。
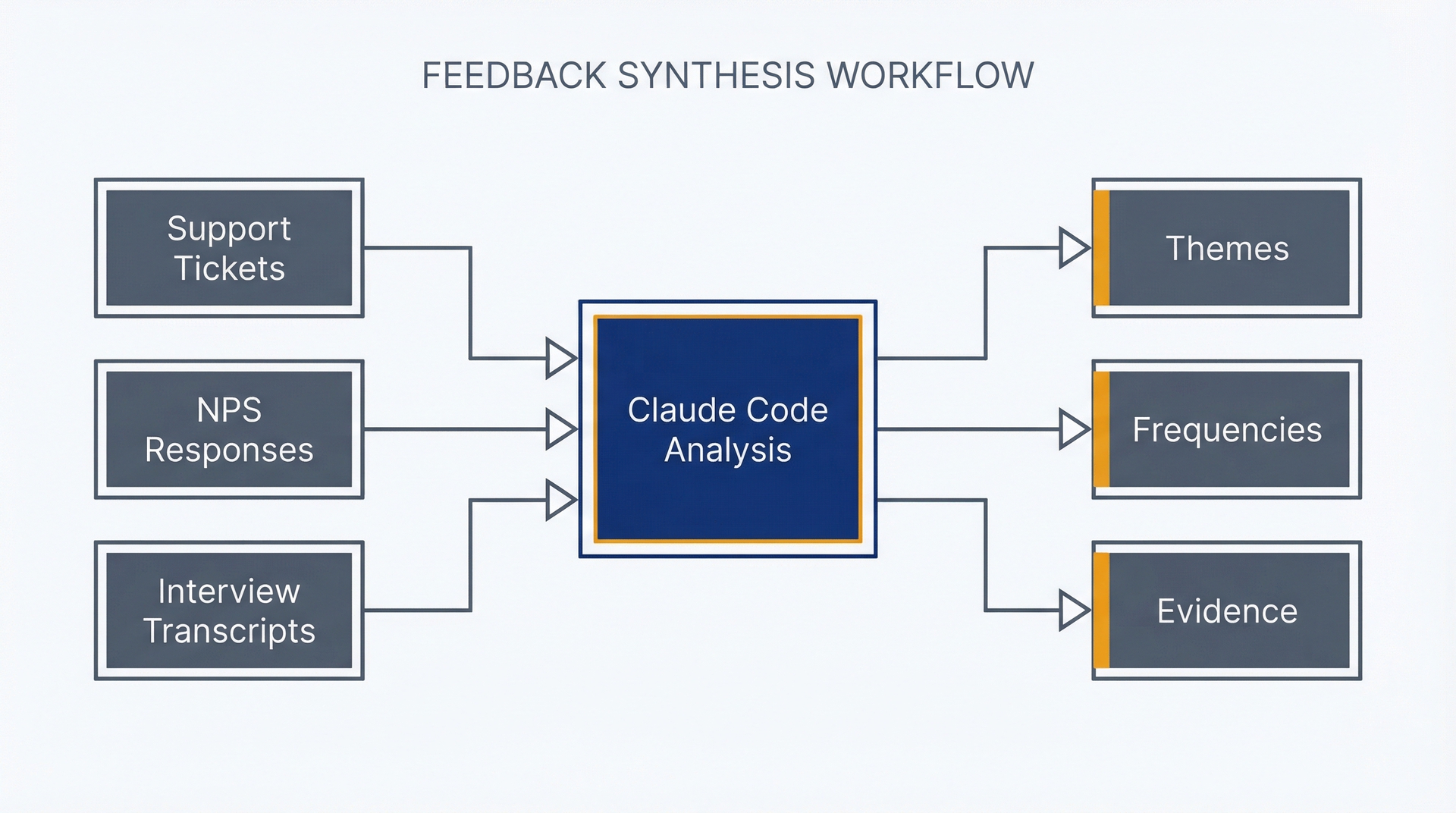
图 6.1:反馈综合工作流——使用此流程将分散的客户数据转化为可行动的洞察。原始数据源(支持工单、NPS、访谈)通过 Claude Code 分析,生成带有频次、情绪和支持证据的结构化主题。
提示词模板:反馈分类。从让 Claude Code 识别主题开始。如果你知道自己要找什么,可以预先定义类别;也可以让主题从数据中自然涌现。
以计划模式启动 Claude Code——你正在读取和分析,还没有写入文件:
claude --permission-mode plan
提示词:自然涌现主题识别
读取 feedback/2026-q1/ 中的所有反馈,识别反复出现的前 10-15 个主题。
对于每个主题:
- 主题名称:简洁标签(3-5 个词)
- 描述:这个主题代表什么(1 句话)
- 频次:有多少条反馈提到了这个主题
- 代表性引述:2-3 条说明这个主题的示例引述
按频次排列。除非代表关键问题,否则只纳入出现至少 5 次以上的主题。
Claude Code 读取你的反馈文件,识别反复出现的主题,计数出现次数,并提供结构化输出。你会得到类似这样的结果:
Theme: Slow Export PerformanceDescription: Users report that exporting large datasets takes too long or times out.Frequency: 87 mentions across tickets and NPS responsesRepresentative quotes:- "Tried to export 50k records and it timed out after 10 minutes. This is unusable for our reporting needs."- "Export feature is frustratingly slow. Takes 5+ minutes for medium-sized exports."- "Please fix export speed—this is blocking our monthly reports."## Theme: Missing Bulk Edit CapabilitiesDescription: Users want to edit multiple items simultaneously rather than one at a time.Frequency: 64 mentionsRepresentative quotes:- "I need to update 200 records with the same tag. Having to do this one-by-one is painful."- "Why can't I select multiple items and apply changes? This is standard in every tool we use."- "Bulk editing would save me hours per week."
定义类别:用户定义 vs. 自然涌现。你有两种分类方法。
自然涌现主题:让 Claude Code 识别数据中出现的内容,不带着预设的类别。这是探索性的;你会发现客户实际在谈论什么。当你对反馈主题没有强烈的假设,或者想验证你的预设类别是否匹配现实时使用这种方法。
预定义类别:给 Claude Code 提供具体的分类标准。当你已经建立了分类体系(功能请求、bug、可用性问题、性能投诉、文档缺口)并且希望随着时间推移对反馈进行一致的分类时使用这种方法。
提示词:预定义类别分类
读取 feedback/2026-q1/ 中的所有反馈,将每个反馈项分类到以下类别中:
- 功能请求
- Bug 报告
- 性能问题
- 可用性/UX 问题
- 文档缺口
- 集成需求
- 定价/计费问题
- 其他
对于每个类别:
- 统计有多少条反馈项属于该类别
- 列出该类别中被提到最多的前 5 个具体问题
- 提供 2-3 条代表性引述
如果一条反馈涉及多个类别,在每个适用类别中都计数。
这将产生一个结构化的分解,显示你收到了 127 个功能请求(前三大请求是 X、Y、Z),89 个 bug 报告(集中在 A、B、C 区域),64 个性能问题,等等。
使用哪种方法:自然涌现用于发现和验证。预定义用于一致性及跨时间段对比。你可以先使用自然涌现分析来建立类别体系,然后在未来季度将这些类别作为预定义分类体系来追踪主题分布的变化。
频次分析与优先级排序。原始频次很重要,但不是一切。10 条关于关键工作流阻塞的投诉可能比 50 条关于外观小毛病的投诉更重要。Claude Code 帮助你在频次之上叠加上下文。
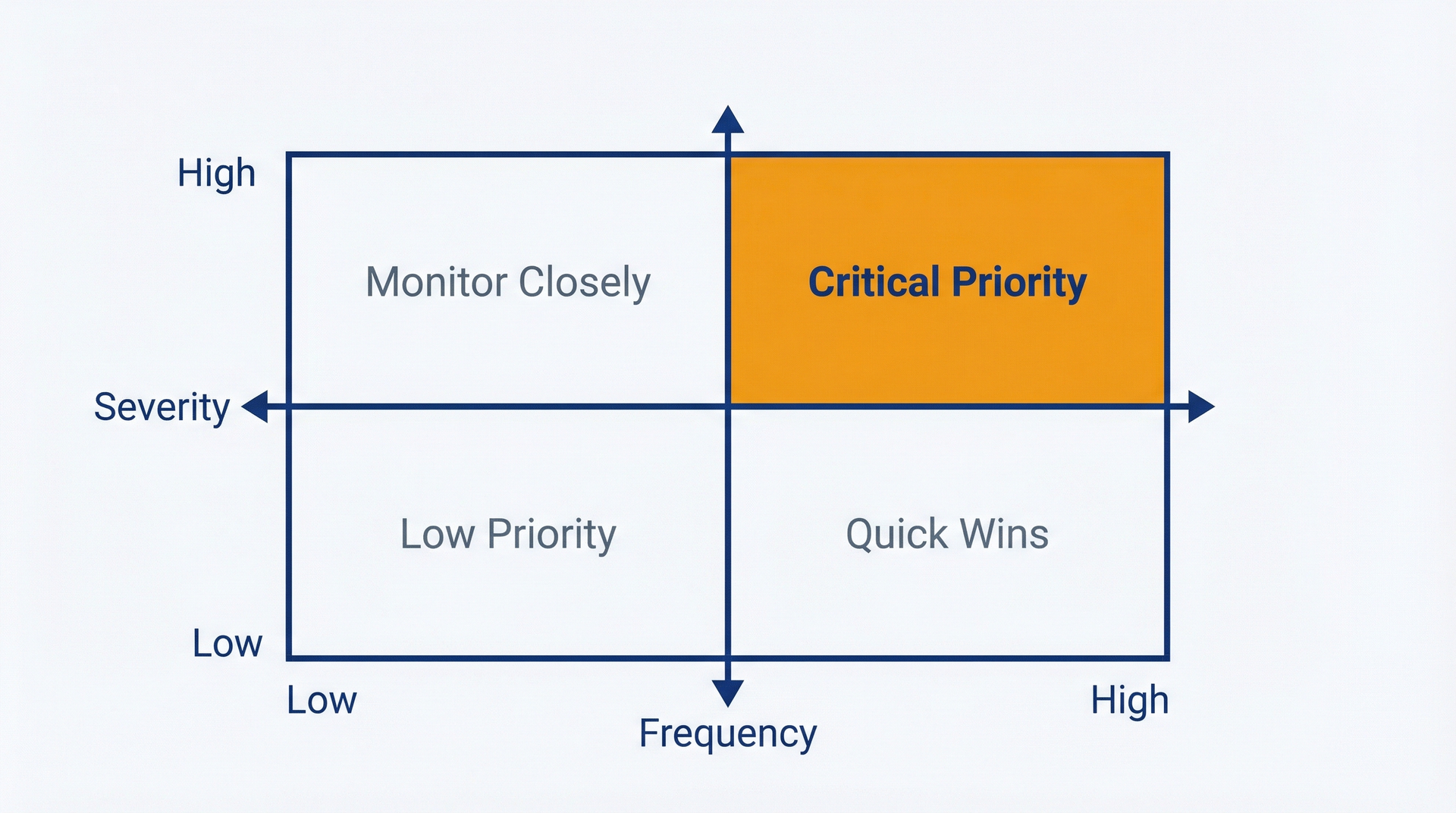
图 6.2:优先级矩阵——使用此矩阵识别哪些反馈主题需要立即关注。x 轴为频次,y 轴为严重性。高频次 + 高严重性象限(右上角)表示应驱动路线图决策的关键优先级项。
提示词:频次与影响分析
审查之前分析中识别出的主题。对于每个主题,评估:
频次层级:
- 高:超过 10% 的反馈项提到
- 中:5-10% 的反馈项提到
- 低:少于 5% 但仍值得关注
严重性信号(基于使用的语言):
- 严重:语言如"阻塞"、"无法完成工作"、"致命问题"、"正在考虑替代方案"
- 高:语言如"令人沮丧"、"耗时"、"痛苦"、"需要修复"
- 中:语言如"会很好"、"改进"、"建议"
- 低:语言如"小问题"、"不紧急"、"锦上添花"
创建一个优先级矩阵:频次 × 严重性。突出那些既频繁又严重的主题。
这会揭示"沉默杀手":很多客户用高严重性语言提到的问题,而你如果只追逐最大声的反馈可能会忽略它们。同时也能降低噪音的优先级,即很多人提到但用的语言影响程度低,说明这实际上并没有阻塞他们的工作。
在主题上叠加情绪分析。除了频次和严重性,你还需要了解情绪。客户对此是愤怒还是轻微烦恼?正常运行时会感激还是无所谓?
提示词:按主题的情绪分析
对于每个识别出的主要主题,分析提到该主题的反馈中的情绪:
- 正面:客户满意、赞扬、感谢
- 中性:事实性报告、无情绪的建议
- 负面:沮丧、失望、愤怒
- 混合:既有正面又有负面(例如,"很喜欢这个功能但性能太差")
提供情绪分布(例如,"Slow Export Performance: 5% positive, 15% neutral, 75% negative, 5% mixed"),如果数据中可见,注意不同客户细分中的情绪模式。
情绪揭示紧迫性。一个有 90% 负面情绪的主题无论如何都需要关注,无论频次如何。一个情绪混合的主题可能说明该功能在某些用例中运作良好但在其他情况下不适用——意味着需要针对性改进而不是全面变更。
输出格式:带支持引述的主题报告。综合输出应该简洁可操作。不是 50 页的文档,而是一个你可以在路线图规划中引用的结构化报告。
提示词:生成主题报告
基于主题分析,在 feedback/2026-q1/theme-report.md 中创建一份反馈综合报告。
结构:
- 高管摘要(1 段):按频次排前 3 的主题和按严重性排前 3 的主题
- 详细主题(每个主题一个章节):
主题名称和描述
- 频次及占总反馈百分比
- 严重性评估
- 情绪分布
- 代表性引述(3-5 条引述)
- 受影响的客户细分(如果可识别)
- 建议的行动或调查方向
- 交叉模式(1 段):经常共同出现的主题
- 微弱信号(要点列表):值得监控的低频主题
总报告控制在 6 页以内。优先考虑清晰度而非完整性。
Claude Code 生成结构化的报告文件。切换到普通模式以允许文件写入:
/exitclaude
再次运行提示词。Claude Code 将主题报告写入你的仓库。提交:
git add feedback/2026-q1/theme-report.mdgit commit -m "Add Q1 2026 feedback synthesis report"
主题分析的时间与成本:读取并分析跨多个文件的 500 条反馈项:20-30 分钟,60,000-120,000 token,$0.30-0.60。生成结构化主题报告:10-15 分钟,25,000-45,000 token,$0.13-0.23。完整主题综合总计:30-45 分钟,$0.45-0.85。
主题分析会失效的情况:如果反馈过于异质,每个客户想要的东西完全不同,主题就无法浮现。这意味着你的产品服务了太多用例,或者你的客户群体太过多样,无法进行有意义的综合。先按细分(行业、公司规模、用户角色)分组,然后分别分析各细分。
如果反馈极其稀疏(50 条反馈覆盖 30 个不同的主题),统计模式就不存在。直接手动读取反馈即可。主题分析在规模上增加价值,对小数据集没有意义。
如果反馈质量低(单字回复,只说"好/坏"而没有解释),就没有什么可以综合的。这是数据收集问题,而不是分析问题。通过改进问卷问题、访谈提纲和支持工单模板来提升反馈收集质量。
6.4 从访谈转录中提取洞察
反馈工单告诉你什么出了问题。UX 调研告诉你用户为什么挣扎以及他们试图完成什么。综合调研需要不同于反馈的技术。你是在分析叙事,而不是分类投诉。
分析访谈转录。用户访谈产生丰富的定性数据:故事、工作流、痛点、心智模型。综合从这些叙事中提取洞察。
准备转录:每个访谈一个文件,或一个带清晰分隔符的合并文件。一致地标注发言者(Interviewer: / Participant: 或 Q: / A:)。移除身份信息。
典型结构:
Interview with Enterprise_Customer_12Date: 2026-01-15Role: Operations ManagerCompany size: 500 employeesQ: Walk me through how you currently handle [workflow].A: We start by exporting data from our CRM, which is already frustrating because...[rest of transcript]
启动 Claude Code:
claude --permission-mode plan
提示词:访谈综合
读取 research/interviews/interview-[ID].txt 中的访谈转录,综合关键洞察。
提取:
- 痛点:什么让这个用户沮丧?什么出了问题或难以使用?(要点列表,附引述)
- 工作流:用户试图完成什么?他们的流程是什么?(叙事描述)
- 变通方法:他们使用什么技巧或替代工具来弥补不足?(要点列表)
- 心智模型:用户如何理解问题空间?他们使用什么术语?(段落)
- 未满足的需求:什么能让这个用户的工作更轻松?存在哪些缺口?(要点列表)
- 成功标准:这个用户如何定义该工作流的成功?(要点列表)
聚焦于用户所说的直接洞察,而非解读。用引述来支持每一点。
Claude Code 读取转录并生成结构化输出。你会得到带有支持引述的痛点、以用户原话描述的工作流,以及清晰表述的需求。
提示词模板:访谈综合。对于单个访谈,上述方法有效。对于多个访谈(来自一项调研研究的 10-20 份转录),你需要汇总:
提示词:多访谈综合
读取 research/interviews/ 中的所有访谈转录,综合跨访谈的模式。
对于以下每个类别,识别跨多个访谈出现的主题(不是个别的一次性提及):
痛点(反复出现的问题):
- 主题名称
- 有多少个访谈提到了这个(例如,"8 of 12 interviews")
- 来自 2-3 个不同访谈的代表性引述
- 基于使用语言的严重性评估
工作流模式(用户如何完成任务):
- 描述的常见工作流
- 有多少用户遵循这种模式
- 提到的变体或替代方法
未满足的需求(用户希望存在的东西):
- 需求描述
- 有多少用户表达了这一点
- 该需求产生的情境或用例
细分差异(如果适用):
- 注意任何按用户角色、公司规模、行业或其他可见细分不同的模式
按频次排序——聚焦于至少在 3 个访谈中出现的主题,除非某一次提及代表了一个关键洞察。
这产生跨访谈的模式。你会发现 12 个访谈中有 9 个提到了数据导出慢是一个痛点,7 个提到手动数据输入是缺乏集成的变通方法,5 个表示需要实时协作功能。
识别痛点和未满足的需求。两者的区别很重要:
痛点是对当前状态的不满:那些出错的、令人沮丧的、缓慢的、令人困惑的东西。这些对应着 bug、性能改进、可用性修复。例如:"导出太慢"是对你产品的痛点。
未满足的需求是缺口:用户想要但没有的东西。这些对应着功能请求、集成、工作流增强。例如:"我希望能在工具内直接给团队成员分配任务"是一个未满足的需求。
有时反馈同时表达两者:"我不得不手动复制数据到 Slack 来通知团队[痛点],这既耗时又容易出错。我希望有 Slack 集成[未满足的需求]。"
让 Claude Code 区分这些:
提示词:痛点 vs. 未满足的需求
审查调研综合,将洞察分类为:
- 痛点:需要修复的当前产品问题
- 未满足的需求:用户想要但目前不存在的功能
对于每一项,注意:
- 频次(有多少用户提到)
- 紧迫性(基于语言和上下文)
- 潜在解决方案(什么可能解决此问题)
这为路线图规划创建一个优先级列表。痛点进入 bug/性能待办列表;未满足的需求进入功能路线图。
从定性数据创建用户旅程地图。旅程地图可视化用户工作流并突出用户在哪里挣扎。Claude Code 不能画图,但它可以结构化旅程数据供你可视化或分享。
提示词:旅程地图数据
基于 research/interviews/ 中的访谈转录,为[具体工作流]过程创建结构化的用户旅程地图。
对于用户旅程的每个步骤:
- 步骤名称:用户正在做什么(动词短语:"Exporting data"、"Reviewing results")
- 用户目标:他们在这一步中试图完成什么
- 采取的行动:他们所做的具体事情(点击、输入、等待、切换工具)
- 痛点:在这一步中什么令人沮丧或困难
- 情绪状态:用户感受如何(基于使用的语言:frustrated, satisfied, confused, neutral)
- 使用的工具:涉及哪些系统/工具
- 机会:哪些改进可以提供帮助
以结构化列表或表格的形式输出,我可以转换为可视化的旅程地图。
Claude Code 生成结构化的旅程数据:
Step 1: Gathering Source DataUser goal: Collect all necessary data from multiple systems before analysisActions taken:- Export CSV from CRM (5-10 minutes wait time mentioned in 7 interviews)- Download spreadsheet from finance system- Copy-paste from email threads or Slack- Combine into master spreadsheet manuallyPain points:- "Exports are slow and sometimes time out" (9 interviews)- "Data formats don't match, have to reformat" (6 interviews)- "I never know if I have the latest data" (4 interviews)Emotional state: Frustrated ("tedious", "annoying", "waste of time" mentioned)Tools used: CRM system, finance ERP, Excel/Google Sheets, email, SlackOpportunities:- Speed up export performance- Standardize export formats- Real-time data sync instead of manual export- Unified dashboard eliminating manual gathering
你拿着这些结构化数据,在 Miro、Figma 或 PowerPoint 中创建可视化旅程地图。洞察工作已经完成。Claude Code 通过分析用户的表述来识别痛点、机会和情绪状态。
跨多个访谈汇总洞察。10-15 个访谈时,手动综合可行但耗时。20-30 个访谈时,手动综合不可靠。你读到后面的访谈时就会忘记前面访谈的细节。Claude Code 一致地处理所有访谈。
提示词:调研研究摘要
将 research/interviews/ 中的所有访谈综合为 research/study-summary.md 中的高管调研摘要。
包含:
- 调研概览:多少访谈、我们与谁对话(角色、细分)、我们问了什么
- 关键发现:跨多个访谈出现的前 5-7 条洞察(按频次和重要性排序)
- 痛点:用户面临的主要问题(按频次和严重性排名)
- 未满足的需求:主要的功能/能力需求(按频次排名)
- 细分洞察:按用户细分不同的模式(如果适用)
- 建议:基于发现建议的产品/设计行动(3-5 条要点)
- 支持证据:按主题组织关键引述的附录
目标长度:4-6 页。针对利益相关者的可读性进行优化。
Claude Code 生成一个你可以与领导层、设计和工程团队分享的综合文档。这成为驱动路线图讨论的产出物。
UX 调研综合的时间与成本:单份访谈分析:10-15 分钟,20,000-40,000 token,$0.10-0.20。多访谈综合(10-15 个访谈):30-45 分钟,80,000-150,000 token,$0.40-0.75。旅程地图数据提取:15-20 分钟,30,000-50,000 token,$0.15-0.25。
局限性:Claude Code 综合的是用户所说的内容,而不是他们的真实意思。它不能读取肢体语言,不能解读语调,也无法捕捉讽刺。它不理解你拥有但没有记录下来的上下文:用户明显感到困惑,通过长时间的停顿表现出沮丧,在讨论某个特定功能时眼睛发亮。人类研究员带来的解读是 Claude Code 不具备的。
用 Claude Code 做机械性工作:读取转录、识别反复出现的主题、统计频次、提取引述。用你自己的判断来做解读:理解用户为什么挣扎,什么才是真正重要的,哪些需求与产品愿景对齐。
6.5 从洞察到行动
没有行动的综合只是"研究表演"。你需要将洞察与决策联系起来:什么进入路线图,什么被优先处理,什么基于你学到的东西被降级。
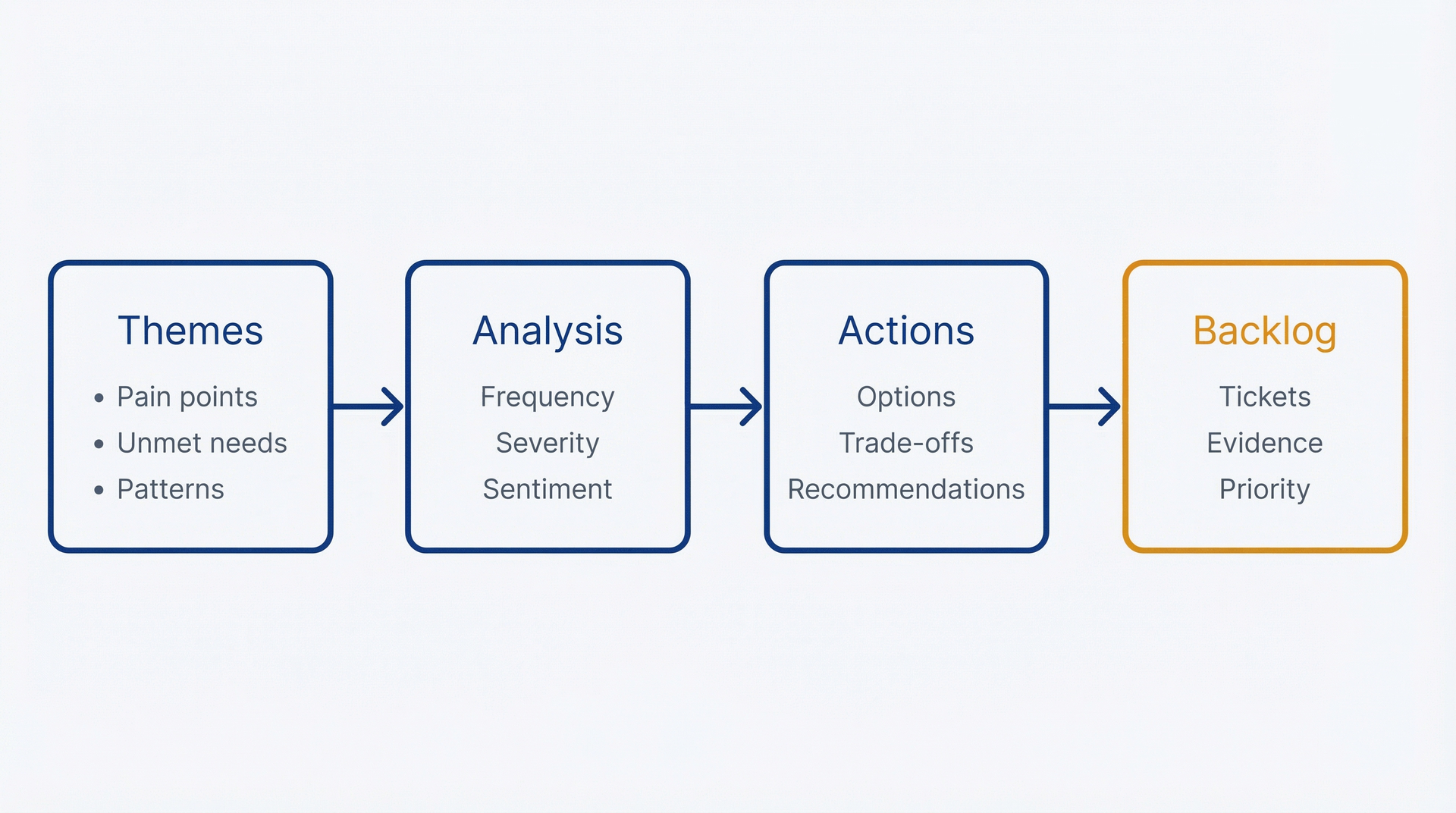
图 6.4:从研究到产出物的流水线——使用此流程将原始反馈转化为优先级排列的待办项,同时在关键决策点保持人工监督。流水线从原始数据(反馈、NPS、工单)经过 AI 分析(模式检测、主题)到人工判断关卡,PM 在此应用领域知识、业务上下文和优先级判断,然后生成经过验证的、可行动的待办项。
将反馈主题与产品决策关联。你综合中的每个主题都应该对应一个潜在的产品行动。不是每个主题都会成为路线图条目,但每个主题都值得被考虑。
提示词:洞察到行动映射
审查 feedback/2026-q1/theme-report.md 中的主题报告,将每个主要主题映射到潜在的产品行动。
对于每个主题:
- 主题:名称和简要描述
- 当前状态:我们今天做的(如果适用)
- 可能的行动:2-4 个解决此问题的选项(bug 修复、功能增强、新功能、流程变更、文档完善、不处理)
- 权衡:每个行动需要什么(工程工作量、设计工作量、时间、复杂度)
- 建议:考虑到频次、严重性和可行性,哪个行动最合理
对权衡要实事求是。不是所有事情都可以是 P0。有些可能是"监控但暂不行动"。
Claude Code 生成一份映射文档:
Theme: Slow Export PerformanceCurrent state: Export feature exists, works for small datasets (<10k records), degrades performance for larger datasets.Possible actions:1. Optimize existing export - Investigate and fix performance bottlenecks - Trade-offs: 2-3 weeks eng effort, might not solve for very large exports2. Implement async export: Move large exports to background processing with email notification - Trade-offs: 4-5 weeks eng effort, requires infrastructure changes, but scales to any size3. Add export limits: Cap export size and suggest alternative approaches - Trade-offs: Minimal eng effort, but doesn't solve user need4. Don't address: Accept that export is slow for large datasets - Trade-offs: None, but continued user frustration and potential churnRecommendation: Option 2 (async export). High frequency (87 mentions) and high severity justify the investment. Solves the root cause rather than papering over it. Aligns with enterprise growth strategy where large exports are expected.
这成为你路线图对话的基础。你不仅仅是说"用户想要更快的导出"。你是在呈现带权衡的选项和基于推理的建议。
提示词模板:洞察到行动映射。关键是从"我们了解到 X"转变为"因为 Z,所以我们应该做 Y。"
Claude Code 中的优先级框架。你有相互竞争的洞察、有限的工程资源、以及利益相关者的各种意见。优先级框架帮助你做出系统化的决策。
提示词:RICE 优先级排序
将 RICE 优先级框架(Reach × Impact × Confidence / Effort)应用于洞察到行动映射中识别出的潜在行动。
对于每个潜在行动,估算:
- Reach:这影响多少用户?(评分:1-10,10 = 大多数用户)
- Impact:这将多大程度上改善用户体验?(评分:3 = 巨大,2 = 高,1 = 中,0.5 = 低)
- Confidence:我们对 Reach 和 Impact 估算的信心程度?(评分:100% = 高信心,80% = 中,50% = 低)
- Effort:这需要多少工作量?(以人周评分:1, 2, 4, 8, 12)
计算 RICE 得分:(Reach × Impact × Confidence) / Effort
按 RICE 得分排列行动。标记出那些信心评分低、需要在排序前做更多验证的行动。
Claude Code 为每个潜在行动打分并排名。你获得数据驱动的优先级排序,而不仅仅是直觉。此框架使假设明确化。你可以争论某个功能的"Impact = 2"是否合适,但至少你是在争论具体问题,而不是模糊的"这个似乎很重要"。
替代框架:
Value vs. Effort 矩阵(比 RICE 更简单):> 对于每个行动,评定:> > - Value:用户影响 × 频次(高/中/低)> - Effort:工程复杂度和时间(高/中/低)> > 绘制在 2×2 矩阵上:> > - 高 Value + 低 Effort = 现在就做> - 高 Value + 高 Effort = 规划到下个季度> - 低 Value + 低 Effort = 锦上添花> - 低 Value + 高 Effort = 不做
Kano 模型(用于功能优先级排序):> 对于每个未满足的需求,分类:> > - Must-have:缺失会导致不满(痛点修复、关键缺口)> - Performance:越多越好(速度提升、容量增加)> - Delight:意想不到的、让用户眼前一亮的功能(新颖能力)> > 优先级:Must-haves 优先(基本门槛),然后是 Performance(竞争优势),最后是 Delight(差异化)
选择一个框架,系统化地应用,记录结果。你的路线图变得经得起推敲,因为你可以解释优先级排序逻辑。
创建由反馈驱动的待办项。综合结果输入你的待办列表。每个可行动的洞察变成一个工单:bug、功能请求、技术债、设计任务。
提示词:生成待办项
基于洞察到行动映射中优先级排列的行动,为前 5 个行动起草待办项。
对于每个行动,按以下格式创建工单:
- 标题:[简洁的、面向行动的标题]
- 问题:我们正在解决什么用户问题?(2-3 句话,引用综合发现)
- 证据:来自综合的支持数据(频次、严重性、代表性引述)
- 建议方案:我们正在考虑什么(高层次,不是详细规格)
- 成功标准:我们如何知道这解决了问题(最好可衡量)
- 估算工作量:粗略大小(小/中/大 或 T 恤尺码)
- 优先级:基于应用的优先级框架给出建议
- 相关反馈:链接到主题报告章节以获取完整上下文
Claude Code 生成你可以复制到 Jira、Linear 或你的待办工具中的草稿工单。你仍然需要完善(添加技术细节、与工程协调、根据其他因素调整优先级),但从调研到待办的连接是明确的。
示例待办项:
Title: Implement async export for large datasetsProblem: Users exporting large datasets (>10k records) experience timeouts and extremely slow performance, blocking their reporting workflows and causing frustration.Evidence: Q1 2026 feedback synthesis identified slow export as #1 pain point - 87 mentions across tickets and NPS responses (10.3% of all feedback). Severity assessed as high based on language ("blocking", "unusable", "considering alternatives"). Representative quote: "Tried to export 50k records and it timed out after 10 minutes. This is unusable for our reporting needs."Proposed solution: Move large exports (>5k records) to background processing. User initiates export, receives email when ready. Allows exports of any size without browser timeout constraints.Success criteria:- Users can successfully export 100k+ record datasets- Export requests complete within 10 minutes for datasets up to 100k records- Reduction in "slow export" support tickets by >70%- NPS score improvement among users who frequently exportEstimated effort: Large (4-5 weeks eng + infrastructure changes)Priority: P1 - High impact, high frequency, aligns with enterprise growth strategyRelated feedback: See feedback/2026-q1/theme-report.md section "Slow Export Performance"
这个工单将用户证据直接连接到工作。工程团队理解为什么这很重要。领导层看到调研基础。利益相关者可以引用实际数据来挑战假设。
洞察到行动的时间与成本:将主题映射到行动:15-20 分钟,25,000-40,000 token,$0.13-0.20。应用优先级框架:10-15 分钟,15,000-30,000 token,$0.08-0.15。生成待办项:10 分钟,15,000-25,000 token,$0.08-0.13。总计:35-45 分钟,$0.30-0.50。
这种方法会失效的情况:如果你的产品策略是高度主观的(创始人驱动的愿景、设计主导的创新),反馈综合可以起到参考作用但不能决定一切。不是每个客户需求都与你产品的方向一致。用综合来理解战略选择的影响,而不是让客户设计你的产品。
如果反馈是相互矛盾的——一半用户想要 X 而另一半想要相反的东西——综合能揭示冲突但无法解决它。这是一个细分问题。要么以不同的方式服务这两个细分,要么选择你为哪个细分构建产品。
如果你的待办列表已经超负荷且不可更改(已承诺的路线图、受监管行业、技术债占主导),综合会成为你无法做什么的记录,而不是你将做什么的文档。理解机会成本仍然是有价值的,但不要期望它能重塑优先级。
你现在可以系统化地综合客户反馈和 UX 调研,将其转化为可行动的产品洞察。你已经将 847 张支持工单和 15 份访谈转录从压倒性的噪音转变为带有支持证据、优先级评分和待办项的结构化主题。这一能力将你的 PM 工作流从被动救火转变为策略性的、以调研驱动的规划。
第 7 章将 Claude Code 应用于需求文档:创建存在于你的仓库中并与实现保持同步的 PRD、用户故事和用户画像。
第7章
需求、用户画像与文档
7.1 从零散研究中创建用户画像
你的利益相关者在路线图规划前需要用户画像。你手头有零散的研究资料:上季度的客户访谈、显示行为模式的分析数据、揭示痛点的支持工单、以及包含买家关注点笔记的销售电话记录。构建用户画像意味着将这些信息综合成连贯的用户原型。传统做法是:阅读所有资料,手动识别模式,将用户画像写成放在Google Slides中的演示文稿,被参考一次后就被遗忘。
Claude Code将用户画像创建为存放在仓库中的可版本化产物。你向它提供研究数据,指定哪些特征能让画像对你的产品上下文有价值,然后得到与你工作流集成的结构化画像文档。当工程师问"这个功能是为谁做的?"时,你可以指向仓库中的docs/personas/enterprise-admin.md。当画像基于新研究发生变化时,你更新文件并提交变更。画像不是一张静态幻灯片,而是活文档。
图7.1:用户画像生成工作流——使用此流程将零散的研究转化为结构化、可版本化的画像文档。研究来源(访谈、分析数据、支持数据)通过Claude Code分析,生成存放在仓库中、随产品演进的画像文件。
输入:研究数据、分析数据、现有知识。在生成画像之前,收集你对用户的了解。你不需要全面的研究,只需足够的信号来创建有用的用户原型即可。
需要收集的研究来源:- 访谈记录:用户调研会话、客户访谈、销售探索通话 - 分析数据:用户行为模式、功能采用率、工作流序列 - 支持数据:常见问题、痛点、具有不同问题的用户群体 - 销售情报:买家画像、决策标准、异议 - 现有知识:你和你的团队已经了解的用户类型
像准备反馈综合(第6章)一样准备这些数据。导出为文件,移除个人身份信息,组织到一个目录中:
mkdir -p research/persona-development
放置源材料:
research/persona-development/├── interviews-enterprise-users.txt├── analytics-summary.md├── support-ticket-themes.md├── sales-notes.txt└── existing-personas-critique.md
如果你有旧的画像,将其与关于哪些内容过时或不准确的笔记一起包含进来。Claude Code可以以此为起点进行改进。
提示模板:画像生成。启动Claude Code:
claude --permission-mode plan
先从分析开始,然后在具有写入权限的第二个会话中生成画像。
提示:画像分析
查看research/persona-development/中的研究材料,并基于以下维度识别不同的用户类型:
- 目标和动机:他们试图完成什么?
- 行为:他们如何使用产品或类似工具?
- 痛点:什么让他们感到沮丧或阻碍了他们的工作?
- 背景:公司规模、角色、技术技能、决策权限
从这些数据中能得出多少个不同的画像?对于每个潜在的画像:
- 是什么定义了这个用户类型?(2-3个关键特征)
- 这个细分群体有多大?(用户百分比或粗略估计)
- 有什么证据支持将其作为一个独立画像?(引用来源)
推荐3-5个涵盖我们主要用户类型、且不过度细分的画像。
Claude Code读取你的研究材料,识别模式,并提出画像。你会得到类似这样的结果:"三个不同的画像浮现出来:(1) Enterprise Admin,关注安全性和可扩展性的技术采购者,占用户的15%,但推动采购决策。证据:12次销售电话中有8次聚焦企业需求。(2) End User,关注易用性和日常工作流效率的个人贡献者,占用户的70%。证据:支持工单和访谈主要来自该群体。(3) Manager,管理团队使用情况,关注报告和可见性,占用户的15%。证据:功能请求和分析数据显示仪表盘/报告功能有不同的使用模式。"
审查提议的画像。它们是否与你的直觉相符?是否缺少某些群体?是否有应该合并的重叠?如果需要,通过后续提示来优化分析。
输出格式:结构化画像文档。一旦验证了画像集合,生成详细的画像文档:
退出plan模式,并以写入权限启动:
/exitclaude
提示:画像文档生成
基于画像分析,在docs/personas/中创建详细的画像文档。为每个画像生成一个markdown文件:[persona-name].md。
每个画像文档的结构如下:
- 概述
- 姓名和角色(虚构但有代表性)
- 一句话总结:他们是谁,关心什么
- 照片占位符:[描述,不需要实际图片]
- 人口统计信息
- 角色/职位
- 公司规模
- 行业(如相关)
- 技术技能水平
- 决策权限(采购者、影响者、最终用户)
- 目标和动机
- 主要目标(他们试图达成什么)
- 成功标准(他们如何衡量成功)
- 动机(驱动他们行为的因素)
- 痛点和挫折
- 当前挑战(在使用我们产品之前)
- 对现有解决方案的不满
- 工作流阻碍
- 行为和偏好
- 他们如何工作(工作流、工具、流程)
- 产品使用模式
- 沟通偏好
- 决策方式
- 对我们产品的需求
- 必备功能(决定性因素)
- 重要功能(高价值)
- 锦上添花功能(低优先级)
- 异议和顾虑
- 什么让他们对采用犹豫不决?
- 他们在评估过程中会问什么问题?
- 什么可能导致他们流失?
- 支持证据
- 研究中的关键引用(2-3条代表性引用)
- 验证该画像的数据点
- 来源参考
每个画像文档控制在2页以内。聚焦于可操作的洞察,而非人口统计细节。
Claude Code在docs/personas/中生成画像文件。每个画像成为一个参考文档,你可以从PRD、路线图讨论和功能规划中链接到它。
示例输出结构:
Enterprise Admin Persona: Sarah ChenSummary: IT administrator or security lead who evaluates and purchases tools for their organization. Cares about security, compliance, and scalability more than ease of use.## Demographics- Role: IT Administrator, Security Lead, or VP of Engineering- Company size: 500-5000 employees- Technical skill: High, comfortable with APIs, SSO, infrastructure- Decision authority: Primary buyer or strong influencer## Goals and Motivations- Ensure tools meet security and compliance requirements- Minimize risk of data breaches or regulatory violations- Evaluate total cost of ownership including support and maintenance- Standardize tooling across organization to reduce complexity## Pain Points and Frustrations- Tools that lack enterprise features (SSO, audit logs, role-based access)- Poor security documentation that delays evaluation- Hidden costs that appear after purchase (seat limits, API restrictions)- Vendor lock-in concerns with proprietary data formats## Behaviors and Preferences- Runs proof-of-concept trials before purchasing- Requests security audits, SOC 2 reports, penetration test results- Prefers self-service implementation over hand-holding- Values responsive support for technical issues## Needs from Our ProductMust-have:- SSO/SAML integration- Audit logging and activity monitoring- Role-based access control with granular permissions- SOC 2 Type II complianceImportant:- API access for integrations and automation- Data export capabilities (avoid vendor lock-in)- High availability SLAs- Priority supportNice-to-have:- Advanced security features (IP whitelisting, session management)- Dedicated account manager- Custom training for team## Objections and Concerns- "How do you handle data encryption at rest and in transit?"- "What happens if we need to migrate away?"- "Can we run this on-premise or in our VPC?"- "What's your security incident response process?"## Supporting EvidenceQuotes:- "We need full audit logs. If we can't prove who accessed what data and when, it's a non-starter." (Interview, Enterprise_Customer_12)- "SSO is table stakes. We're not managing another set of credentials." (Sales call, Q4 2025)Data:- 85% of enterprise deals stall on security review (sales pipeline data)- Enterprise admin personas represent 15% of users but 60% of revenue- Security-related feature requests cluster in this segment (support ticket analysis)
基于数据验证画像。不要因为AI生成了画像就盲目信任。根据你的认知进行验证:
提示:画像验证
审查生成的画像,并根据来源研究进行验证:
- 特征是否有实际数据支持,还是只是假设?
- 痛点是否与用户在访谈和工单中实际表达的一致?
- 群体规模在我们的分析数据中是否现实?
- 画像与实际用户行为之间是否存在矛盾?
标记出任何看起来是推测性的或缺乏充分支持的要素。
这能捕捉到Claude Code用听起来合理的细节填补空白、但这些细节并不基于你数据的情况。如果Enterprise Admin画像列出了"偏好电子邮件而非Slack",但你没有关于沟通偏好的证据,就删除它或将其标记为需要验证的假设。
将画像提交到你的仓库:
git add docs/personas/git commit -m "Add user personas based on Q4 2025 research"
画像开发的时间和成本。分析研究并识别画像类型:15-20分钟,30,000-50,000 tokens,$0.15-0.25。生成3-4个详细画像文档:20-30分钟,40,000-70,000 tokens,$0.20-0.35。总计:35-50分钟,$0.35-0.60。相比数天的手动综合和格式编排工作。
画像生成失败的情况。如果你的研究数据薄弱(访谈少、数据有限、信号弱),Claude Code会产生可以描述任何产品用户的通用画像。"Sarah希望工具易于使用并能提高生产力"——这不是可操作的洞察。这是数据问题,而非工具问题。在生成画像之前收集更多研究资料。
如果你的用户群极其多样化,没有清晰的群体划分,每个用户都想要不同的东西,那么画像就没有帮助。这表明可能存在产品-市场匹配问题,或者你正在采用试图服务所有人的功能工厂方法。按用例或垂直领域细分,而不是按用户类型。
画像更新频率。稳定市场每年一次。快速变化的产品每季度一次。当进入新市场领域或研究发现用户需求发生显著变化时更新。将画像视为活文档;版本控制展示了其随时间演进的过程。
7.2 从功能概念生成全面的用户故事
你有一个功能概念。利益相关者一致认为值得开发。现在你需要为工程团队编写用户故事:关于用户需要什么、为什么需要、以及如何判断是否成功的结构化描述。传统做法是:手动编写故事,安排一次细化会议,花一小时与工程师澄清模糊点,在实现过程中发现遗漏的边界情况。
Claude Code从功能概念生成全面的用户故事。你提供关于功能和目标用户的背景信息。Claude Code将其扩展为包含验收标准、边界情况和技术注意事项的故事——这些基于对你代码库的理解。故事并非最终版本(你仍需要与工程师一起细化),但它们是完成了80%的成果,而非从零开始。
从功能概念到用户故事。从你已知的信息开始:
- 你在构建什么功能?
- 它的目标用户是谁?(如果有画像则引用)
- 它解决什么问题?
- 它需要支持哪些关键工作流?
首先以plan模式启动Claude Code,探索代码库获取上下文:
claude --permission-mode plan
提示:功能上下文分析
我正在规划一个功能:[功能的简要描述]
在编写用户故事之前,帮助我了解技术上下文:
- 这个功能与哪些现有功能或代码区域相关?
- 这个功能需要访问什么数据?
- 我应该了解什么技术约束?(认证、权限、集成、性能考虑)
- 类似功能存在哪些边界情况?
这些上下文将为用户故事的创建提供参考。
例如,规划一个"批量用户导入"功能:
我正在规划一个批量用户导入功能,让管理员可以上传CSV文件来自动创建用户账号。
在编写用户故事之前,帮助我了解技术上下文:
- 目前用户创建是如何工作的?
- 创建单个用户时有哪些验证?
- 账号创建是否存在速率限制或约束?
- 如何处理重复的电子邮件地址?
Claude Code调查代码库并回复:"用户创建在src/services/user-service.js:78-156中实现。当前验证包括:邮箱格式、数据库中邮箱唯一性、密码强度要求、角色必须有效。重复邮箱会被拒绝并报错。目前用户创建没有速率限制,这对批量导入来说可能是个问题。类似的批量操作(批量项目创建)位于src/services/batch-operations.js,具备进度跟踪和错误报告功能。"
现在你知道了存在哪些约束、应该遵循什么模式、以及哪些边界情况很重要。
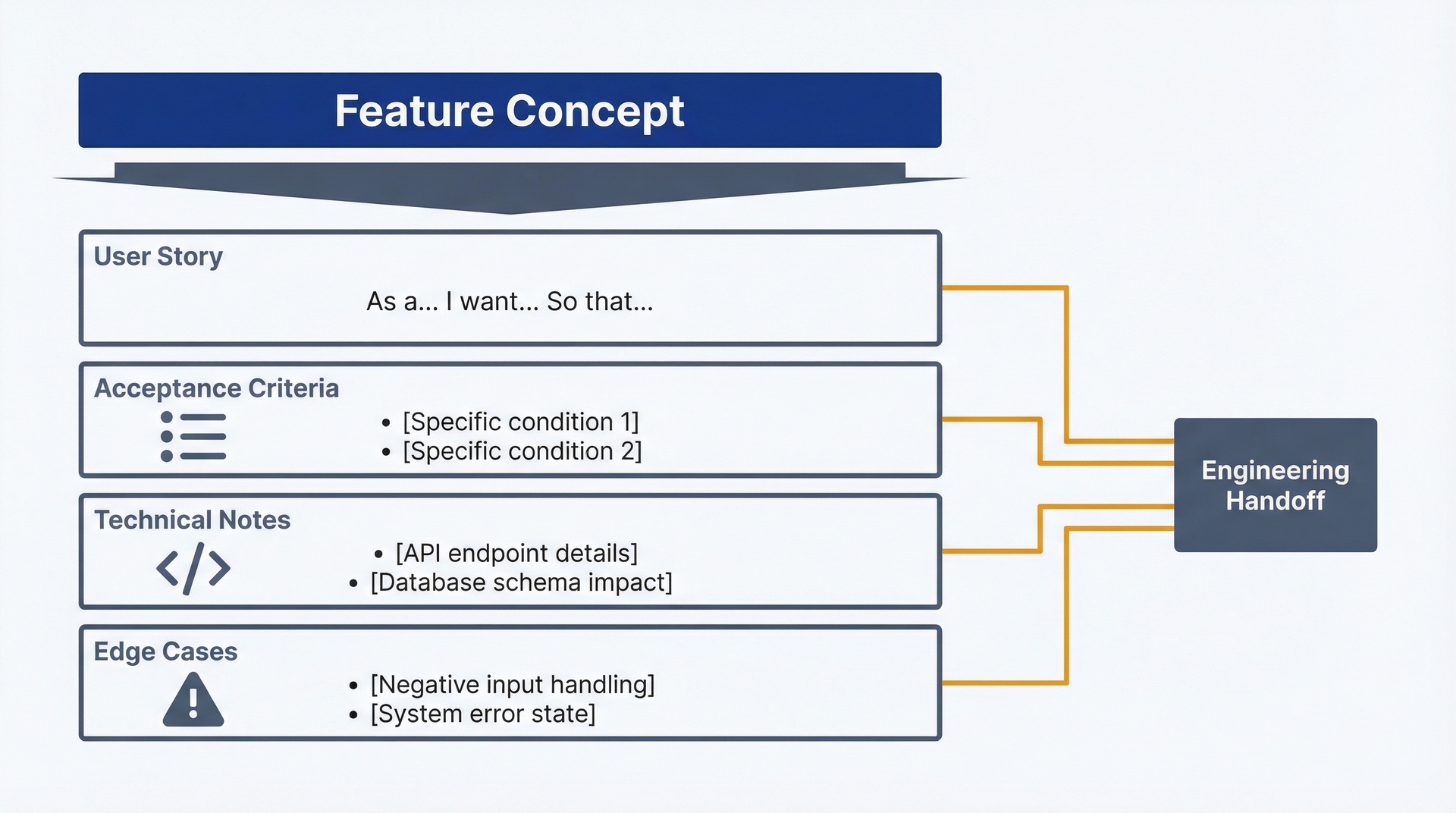
图7.2:用户故事剖析——使用此图理解功能概念如何扩展为全面的用户故事。展示了结构:用户故事格式(作为/我想要/以便于)、验收标准(可测试的需求)、技术说明(代码库引用、应遵循的模式)和边界情况(失败模式、边界条件)。
提示模板:用户故事展开。退出plan模式并以写入权限启动:
/exitclaude
提示:用户故事生成
为[功能名称]功能在docs/user-stories/[feature-name].md中生成用户故事。
功能描述:[2-3句话描述该功能]
目标画像:[画像名称或描述,例如"Enterprise Admin"或链接到docs/personas/enterprise-admin.md]
需要支持的核心工作流:1. [主要工作流] 2. [次要工作流] 3. [错误/边界情况工作流]
技术上下文:[来自你探索的结果摘要:现有模式、约束、相关功能]
按以下格式生成用户故事:
User Story: As a [persona], I want to [action], So that [outcome/benefit].
Acceptance Criteria: - [Specific, testable criterion 1] - [Specific, testable criterion 2] - [Edge case or error handling criterion]
Technical Notes: - [Implementation considerations from codebase context] - [Related files or patterns to follow] - [Constraints or dependencies]
Edge Cases: - [Scenario that could go wrong] - [Boundary condition] - [Error state]
创建5-8个涵盖核心功能、变体和边界情况的故事。按用户价值排序优先级。
Claude Code生成包含用户故事、验收标准和技术上下文的结构化文档。
批量用户导入的示例输出:
User Stories: Bulk User Import## Story 1: Upload CSV to Create Multiple UsersAs an Enterprise Admin,I want to upload a CSV file with user information,So that I can onboard multiple team members at once instead of creating accounts individually.Acceptance Criteria:- Admin can upload CSV file via file picker in admin dashboard- CSV format is documented with required columns: email, name, role- System validates CSV format before processing (rejects invalid files with clear error)- Success message shows number of users to be created before confirmation- Admin can review first 5 rows as preview before confirmingTechnical Notes:- Follow pattern from src/services/batch-operations.js for batch processing- Reuse validation logic from src/services/user-service.js:78-156- Consider file size limits (current upload limit is 10MB in config)- Store uploaded file temporarily for processing, clean up afterEdge Cases:- If CSV file exceeds size limit, reject with error message- If CSV has malformed rows, report which rows failed validation- If CSV contains 1000+ rows, consider async processing to avoid timeout## Story 2: Validate User Data Before ImportAs an Enterprise Admin,I want to see validation errors before users are created,So that I can fix issues in my CSV rather than partially importing bad data.Acceptance Criteria:- System validates all rows before creating any users- Validation checks: email format, unique email, valid role, required fields present- Validation errors list row numbers and specific issues- Admin can download error report CSV showing failed rows- No users are created if any validation fails (all-or-nothing)Technical Notes:- Extend existing validation from src/services/user-service.js- Check for duplicate emails both against database AND within the CSV- Role validation should match allowed roles from src/models/user.js:12-16Edge Cases:- If duplicate email exists in database, report as validation error- If multiple rows have same email in CSV, report as validation error- If role name has typo, suggest closest valid role if possible- If required field is missing, specify which column and row## Story 3: Track Import Progress and StatusAs an Enterprise Admin,I want to see progress while users are being created,So that I know the import is working and don't navigate away prematurely.Acceptance Criteria:- Progress indicator shows number of users created vs. total- Process doesn't block other admin dashboard usage- Admin can navigate away and return; progress persists- Completion notification appears when import finishes- Summary shows success count and any errorsTechnical Notes:- Use async batch processing pattern from src/services/batch-operations.js- Store import job status in database with progress tracking- Consider websocket for real-time progress updates or polling approach- Clean up completed jobs after 24 hoursEdge Cases:- If user navigates away mid-import, import continues in background- If import fails partway through, show partial success state and report which users were created- If database connection lost during import, retry failed users or fail entire batch?## Story 4: Handle Import Failures GracefullyAs an Enterprise Admin,I want to understand what went wrong if import fails,So that I can correct the issue and retry.Acceptance Criteria:- Error messages specify root cause (database error, validation, timeout)- Partial failures show which users were created successfully- Admin can download failed rows as CSV to fix and re-import- Failed import doesn't leave system in inconsistent state- Retry mechanism available for failed importsTechnical Notes:- Wrap user creation in database transaction if possible for atomicity- Log detailed errors to logs/import-errors.log for debugging- Reference existing error handling in src/services/user-service.js:142-156Edge Cases:- If database transaction too large, split into smaller batches- If rate limiting triggered by rapid user creation, implement throttling- If duplicate users created from retry after partial success, add idempotency check## Story 5: Send Welcome Emails to Imported UsersAs an imported user,I want to receive a welcome email with account setup instructions,So that I know my account was created and can log in.Acceptance Criteria:- Welcome email sent to each successfully created user- Email includes temporary password or password reset link- Email sending happens after all users created (don't spam if import fails)- Failed email sends are logged but don't fail the import- Admin can optionally suppress welcome emails for importTechnical Notes:- Use existing email service from src/services/email-notifications.js- Consider queue for sending emails to avoid blocking import completion- Follow email template pattern from src/templates/email/welcome.htmlEdge Cases:- If email service down, queue emails for retry; don't fail import- If some emails bounce, log bounces so admin can resend manually- If 500+ users imported, batch email sending to avoid rate limits[Additional stories for role assignment variations, audit logging, CSV template download...]
验收标准生成。验收标准将用户故事转化为可测试的需求。好的标准是具体、可衡量和可测试的。差的标准是模糊的:"用户可以轻松导入账号。"好的标准是:"管理员可以通过管理后台的文件选择器上传CSV文件"以及"确认前显示将要创建的用户数量的成功消息。"
Claude Code基于功能描述和代码库模式生成验收标准。审查并优化:消除模糊点,补充遗漏的情况,确保可测试性。
边界情况识别。Claude Code生成的用户故事的价值在于发现你可能遗漏的边界情况。它了解你的代码库约束(文件上传限制、验证模式、错误处理方法),并根据可能失败的情况提出边界情况:
- 如果文件太大怎么办?
- 如果存在重复邮箱怎么办?
- 如果导入过程中数据库连接失败怎么办?
- 如果邮件发送失败怎么办?
审查这些边界情况。有些可能过于谨慎。有些可能揭示你之前未考虑到的实际风险。用你的判断力来确定哪些边界情况需要在初始实现中处理,哪些留待未来迭代。
引用代码库获取技术约束。技术说明部分将故事与实现联系起来。"遵循batch-operations.js中的模式"告诉工程师去哪里找现有解决方案。"重用user-service.js中的验证逻辑"防止逻辑重复。"当前上传限制是10MB"设定了现实的预期。
这架起了产品与工程的桥梁。故事不是抽象的需求,而是基于你的系统实际运作方式而制定的。
提交用户故事:
git add docs/user-stories/git commit -m "Add user stories for bulk user import feature"
时间和成本。探索代码库获取技术上下文:10-15分钟,20,000-40,000 tokens,$0.10-0.20。生成全面的用户故事文档(5-8个故事):15-25分钟,30,000-60,000 tokens,$0.15-0.30。总计:25-40分钟,$0.25-0.50。
与工程团队进行细化。生成的故事是起点,不是最终规格。与工程团队一起审查:
- 技术说明是否准确?
- 边界情况是现实的还是过度设计的?
- 验收标准是否可测试?
- 缺少什么?
这种细化需要30-60分钟,但是从一个扎实的草稿开始,而不是从空白页开始。工程师花时间改进故事,而不是从零开始编写。
7.3 编写保持更新的PRD
产品需求文档处于两难境地:太重要而不能跳过,太繁琐而难以维护。你在Google Docs中编写PRD,分享以获取反馈,最终定稿,然后在实现过程中需求发生变化时从不更新。工程师构建了某些东西,PRD就过时了,未来的读者不知道是文档还是代码代表了真相。
解决方案不是更好的纪律,而是更好的存放位置。PRD应该作为markdown文件存放在你的仓库中,像代码一样进行版本控制。Claude Code帮助生成PRD各部分,保持与现有文档的一致性,并使需求与实现保持同步。
PRD作为仓库中的活产物。创建一个docs结构:
mkdir -p docs/prds
PRD变为markdown文件:docs/prds/bulk-user-import.md、docs/prds/api-rate-limiting.md、docs/prds/sso-integration.md。当需求变更时,你更新文件并提交。Git跟踪其演进过程。工程师直接引用该文件,没有会失效或需要权限申请的Google Doc链接。
提示模板:PRD各部分生成。PRD有标准的各部分。Claude Code基于你的研究、用户故事和代码库上下文来生成它们。
启动Claude Code:
claude
提示:PRD生成
为[功能名称]在docs/prds/[feature-name].md中创建一份PRD。
上下文:- 功能描述:[2-3句话] - 目标用户:[画像或用户类型] - 用户故事:参见docs/user-stories/[feature-name].md(如存在) - 相关研究:[如适用,链接到研究文档]
生成包含以下各部分的PRD:
- 概述 - 一段话总结:这个功能是什么,我们为什么要构建它? - 成功指标:我们如何衡量成功?
- 用户画像和用例 - 为谁而做?(如果有画像文档则引用) - 主要用例(3-5个场景)
- 需求
功能需求:- 功能必须做什么(按优先级排序:必备、应该具备、锦上添花)
非功能需求:- 性能、安全性、可扩展性、可访问性方面的考虑
- 用户体验 - 关键用户工作流(分步骤) - UI/UX考虑(界面、流程、交互)
- 技术方案 - 高层次技术设计 - 与现有代码的集成点(引用具体文件/区域) - 数据模型变更(如适用) - 第三方依赖
- 不在范围内 - 我们明确不做的事情(防止范围蔓延)
- 待解决问题 - 尚未解决的决策 - 需要进一步研究的领域
- 成功标准 - 发布标准:什么时候可以上线? - 成功指标:发布后什么样才算好?
- 时间线和里程碑(PM填写的占位符)
- 附录 - 链接到用户故事、研究、设计、相关文档
对于技术方案部分,分析代码库以识别:
- 我们应该遵循的现有模式
- 需要变更的文件或模块
- 潜在的技术风险或复杂性
PRD控制在6页以内。聚焦于清晰度和决策支持,而非详尽的细节。
Claude Code生成一份结构化的PRD。技术方案部分受益于代码库上下文:它引用实际文件、现有模式和实现约束,而非泛泛而谈的架构描述。
批量用户导入的PRD节选示例:
PRD: Bulk User Import## OverviewEnable enterprise administrators to create multiple user accounts simultaneously by uploading a CSV file, reducing onboarding time for large teams from hours to minutes.Success metrics:- 50% of enterprise customers use bulk import within first month of availability- Average time to onboard 50+ users decreases from 2 hours to under 10 minutes- Import success rate >95% (fewer than 5% of imports fail due to validation or errors)## User Personas and Use CasesPrimary persona: Enterprise Admin (see docs/personas/enterprise-admin.md)Use cases:1. New customer onboarding, provisioning accounts for entire team at once2. Seasonal hiring, adding interns or contractors in batches3. Department expansion, creating accounts for newly acquired team members4. Migration from competitor, importing existing user lists## Requirements### Functional RequirementsMust-have:- Upload CSV file with user details (email, name, role)- Validate CSV format and data before creating users- Show validation errors with specific row numbers and issues- Create all users atomically (all succeed or all fail)- Send welcome emails to imported users- Display import progress and completion status- Download error report for failed importsShould-have:- CSV template download with example data- Preview first 5 rows before confirming import- Audit log of import activity (who imported, when, how many users)- Option to suppress welcome emailsNice-to-have:- Support additional user fields (phone, department, manager)- Schedule imports for future date- Import existing users to update roles or details### Non-Functional Requirements- Performance: Handle CSV files up to 1,000 users without timeout (< 2 minutes processing)- Security: Validate admin permissions before allowing import, log all import activity- Reliability: Transaction-based import to prevent partial failures- Usability: Clear error messages that specify how to fix issues## User ExperiencePrimary workflow:1. Admin navigates to Users > Import Users2. Downloads CSV template (optional) to see required format3. Prepares CSV file with user data4. Clicks "Upload CSV" and selects file5. System validates file and shows preview of first 5 users6. Admin reviews and confirms import7. Progress indicator shows creation status8. Completion message displays results (success count, errors)9. Admin downloads error report if any validations failed10. Admin can fix errors in CSV and retryError state workflow:1. Admin uploads CSV with validation errors2. System displays error count and specific issues3. Admin downloads error report showing failed rows4. Admin fixes CSV and re-uploads5. System validates again until successful## Technical ApproachArchitecture:- Frontend: Add import UI to admin dashboard (src/client/components/Admin/UserImport.tsx)- Backend: Create import API endpoint (src/server/routes/users.js)- Service layer: Implement batch processing (src/services/user-import-service.js)- Follow existing batch operation pattern from src/services/batch-operations.jsKey technical decisions:1. CSV parsing: Use csv-parser library (already in dependencies)2. Validation: Extend existing user validation from src/services/user-service.js:78-1563. Batch processing: Process in batches of 50 users to avoid database connection limits4. Progress tracking: Store job status in user_import_jobs table, poll for progress5. Email sending: Queue emails using existing src/services/email-queue.js to avoid rate limitsIntegration points:- src/services/user-service.js - Reuse createUser logic- src/services/email-notifications.js - Send welcome emails- src/models/user.js - User model and validation- src/middleware/auth.js - Verify admin permissionsData model changes:- New table: user_import_jobs (id, admin_id, status, total_count, success_count, error_report, created_at)- Columns: id, admin_user_id, filename, status (pending/processing/completed/failed), total_rows, successful_rows, error_details (JSON), created_at, updated_atTechnical risks:- Database transaction size limit for 1,000 users: mitigate with batching- Email rate limiting: mitigate with queue and throttling- Large CSV file upload timeout: set appropriate limits and show progress## Out of Scope- Importing into multiple workspaces simultaneously (single workspace per import)- Updating existing user details via CSV (create-only for v1)- Importing group/team assignments (future enhancement)- Scheduled/recurring imports- Integration with HRIS systems for automated sync## Open Questions- Should partial success be allowed (some users created, some failed) or all-or-nothing? Decision needed from engineering re: transaction feasibility- What file size limit is reasonable? Current upload limit is 10MB; need to test how many users that represents- Should we support Excel files (.xlsx) or CSV only? CSV is simpler, covers 95% of use cases## Success CriteriaLaunch criteria:- Can successfully import 500 users in under 2 minutes- Validation catches all invalid data before creating users- Error reporting clearly identifies issues- Documentation includes CSV template and format requirements- Tested with real customer data (anonymized)Post-launch success:- 50% of enterprise customers adopt within 30 days- Support tickets about user creation decrease by 30%- Average onboarding time for 50+ user teams under 10 minutes## Timeline and Milestones[PM fills in sprint allocation, dependencies, launch date]## Appendix- User stories: docs/user-stories/bulk-user-import.md- Related research: research/feedback/enterprise-feature-requests.md- Competitive analysis: research/competitors/competitor-a-profile.md (has bulk import feature)- Design mocks: [Figma link when available]
与现有文档保持一致性。在生成PRD之前,让Claude Code检查相关文档:
是否有与[功能领域]相关的现有PRD、用户故事或技术文档?向我展示现有内容,并说明这份新PRD应该如何引用或与现有文档保持一致。
这能防止矛盾。也许另一份PRD以不同方式定义了用户角色,或建立了你应该遵循的模式。Claude Code可以确保一致性:"认证PRD在第3.2节中定义了管理员角色。在此引用该定义,而不是在此重新定义。"
需求文档的版本控制。提交PRD:
git add docs/prds/bulk-user-import.mdgit commit -m "Add PRD for bulk user import feature"
随着实现在需求演进,更新PRD并提交变更:
git commit -am "Update bulk import PRD: reduce scope to 500 user limit"
Git历史记录显示了什么发生了变化以及为什么。PRD成为反映实际决策的活文档,而非最初的猜测。
时间和成本。生成全面的PRD(6-8页):25-35分钟,50,000-80,000 tokens,$0.25-0.40。较小的功能花费更少,复杂的多组件功能花费更多。
何时PRD能增加价值。以下情况使用PRD:- 需要跨团队协调的功能(工程、设计、市场) - 具有多个集成点的复杂功能 - 涉及合规或安全影响的功能 - 在实现期间和发布后你都会引用的任何内容
以下情况跳过PRD:- 小型的bug修复 - 微小的UI调整 - 正在制作原型的实验性功能 - 只有单个利益相关者的内部工具
不要让文档开销取代对话沟通的作用。
7.4 保持产品文档与实现同步
产品经理传统上将文档视为与代码分离的东西:PRD在Google Docs中,发布说明在Confluence中,产品规格在Notion中。工程团队则以文档即代码的方式处理:仓库中的README文件、从代码注释生成的API文档、在版本控制中维护的变更日志。这种分离导致了漂移。产品文档描述的是应该存在的东西;代码代表的是实际存在的东西。
对PM来说,文档即代码意味着将产品文档与代码一起存放在仓库中。README文件、变更日志、API文档和产品指南以markdown文件的形式存在,进行版本控制,并作为正常工作流的一部分进行更新。Claude Code使其变得可行,它帮助你编写和维护这些文档,而不需要深入的技术知识。
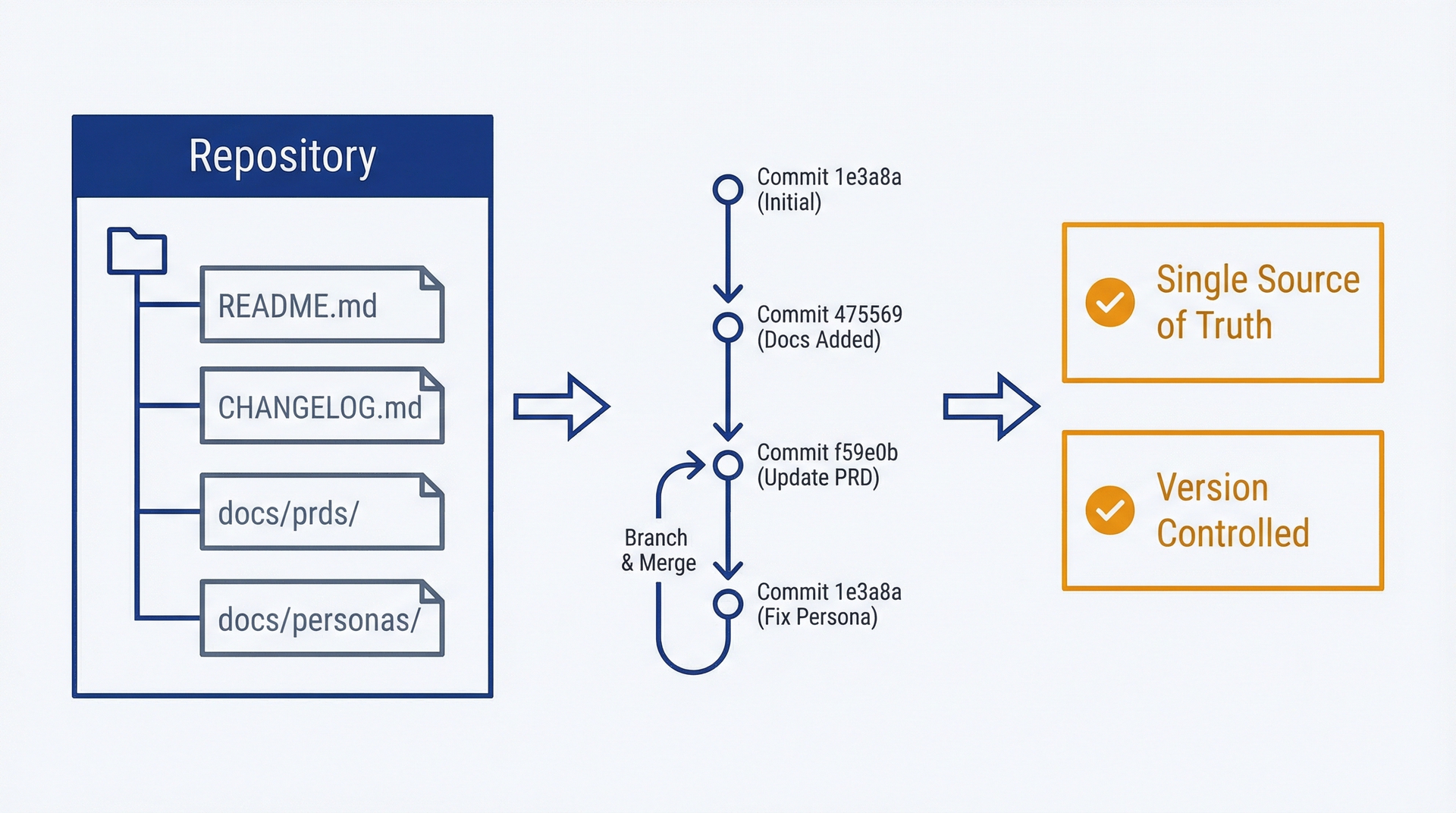
图7.4:文档即代码触发循环——使用此流程使产品文档与代码变更自动保持同步。展示了一个三阶段循环:工程合并代码(触发),Claude Code检测变更并更新文档(执行),PM审查并批准(审批)。该循环持续重复,使PRD、用户指南、变更日志和API文档始终与实现保持同步。
面向PM的文档即代码理念。核心原则:描述产品的文档应该与产品存放在一起。这并不意味着PM要写代码注释,而是说你拥有的产品知识以文件形式存在于仓库中:
- README.md——这个产品是什么,如何上手
- CHANGELOG.md——每个版本中发生了什么变化
- docs/——产品文档、用户指南、操作指南
- docs/api/——API文档(你协作,工程负责实现)
- docs/prds/——需求文档
- docs/personas/——用户画像
这种方式的好处:
唯一真实来源。仓库包含了一切。无需在Google Drive、Confluence和Notion之间寻找分散的文档。
版本控制。文档随产品一起演进。Git历史记录显示了何时发生了变化以及为什么。
接近代码。工程师在工作时看到产品文档。PM在规划时看到技术文档。跨职能的上下文感知增强了。
自动化工作流。Pull request可以同时包含代码变更和文档更新。CI可以检查当功能变更时文档是否已更新。
README更新和变更日志维护。README通常是用户看到的第一样东西。借助Claude Code保持其更新:
提示:README更新
审查并更新README.md以反映产品最近的变更。
当前状态:[简要总结发生了什么变化:新功能、移除的功能、重命名的概念]
更新以下部分:
- 概述:确保功能列表是最新的
- 快速开始:验证安装/设置步骤是否仍然准确
- 核心功能:添加最近的新增内容,移除已弃用的功能
- 配置:如果存在新的配置选项则更新
对新用户保持语气清晰和友好。移除过时信息。
变更日志记录了每个版本中发生的变化。手动维护它们很繁琐。Claude Code可以从git历史中生成变更日志条目:
提示:变更日志生成
通过审查自[上个版本标签]以来的git提交,为版本[X.Y.Z]生成变更日志条目。
格式:
[X.Y.Z] - YYYY-MM-DD### Added- [新功能]### Changed- [现有功能的变化]### Fixed- [Bug修复]### Removed- [已弃用或移除的功能]
聚焦于面向用户的变化。忽略内部重构或代码清理,除非它们影响用户。使用产品语言,而非技术术语。
Claude Code读取提交信息,识别面向用户的变化,并生成结构化的变更日志条目。你审查并编辑以确保准确性和语气适当,然后提交。
API文档贡献。如果你的产品有API,文档就很重要。工程通常负责实现,但PM贡献上下文:端点用于什么目的、服务于什么用例、常见的集成模式。
Claude Code可以帮助编写或改进API文档:
提示:API文档增强
审查docs/api/users.md中关于用户管理端点的API文档。
增强以下内容:
- 用例上下文:开发者什么时候会使用这个端点?
- 常见模式:在集成工作流中通常如何使用?
- 错误处理指南:可能出现什么错误以及如何处理?
- 示例:真实世界的请求/响应示例及说明
保持技术准确性——参考src/server/routes/users.js中的实际API实现来验证端点行为。
你在为技术文档添加产品上下文。工程确保请求/响应模式的准确性;你确保开发者理解为什么以及何时使用该API。
保持产品文档与实现同步。文档即代码的风险与任何文档相同:它会过时。通过流程来缓解这个风险:
在sprint规划期间审查文档。当规划影响面向用户行为的功能时,将"更新文档"作为用户故事中的验收标准。
将PR链接到文档更新。添加功能的工程PR应包含README或变更日志更新。将其作为审查清单的一项。
定期文档审计。每季度,让Claude Code审计文档与实现的一致性:
提示:文档审计
审查docs/中的文档并与当前代码库进行比较。
识别:
- 文档中记录的但已不存在的功能(代码已被移除)
- 存在但未记录的功能
- 文档中与实际配置文件不匹配的配置选项
- 过时的示例或截图
创建一份使文档与实现同步所需的文档更新列表。
Claude Code读取文档和代码,识别漂移,并生成待办列表。你排定优先级并修复最重要的差距。
示例工作流:为功能发布更新文档。你即将发布批量用户导入功能。在发布之前,确保文档准备就绪:
- 更新README:将"批量用户导入"添加到功能列表
- 更新变更日志:为包含此功能的版本添加条目
- 创建用户指南:编写
docs/guides/bulk-user-import.md,包含分步说明 - 更新API文档:如果导入使用API,在
docs/api/中记录端点 - 更新管理员指南:添加关于用户管理及导入的章节
Claude Code帮助完成每一项:
在docs/guides/bulk-user-import.md中为批量用户导入功能生成用户指南。
包含:
- 批量导入是什么以及何时使用
- 分步说明及截图占位符:[Screenshot: Upload CSV button]
- CSV格式要求和模板下载链接
- 常见问题排查(验证错误、文件格式问题)
- 常见问题解答部分
语气:清晰且有帮助。假设读者是具备中等技术技能的管理员。
审查生成的指南,添加实际截图,亲自测试说明以确保准确性,然后提交。
时间和成本。README更新:5-10分钟,10,000-20,000 tokens,$0.05-0.10。从git历史生成变更日志:10-15分钟,15,000-30,000 tokens,$0.08-0.15。创建用户指南:20-30分钟,30,000-60,000 tokens,$0.15-0.30。文档审计:15-25分钟,25,000-50,000 tokens,$0.13-0.25。
文档即代码不适用的场景。有些文档适合放在仓库之外:
- 营销内容(产品页面、落地页)存放在CMS或营销工具中
- 面向最终用户的支持文章存放在帮助台软件(Zendesk、Intercom)中以获得搜索和分析能力
- 销售资料存放在销售赋能工具中
- 长篇幅内容(如此书)更适合使用专门的创作工具
文档即代码适用于:- 技术文档(设置、API、架构) - 面向开发者的内容 - 随代码变化的产品知识(功能、配置、工作流) - 供团队使用的内部文档
根据受众和更新频率选择存放位置。随代码变化的文档放在仓库中。独立变化的文档放在专用工具中。
现在你可以使用Claude Code从研究数据中生成用户画像,创建包含验收标准和边界情况的全面用户故事,生成作为版本控制产物的PRD,并维护与实现同步的产品文档。这些能力将文档从你回避的繁琐任务转变为你作为正常工作流一部分来创建的集成产物。
第8章从单个文档转向可重复的工作流——构建将你的PM流程编码化以便持续一致执行的技能。
第8章
技能剖析——结构与设计模式
8.1 从临时提示到可重复的工作流
这个季度你已经综合了五次客户反馈。每次都是打开Claude Code,输入同一提示的变体,等待结果,意识到忘了指定输出格式,迭代调整,得到能用的东西,然后继续。下个月,你又会再来一次。你不会记得具体什么好用,会花20分钟重新摸索出正确的提示结构。输出结果会和上次略有不同,使得跨季度的比较更加困难。
这就是提示跑步机。你不断重复做同样的工作,却没有从重复中获得复利价值。技能解决了这个问题。
技能是一个文档化的工作流,Claude Code按需执行。你一次性地定义流程:需要什么输入,遵循什么步骤,产生什么输出,什么样算质量合格。然后你按名称调用它。Claude Code按照你文档化的流程执行,产生一致的结果,无论距离你创建它过去了多长时间。
复利价值是显著的。第一次季度反馈综合需要45分钟,包括提示迭代。有了技能,第二次只需10分钟。第三次也是10分钟。到第四个季度,你节省了两小时的工作时间,并且获得了跨时间段的一致性,使趋势分析成为可能。
本章涵盖技能结构和设计模式。第9章提供完整的示例,并手把手带你构建你的第一个技能。掌握这两章,你就能将重复的PM任务从认知负担转化为可靠的流程。
8.2 什么是技能?
技能是一个告诉Claude Code如何执行特定工作流的markdown文件。它存放在项目的.claude/skills/目录(通过git与团队共享)或~/.claude/skills/(个人的,跨所有项目可用)中。当你调用一个技能,或者当Claude Code识别到你的请求与某个技能的描述匹配时,它会遵循文档化的指令,而非即兴发挥。
技能与提示:区分很重要。提示是一次性的指令。你输入它,Claude Code响应,然后提示就消失在会话历史中了。如果你想下周做同样的事,你需要重新写提示(或者翻找历史记录,希望记得你是什么时候运行的)。
技能是持久化的指令集。它以文件形式存在,像其他项目产物一样进行版本控制。当你下周运行该技能时,它执行的是相同的文档化流程。当团队成员运行时,他们获得一致的行为。当你更新技能时,每个人都从改进中受益。
区别在于持久性和可重复性:
| 方面 | 提示 | 技能 |
|---|---|---|
| 持久性 | 仅限当前会话 | 仓库中的文件 |
| 可重复性 | 需要回忆 | 按名称调用 |
| 一致性 | 每次不同 | 文档化的流程 |
| 可共享性 | 复制粘贴 | Git提交 |
| 演进 | 丢失于历史中 | 版本控制 |
技能存放位置。Claude Code在两个位置查找技能:
- 项目级别:当前目录中的
.claude/skills/。这些技能是项目特定的,与克隆仓库的团队成员共享。用于与产品绑定的技能:针对你特定数据格式的反馈综合、针对你仓库规范的发布说明、针对你团队检查清单的PRD审计。
- 个人级别:主目录中的
~/.claude/skills/。这些技能跟随你跨所有项目。用于通用的PM工作流:竞品分析模板、用户故事展开模式、会议笔记综合。
每个技能是一个子目录,至少包含一个文件:SKILL.md。目录名成为技能的标识符。复杂的技能可以包含额外的文件:辅助脚本、参考文档、输出模板。
.claude/skills/├── feedback-synthesis/│ └── SKILL.md├── release-notes/│ ├── SKILL.md│ └── resources/│ └── customer-voice-guide.md└── prd-audit/ ├── SKILL.md └── resources/ └── prd-checklist.md
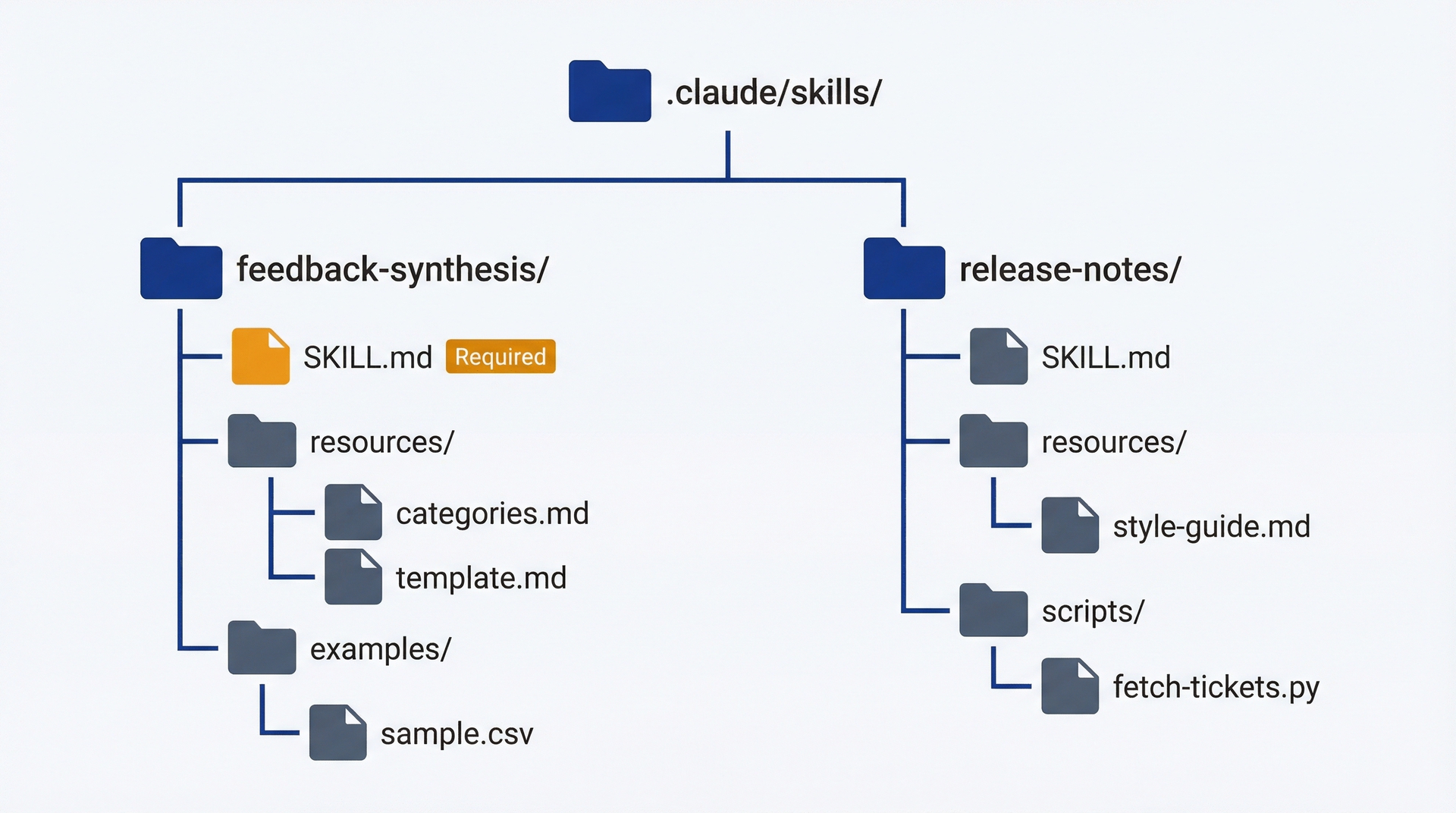
图8.1:技能目录结构——使用此图来组织你的技能,包含必需的SKILL.md文件和可选的辅助资源、脚本及示例文件夹。
技能如何被发现和调用。Claude Code使用技能描述来判断相关性。当你发出请求时,Claude会读取每个技能YAML前置信息中的description字段,并判断是否有任何技能适用。如果你提供反馈CSV并要求"将其综合为主题",Claude Code会匹配一个描述中提到"反馈综合"的技能并自动激活它。
你也可以将技能作为斜杠命令显式调用。名为feedback-synthesis的技能变为/feedback-synthesis。这种显式调用保证技能会运行,无论你如何措辞你的请求。
自动发现行为很有用,但并非魔法。如果你的技能描述不包含用户实际会说的话,Claude Code就不会匹配。"分析客户情感数据"不会在你输入"总结这份反馈"时触发。包含与自然请求匹配的触发词:"综合客户反馈、NPS回复、支持工单主题"。
技能的复利价值。第一次构建一个技能需要30-60分钟。使用一个技能需要5-10分钟。算账很简单:
- 使用2次:构建60分钟 + 使用20分钟 = 总共80分钟,对比临时方式的90分钟
- 使用5次:60 + 50 = 110分钟,对比临时方式的225分钟
- 使用10次:60 + 100 = 160分钟,对比临时方式的450分钟
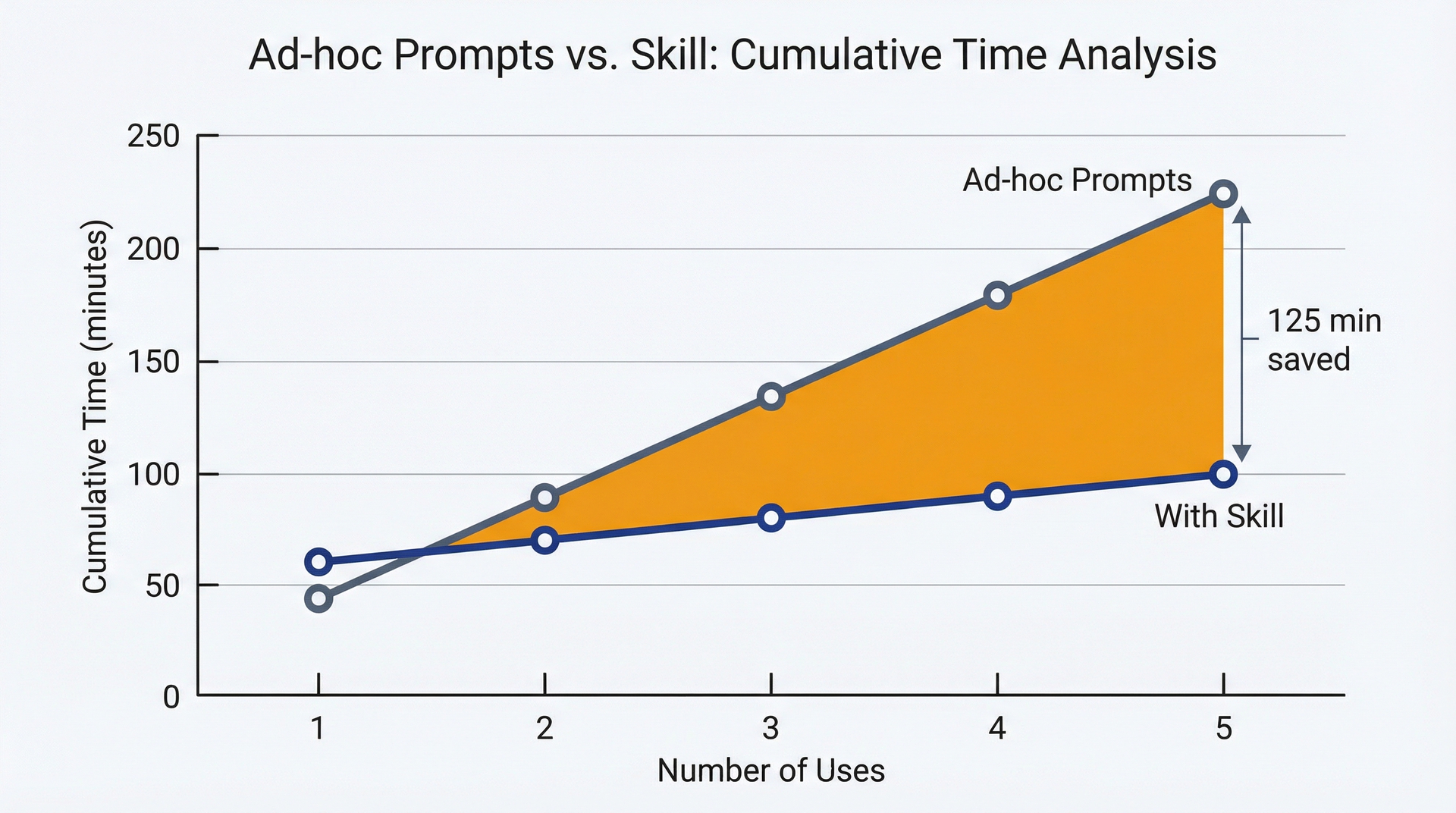
图8.2:技能复利价值——使用此图为构建技能的初始投资提供理由。临时提示呈线性增长(每次使用45分钟),而技能有更高的初始投入(构建60分钟),但平摊到每次使用仅10分钟。到第五次使用时,技能相比临时方式节省125分钟。
除了时间节省,技能还提供一致性。季度报告遵循相同的结构。反馈主题使用相同的分类标准。PRD审计检查相同的项目。这种一致性使得跨时间段的比较成为可能,并降低了输出成果消费者的认知负担。
8.3 技能组件
一个技能目录包含若干类型的文件。只有SKILL.md是必需的;其他文件为复杂工作流扩展能力。
SKILL.md:指令文件。这是每个技能的核心。它包含用于发现的YAML前置信息和用于执行的markdown指令。Claude Code在技能激活时读取此文件,并遵循文档化的流程。
最小可行SKILL.md:
---name: standup-notesdescription: Generate standup notes from yesterday's git commits. Use when user mentions standup, daily update, or what I did yesterday.---# Standup Notes## PurposeCreate formatted standup notes from recent commits.## Inputs- Git repository with commit history## Process1. Read commits from the past 24 hours2. Group by type (feature, fix, refactor)3. Write in first person, past tense## OutputPrint standup notes to terminal. Do not create a file.
这个最小结构适用于简单的工作流。更复杂的技能需要第8.3节中涵盖的额外部分。
参考文件:数据、评分标准、模板。技能可以包含Claude Code在执行过程中查阅的辅助文件。这些文件存放在resources/子目录中:
feedback-synthesis/├── SKILL.md└── resources/ ├── category-definitions.md ├── output-template.md └── quality-rubric.md
参考文件服务于多种目的:
- 分类定义:当综合反馈时,Claude Code应该使用什么分类?一次性在
category-definitions.md中定义它们,而不是嵌入到SKILL.md指令中。
- 输出模板:生成产物的精确结构。"遵循
resources/output-template.md中的模板"比将模板嵌入到指令中更清晰。
- 质量标准:评估输出的详细标准。使SKILL.md聚焦于流程,而将评估标准委托给一个参考文件。
- 风格指南:语气、语调和格式偏好。对生成面向客户内容的技能很有用。
在你的SKILL.md中,显式引用这些文件:"使用resources/category-definitions.md中的定义对反馈进行分类。"Claude Code会在到达该指令时读取被引用的文件。
输出模板:一致的格式。如果你的技能产生文档,定义预期结构:
Output FormatGenerate file: reports/feedback-synthesis-[date].mdFollow this structure:# Feedback Synthesis: [Date Range]## Executive Summary[3-5 bullet points of key findings]## Theme Analysis### Theme 1: [Name]- Frequency: [count] mentions ([percentage]%)- Sentiment: [positive/negative/mixed]- Representative quotes: - "[Quote 1]" - "[Quote 2]"- Implications: [What this means for the product][Repeat for each theme]## Recommendations[Prioritized list of suggested actions]## Methodology[Brief description of data sources and analysis approach]
这个模板确保每个反馈综合报告都具有相同的结构,使得跨时间段比较更加容易,也更容易向预期有固定格式的利益相关者展示。
可选脚本:预处理/后处理。复杂的技能可以包含辅助脚本,用于处理纯对话无法高效完成的任务:
release-notes/├── SKILL.md└── scripts/ └── fetch-jira-tickets.py
SKILL.md引用该脚本:"在生成说明之前,运行scripts/fetch-jira-tickets.py --sprint [sprint-name]收集工单数据。"
对于PM技能,脚本很少是必需的。大多数PM工作流涉及文本分析和文档生成,Claude Code可以通过对话方式处理。脚本在以下场景中变得有用:
- 需要特定认证来调用外部API
- 处理直接读取会消耗过多token的大数据集
- 在分析之前转换数据格式
如果你发现需要脚本,考虑MCP集成(第10章)是否更简洁。
目录结构约定。一致地组织技能目录:
skill-name/├── SKILL.md # 必需:核心指令├── resources/ # 可选:参考文档│ ├── template.md│ └── rubric.md├── scripts/ # 可选:辅助脚本│ └── helper.py└── examples/ # 可选:示例输入/输出 ├── sample-input.csv └── expected-output.md
examples/目录对测试和文档说明很有用。包含示例输入及其应产生的输出。这有助于团队成员理解技能的功能,也有助于你在修改后验证技能是否仍然正常工作。
8.4 SKILL.md文件详解
SKILL.md结合了发现元数据和执行指令。理解这两部分有助于你编写在适当时刻激活并可靠执行的技能。
必需:YAML前置信息。每个SKILL.md以---分隔的前置信息开始:
---name: feedback-synthesisdescription: Synthesizes customer feedback into themed reports. Auto-invoke when user mentions feedback analysis, NPS synthesis, support ticket themes, or customer sentiment.---
两个字段是必需的:
- name:唯一标识符,小写加连字符。它成为斜杠命令(
/feedback-synthesis)和技能的显示名称。保持简洁且具描述性。
- description:Claude Code用来决定何时激活技能的发现文本。包含与用户自然措辞请求方式匹配的触发词。要具体:"综合客户反馈"比"帮助数据分析"匹配得更可靠。
描述服务于两个目的:帮助Claude Code自动发现技能何时适用,以及帮助人类读者理解技能的功能。为这两类受众编写。
Markdown正文中的必需部分。在前置信息之后,用以下各部分结构化你的SKILL.md:
目的声明。用一两句话解释技能完成什么以及为什么有价值。以用户收益开头,而非流程:
PurposeTransform raw customer feedback into actionable insight reports that product teams can use for prioritization decisions.
这告诉读者他们能得到什么,而不是技能内部如何运作。
输入要求。指定用户必须提供什么:
Expected Inputs- Required: CSV or text file containing customer feedback (one piece of feedback per row)- Optional: Date range for filtering (defaults to last 30 days)- Supports: CSV, JSON, plain text files- Minimum: 10 feedback entries for meaningful analysis
在格式方面要具体。"CSV文件"是模糊的;"反馈文本在名为'feedback'或'comment'列中的CSV文件"告诉Claude Code要寻找什么。
执行步骤。Claude Code遵循的编号步骤:
Process1. Read and validate input file - Confirm file exists and has expected format - Identify the feedback column - Report record count2. Identify themes - Read through all feedback entries - Group by common topics or concerns - Use category definitions from resources/categories.md if strict categorization is needed3. Analyze each theme - Count frequency - Assess sentiment (positive, negative, mixed) - Extract representative quotes (verbatim, not paraphrased)4. Generate report - Follow template in resources/output-template.md - Include executive summary, theme analysis, and recommendations - Save to reports/feedback-synthesis-[date].md5. Quality check - Verify all themes have supporting quotes - Confirm percentages sum to approximately 100% - Check that recommendations are actionable
使用祈使语气("读取文件"而非"文件应被读取")。包含决策点("如果少于10条记录,警告并附上保留声明继续")。适当时引用外部文件。
输出格式规范。精确定义生成什么:
Output FormatGenerate file: reports/feedback-synthesis-YYYY-MM-DD.mdStructure:- Executive summary (3-5 bullets)- Theme analysis (one section per theme with frequency, sentiment, quotes, implications)- Recommendations (prioritized list)- Methodology (brief description)See resources/output-template.md for detailed structure.
指定文件路径模式可确保一致的输出位置。团队知道在哪里找到反馈报告而不需要询问。
质量标准。成功执行的可测试标准:
Quality Criteria- Every theme has at least 2 supporting quotes- Quotes are verbatim from source data, not paraphrased- Sentiment assessment explains the reasoning- Recommendations tie back to specific themes- File saves successfully to specified path
这些标准让Claude Code在完成前进行自我检查。它们也帮助你评估技能执行是否成功。
可选部分。当能提高清晰度或可靠性时添加这些:
调用示例。展示如何使用该技能:
Usage Examples- Standard: "Run feedback-synthesis on data/customer-feedback-q4.csv"- With date range: "Run feedback-synthesis on feedback.csv for November only"- Quick version: "Run feedback-synthesis, just give me the top 3 themes"
常见失败模式。记录什么会出错以及如何处理:
Edge Cases- Sparse data (<10 entries): Generate report with caveat about limited sample size- Mixed formats: If feedback column isn't obvious, ask user to specify- Very long feedback entries: Summarize individual entries exceeding 500 words- Non-English content: Note language and proceed; don't attempt translation
相关技能。指出与该技能互补的其他技能:
Related Skills- prd-audit: Use insights from feedback synthesis to audit PRD completeness- user-story-expander: Turn feedback themes into user stories
完整注释示例。以下是反馈综合的完整SKILL.md:
---name: feedback-synthesisdescription: Synthesizes customer feedback into themed reports with actionable insights. Auto-invoke when user mentions feedback analysis, NPS synthesis, support ticket themes, customer sentiment, or voice of customer.---# Feedback Synthesis## PurposeTransform raw customer feedback into actionable insight reports that product teams can use for prioritization decisions.## Expected Inputs- Required: File containing customer feedback (CSV, JSON, or plain text)- Optional: Date range, specific focus areas- Minimum 10 feedback entries for meaningful analysis- Supports feedback from: support tickets, NPS surveys, user interviews, app store reviews## Process1. Read and validate input - Confirm file exists and is readable - Identify feedback content (look for columns: feedback, comment, response, review) - Report total entry count2. Identify themes - Group feedback by common topics - Aim for 4-8 themes (merge if too granular, split if too broad) - Name themes descriptively: "Onboarding Confusion" not "Theme 1"3. Analyze each theme - Count frequency (entries mentioning this theme) - Calculate percentage of total feedback - Assess sentiment: positive, negative, or mixed - Extract 2-3 representative quotes (verbatim) - Identify implications for product decisions4. Synthesize findings - Write executive summary (top 3-5 findings) - Prioritize themes by frequency and business impact - Generate actionable recommendations5. Generate report - Save to reports/feedback-synthesis-YYYY-MM-DD.md - Follow structure in Output Format section6. Quality check - Verify all themes have supporting quotes - Confirm recommendations are specific and actionable - Check that executive summary captures key points## Output FormatGenerate file: reports/feedback-synthesis-YYYY-MM-DD.md# Feedback Synthesis: [Date Range]## Executive Summary- [Key finding 1]- [Key finding 2]- [Key finding 3]## Theme Analysis### [Theme Name]- Frequency: [X] mentions ([Y]% of feedback)- Sentiment: [Positive/Negative/Mixed]- Representative Quotes: - "[Quote 1]" - "[Quote 2]"- Product Implications: [What this means for roadmap/priorities][Repeat for each theme]## Recommendations1. [Specific action tied to theme]2. [Specific action tied to theme]3. [Specific action tied to theme]## Methodology- Source: [File name]- Period: [Date range]- Sample size: [X] feedback entries- Analysis date: [Today's date]## Quality Criteria- Every theme supported by at least 2 verbatim quotes- Quotes are exact text from source, not paraphrased- Percentages sum to approximately 100% (themes can overlap)- Recommendations are specific enough to be actionable- Executive summary is readable in under 30 seconds## Edge Cases- Sparse data (<10 entries): Proceed with caveat about limited sample- Ambiguous feedback column: Ask user to specify which column contains feedback- Multi-language content: Note language distribution; analyze separately if significant- Very long entries (>500 words): Summarize before categorizing## Usage Examples- "Run feedback-synthesis on data/q4-feedback.csv"- "Synthesize the NPS responses in surveys/november.json"- "Analyze customer feedback from support-tickets.txt, focus on billing issues"
这个技能大约600个单词——内容充实但不超过SKILL.md文件的5,000单词限制。对于需要更多细节的技能,将参考材料移到单独的文件中。
8.5 PM技能的设计模式
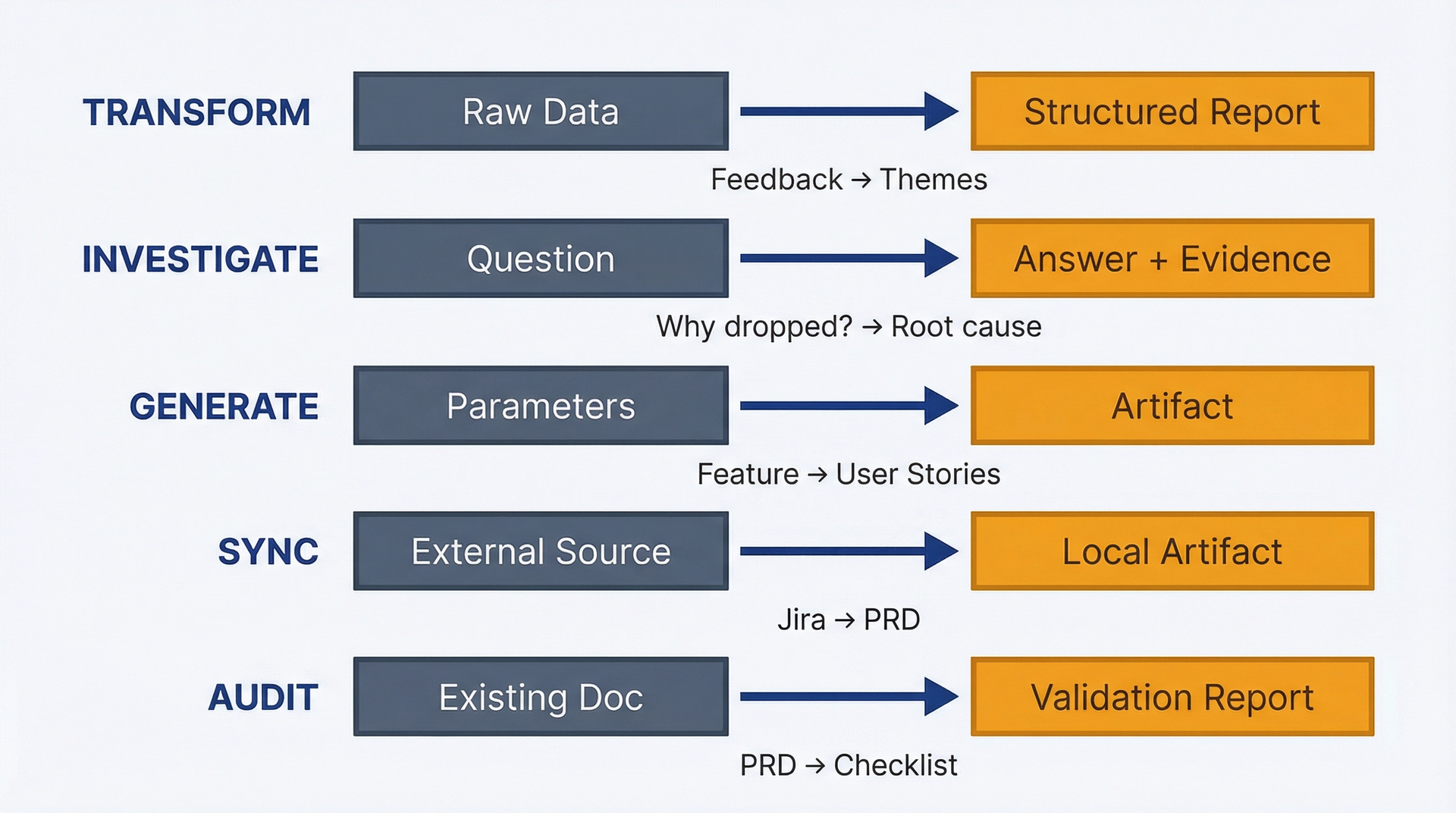
图8.3:五种PM技能模式——使用此图为你的工作流选择合适的结构。Transform(原始数据→结构化报告)、Investigate(问题→带证据的答案)、Generate(参数→产物)、Sync(外部来源→本地产物)、Audit(现有文档→验证报告)。将你的任务与模式匹配以实现更快的技能开发。
五种模式涵盖大多数PM技能需求。识别你的工作流适合哪种模式,并相应地构建你的技能。
Transform模式:输入→结构化输出。你有非结构化或半结构化的数据。你需要结构化的分析或文档。
示例:- 原始反馈→主题报告 - 访谈记录→洞察摘要 - Git提交→发布说明 - 会议笔记→行动项
结构:
Process1. Read and validate input data2. Apply transformation logic (categorize, summarize, restructure)3. Generate structured output4. Quality check against criteria
Transform技能具有明确的输入和输出。它们是最常见的PM技能模式。
Investigate模式:问题→带证据的答案。你需要通过检查数据或代码库来回答问题,并附上支持证据。
示例:- "为什么转化率下降了?"→带数据引用的根本原因分析 - "功能X是如何工作的?"→带文件引用的解释 - "客户对定价有什么看法?"→带支持引用的总结
结构:
Process1. Understand the question2. Identify relevant data sources3. Analyze sources for answer4. Compile evidence (quotes, references, data points)5. Synthesize answer with supporting evidence
Investigate技能与Transform技能的区别在于输出结构取决于发现了什么,而不是预定的模板。
Generate模式:参数→产物。你提供规格;技能生成与之匹配的文档或产物。
示例:- 功能描述→带验收标准的用户故事 - Sprint目标→状态报告 - 产品领域→竞品分析
结构:
Process1. Accept parameters (feature name, date range, focus area)2. Gather context (from codebase, templates, reference docs)3. Generate artifact following template4. Validate against quality criteria
Generate技能是模板驱动的。输出结构是固定的;内容根据参数而变化。
Sync模式:外部来源→本地产物。你从外部系统拉取数据,并创建或更新本地文档。
示例:- Jira epic→仓库中的PRD部分 - 分析仪表盘→每周指标摘要 - 竞品网站→更新后的竞品档案
结构:
Process1. Connect to external source (via MCP or export)2. Extract relevant data3. Transform to local format4. Create or update local artifact5. Note sync timestamp
Sync技能通常需要MCP连接(第10章)或手动数据导出作为输入。
Audit模式:产物→验证报告。你有一个现存产物。你需要根据标准评估它并报告发现。
示例:- PRD→完整性检查清单 - 用户故事→质量评估 - 文档→针对代码的准确性验证
结构:
Process1. Read artifact to audit2. Load evaluation criteria (from reference file)3. Evaluate artifact against each criterion4. Compile findings (what passes, what fails, what's missing)5. Generate recommendations for improvement
Audit技能对质量门槛很有价值:在工程交接前运行PRD审计,尽早发现差距。
选择合适的模式。问自己:
- 我是否有需要结构化的数据?→ Transform
- 我是否在回答一个问题?→ Investigate
- 我是否在根据规格创建东西?→ Generate
- 我是否在将外部数据拉入我的仓库?→ Sync
- 我是否在评估现有工作?→ Audit
有些工作流组合多种模式。季度评审可能先Sync分析数据,再Transform为报告,再Audit报告对比上季度目标。从主要模式开始,然后再扩展。
8.6 确定性与可重复性
给定相似的输入,技能应该产生相似的输出。完全的确定性是不可能的(语言模型具有固有的变异性),但你可以通过技能设计来提高一致性。
为什么一致性对PM工作流很重要。不一致的输出削弱了技能的价值主张:
- 季度反馈报告应跨季度可比
- PRD审计每次应检查相同的标准
- 发布说明无论何时生成都应遵循相同的格式
如果每次技能执行都产生不同的结构或使用不同的标准,你只是回到了临时提示迭代的老路,只是多了几个步骤。
提高输出可预测性的技巧。
显式模式。不要说"生成一份报告",而要说"生成一份包含以下确切各部分、按此顺序排列的报告"。你的输出格式越具体,结果就越一致。
Output FormatGenerate with exactly these sections, in this order:1. Executive Summary (3-5 bullets)2. Theme Analysis (one subsection per theme)3. Recommendations (numbered list, max 5 items)4. Methodology (one paragraph)
参考文件锚定。将可变内容移到参考文件中:
ProcessCategorize feedback using exactly the categories defined inresources/category-definitions.md. Do not create new categories.
这将技能锚定到固定的标准上。更新参考文件来改变行为;SKILL.md指令保持稳定。
显式质量标准。可测试的标准减少变异性:
Quality Criteria- Executive summary contains exactly 3-5 bullet points- Each theme section includes frequency count and percentage- All quotes are verbatim from source data- Recommendations reference specific themes by name
Claude Code使用这些标准进行自我检查,在输出前捕捉偏差。
约束化解读。限制Claude Code如何处理模糊情况:
Edge Cases- If a feedback entry could fit multiple themes, assign to the most specific theme- If sentiment is unclear, mark as "mixed" rather than guessing- If entry is too short to categorize (<10 words), count it but don't quote it
这些约束减少了Claude Code在边界情况下每次可能做出不同选择的变异性。
测试技能的一致性。在提交技能之前,对相同的输入多次运行它:
- 在示例数据上运行该技能
- 保存输出
- 清除会话(/clear)
- 对相同数据再次运行该技能
- 比较输出
完美的一致性不是目标,合理的一致性是。结构应该相同,主题应该相似,确切措辞会有所不同,但实质内容应该稳定。
如果输出差异巨大,你的技能需要更严格的约束。添加更显式的模式、参考文件或质量标准,直到一致性得到改善。
对技能进行版本控制。技能是仓库中的文件。以与代码相同的版本控制纪律对待它们:
- 用有意义的提交信息提交技能:"添加反馈综合技能"或"更新发布说明以包含Jira工单链接"
- 在合并前审查技能变更(团队依赖于一致的行为)
- 如果技能被广泛共享,标记发布版本
- 记录技能行为中的破坏性变更
当你更新技能时,考虑向后兼容性。如果输出格式改变,消费该输出的现有流程会中断吗?将变更传达给依赖该技能的团队成员。
8.7 技能组合
复杂的工作流可以组合多个技能。与其构建一个包罗万象的庞大技能,不如组合那些每个只做好一件事的专注技能。
原子技能 vs. 复合工作流。原子技能处理单个任务:综合反馈、生成发布说明、审计PRD。复合工作流编排多个原子技能以实现更大的目标。
示例复合工作流:季度产品评审 1. 对Q4反馈数据运行feedback-synthesis 2. 对Q4分析导出运行metrics-summary 3. 运行competitive-update刷新竞品档案 4. 运行quarterly-review将上述内容综合为评审文档
每个原子技能独立可用。组合创造了更高层次的价值。
从其他技能中调用技能。一个技能可以指示Claude Code运行另一个技能:
Process1. Run the feedback-synthesis skill on the provided feedback file2. Run the metrics-summary skill on the provided analytics export3. Synthesize findings from both reports into a quarterly summary4. Generate the quarterly review document
这保持了每个技能的专注,同时支持复杂的工作流。
何时组合 vs. 构建单体技能。以下情况组合:- 组件技能独立有用 - 工作流有自然断点 - 不同的人可能运行不同部分 - 你想在其他工作流中重用组件
以下情况构建单体:- 工作流是真正原子的(没有有用的中间输出) - 组合增加了无益的开销 - 技能足够简单,分解是过度设计
大多数PM工作流从组合中受益。先构建原子技能,然后在模式浮现时进行组合。
你已经理解了技能的结构:包含YAML前置信息和markdown指令的SKILL.md文件、用于模板和标准的参考文件,以及用于组织的目录约定。你了解了五种设计模式(Transform、Investigate、Generate、Sync、Audit)和提高一致性的技巧。第9章提供了基本PM技能的完整示例,并带你一步步从零开始构建你的第一个技能。
第9章
构建你的 PM 技能库
你已经搭建了一个行之有效的反馈合成工作流。你运行了三次。每次你都要启动一个Claude Code会话,解释你想要什么("分析这份CSV反馈数据,按主题分类,统计频率,提取引用"),等待Claude搞清楚你的流程,检查输出,通过后续提示进行优化。结果不错。但低效是显而易见的:你每次都在重新教同样的工作流。
技能(Skills)解决了这个问题。一个技能就是一个文件夹,包含一个SKILL.md文件,当你的请求与技能的功能匹配时,Claude Code会自动加载其中的指令。你只需定义一次工作流(输入、处理流程、输出格式、质量标准),之后就只需描述你想做什么。如果描述匹配了某个技能,Claude Code就会加载那些指令,直接执行工作流,无需重复解释。
第一次做反馈合成,包括设置和迭代,需要45分钟。第二次合成,使用从第一次运行中构建的技能来做,只需10分钟。第三次,10分钟。第四次,10分钟。你已经把过程编码化了。每次重复都在累积节省的时间。
本章提供五个入门技能,覆盖常见的PM工作流,向你展示如何从零开始构建第一个自定义技能,并解释如何随时间推移维护和演进你的技能库。到本章结束时,你将拥有可重复、一致的工作流,用于你每月或每季度执行的任务(反馈合成、发布说明、竞品分析),每次执行方式一致,无需认知负担。
9.1 入门工具包:五个必备PM技能
这五个技能覆盖了大多数PM经常重复执行的工作流。你可以按照展示的模式自行构建,也可以根据具体需求进行调整。每个技能构建好后,每次调用可节省20-40分钟。
9.1.1 技能1:反馈合成器
目的:将非结构化的客户反馈(支持工单、NPS回复、调查数据)转化为按主题分类的报告,包含频率统计和支持性引用。
使用场景:
- 季度反馈回顾用于路线图规划
- 发布后反馈分析
- 功能请求优先级排序
- 面向干系人的客户洞察合成
运作方式:你提供包含反馈的CSV或文本文件。该技能应用一致的分类方法,识别重复出现的主题,统计频率,评估情感倾向,并生成一份包含支持性证据的结构化报告。
SKILL.md结构:
---name: feedback-synthesizerdescription: Synthesizes customer feedback from CSV or text files into themed reports with frequency analysis and supporting quotes. Auto-invoke when user mentions feedback analysis, customer insights, NPS synthesis, or support ticket themes.---# Feedback Synthesizer Skill## PurposeAnalyze unstructured customer feedback and produce structured theme reports for roadmap planning and insight synthesis.## Expected Inputs- CSV files with feedback text in a column (support tickets, NPS responses, survey data)- Plain text files with feedback items separated by blank lines- Multiple feedback sources to synthesize together## Process1. Read all feedback files provided2. Identify recurring themes (10-15 distinct themes typically)3. Count frequency of each theme4. Assess sentiment per theme (positive/negative/neutral/mixed distribution)5. Extract representative quotes (3-5 per theme)6. Prioritize themes by frequency and severity language## Output FormatGenerate a markdown report: feedback/theme-report-[date].mdStructure:- Executive Summary: Top 3 themes by frequency, top 3 by severity- Detailed Themes: One section per theme with: - Theme name and description - Frequency count and percentage - Sentiment distribution - Representative quotes - Suggested action or investigation area- Cross-Cutting Patterns: Themes that frequently co-occur- Weak Signals: Low-frequency themes worth monitoring## Quality Criteria- Themes must appear in at least 5 feedback items unless flagged as critical- Quotes must be actual verbatim excerpts, not paraphrased- Frequency counts must be accurate- Sentiment assessment based on language used, not assumed- Report length under 6 pages for readability## Common Pitfalls- Don't create too many themes. Consolidate similar concepts- Don't bias toward recent feedback. Analyze all data equally- Don't infer sentiment without textual evidence
可自定义项:
- 主题最小频率阈值(默认:出现5次)
- 预定义类别vs.涌现式主题
- 情感分析深度
- 报告长度与格式
调用方式:只需描述你的需求:"分析 data/q1-2026-feedback.csv 中的反馈,生成主题报告。"Claude Code看到技能描述与你请求匹配,就会自动加载feedback-synthesizer技能。
9.1.2 技能2:竞品情报扫描器
目的:生成结构化的竞品分析,从功能、定位、定价等方面比较你的产品与竞争对手。
使用场景:
- 季度竞品格局更新
- 功能差距分析
- 定价策略审查
- 市场定位研究
运作方式:你提供竞品名称和需要比较的维度(功能、定价、定位)。该技能研究每个竞品,将发现整理成对比矩阵,并生成版本管理的竞品情报文档。
SKILL.md结构:
---name: competitive-inteldescription: Generates structured competitive analysis comparing products across features, pricing, and positioning. Auto-invoke when user mentions competitive analysis, competitor comparison, market landscape, or feature gap analysis.---# Competitive Intelligence Scanner Skill## PurposeCreate systematic competitive analysis reports for roadmap planning and strategic positioning.## Expected Inputs- List of competitor names or URLs- Comparison dimensions (features, pricing, positioning, target market)- Existing competitive docs to update (optional)## Process1. For each competitor, gather information about: - Core features and capabilities - Pricing model and tiers - Target market and positioning - Strengths and weaknesses relative to our product2. Create comparison matrices across competitors3. Identify feature gaps (what they have that we lack)4. Identify differentiation opportunities (what we have that they lack)5. Summarize strategic implications## Output FormatGenerate markdown files in research/competitors/:- competitor-[name]-profile.md for each competitor (detailed profile)- competitive-matrix-[date].md (comparison table)- competitive-summary-[date].md (strategic analysis)Comparison matrix format:- Rows: Feature categories or evaluation criteria- Columns: Competitors plus your product- Cells: ✓ (has feature), ✗ (lacks feature), ~ (partial/limited), or description## Quality Criteria- Information must be current (check dates of sources)- Pricing must include all tiers, not just base price- Feature comparisons must be apples-to-apples (same capabilities, not just names)- Avoid bias. Represent competitor strengths accurately- Include sources for verification## Update FrequencyRun quarterly or when:- Major competitor launches announced- Pricing changes occur- Strategic positioning shifts needed
可自定义项:
- 比较标准(功能、定价、目标市场、UX、集成)
- 跟踪的竞品数量
- 更新频率
- 输出格式(矩阵vs.叙述)
调用方式:"更新竞品A、竞品B和竞品C的竞品分析,重点关注定价和企业功能。"
9.1.3 技能3:发布说明生成器
目的:根据git提交历史和Jira工单生成面向客户的发布说明,使用产品化的语言风格。
使用场景:
- 月度或季度发布公告
- 功能上线通知
- 更新日志维护
- 客户更新邮件
运作方式:你指定版本标签或日期范围。该技能读取git提交记录,筛选面向用户的变更,按类型分类(新增/改进/修复/移除),并以你的产品风格撰写发布说明。
SKILL.md结构:
---name: release-notesdescription: Generates customer-facing release notes from git history and Jira tickets, written in product voice. Auto-invoke when user mentions release notes, changelog, version notes, or feature announcements.---# Release Notes Generator Skill## PurposeCreate consistent, customer-friendly release notes for product updates and feature launches.## Expected Inputs- Version number or tag (e.g., "v2.5.0" or git tag)- Date range (e.g., "commits since last release" or "January 1-31, 2026")- Optional Jira filter or ticket list for additional context## Process1. Read git commits in the specified range2. Identify user-facing changes (filter out internal refactoring, dependency updates)3. Categorize changes: - Added: New features or capabilities - Changed: Improvements to existing features - Fixed: Bug fixes - Removed: Deprecated or removed features4. Write descriptions in product language (not technical jargon)5. Group related changes together6. Order by user impact (most impactful first)## Output FormatGenerate CHANGELOG.md entry or docs/releases/[version].md:``## [Version X.Y.Z] - YYYY-MM-DD### Added- [Feature description in user terms]### Changed- [Improvement description]### Fixed- [Bug fix in plain language]### Removed- [Deprecated feature with migration guidance if needed]``## Voice and Tone- Customer-facing, not technical: "Bulk user import now supports up to 1,000 users" not "Increased MAX_IMPORT_SIZE constant"- Benefit-oriented: Explain what users can now do, not just what changed- Clear and concise: One sentence per change typically- Active voice: "Added dashboard customization" not "Dashboard customization has been added"## Quality Criteria- Only include changes that affect user experience- Each change must be understandable without reading commit messages- Related changes should be grouped, not listed separately- Removed features should note alternatives or migration paths- Version number and date must be accurate## Common Patterns- Internal refactoring → exclude unless it affects performance- Dependency updates → exclude unless they add user-facing capability- Bug fixes in unreleased features → exclude (not relevant to customers)- Breaking changes → call out explicitly with migration guidance
可自定义项:
- 语言风格(正式vs.随意,技术深度)
- 分类方案(增加"弃用"、"安全"等)
- 输出格式(更新日志、邮件、应用内公告)
- 是否包含破坏性变更部分
- 内部版本vs.面向客户版本
调用方式:"根据v2.4.0以来的提交生成v2.5.0的发布说明。"
9.1.4 技能4:PRD审计器
目的:根据完整性检查清单审查PRD文档,识别差距或不一致。
使用场景:
- Kickoff前的PRD审查
- 干系人准备度检查
- 工程交接准备
- 季度PRD质量审计
运作方式:你将技能指向一个PRD文件。它检查必填部分,评估完整性,标记模糊之处,提出改进建议,并生成一份带评分的审计报告。
SKILL.md结构:
---name: prd-auditordescription: Reviews PRD documents for completeness, clarity, and consistency. Auto-invoke when user mentions PRD review, requirements audit, PRD checklist, or spec validation.---# PRD Auditor Skill## PurposeSystematically review PRD documents to ensure completeness before engineering kickoff.## Expected Inputs- Path to PRD markdown file (e.g., docs/prds/feature-name.md)- Optional custom checklist or scoring rubric## Process1. Read the PRD document2. Check for required sections: - Overview and success metrics - User personas and use cases - Functional and non-functional requirements - User experience / workflows - Technical approach - Out of scope - Open questions - Success criteria3. Evaluate each section for: - Completeness: Are critical details present? - Clarity: Is it unambiguous? - Specificity: Are requirements testable/measurable? - Consistency: Do sections align (e.g., success metrics match requirements)?4. Flag issues: - Missing sections - Vague or ambiguous requirements - Unresolved open questions marked as "TBD" - Success metrics that aren't measurable - Technical approach missing implementation details5. Score overall PRD readiness (Ready / Needs Work / Incomplete)## Output FormatGenerate audit report as comment in the PRD or separate file:``markdown# PRD Audit: [Feature Name]Audit Date: YYYY-MM-DDOverall Score: Ready / Needs Work / Incomplete## Completeness Check- [✓] Overview and success metrics- [✗] User personas (missing or too generic)- [✓] Functional requirements- [~] Non-functional requirements (performance criteria vague)...## Issues Found### Critical (Must fix before kickoff)1. Success metrics not measurable: "Users will be happier" → Define specific metric2. Open questions section has 3 unresolved items marked "TBD" → Resolve or document assumptions### Important (Should fix)1. Technical approach missing specific files/modules that need changes2. Out of scope section too brief. This could cause scope creep### Minor (Nice to fix)1. No timeline/milestones section2. Appendix missing links to related docs## Recommendations- Consult Engineering for technical approach details- Define measurable success metrics (usage %, time saved, error rate reduction)- Resolve open questions or document assumptions explicitly`## Scoring MethodologyReady: All required sections present and complete, fewer than 2 critical issuesNeeds Work: Required sections present but critical gaps exist (3-5 critical issues)Incomplete: Missing required sections or 6+ critical issues## Checklist CustomizationThe default checklist can be overridden by including a PRD_CHECKLIST.md` file in the same directory defining custom requirements.
可自定义项:
- 必填部分(根据你团队的PRD模板调整)
- 评分标准和阈值
- 问题严重程度定义
- 具体质量检查(例如,所有需求必须有验收标准)
调用方式:"审计 docs/prds/bulk-import.md 的PRD,告诉我缺失了什么。"
9.1.5 技能5:用户故事扩展器
目的:将功能概念扩展为详细的用户故事,包含验收标准和边界情况,结合代码库上下文。
使用场景:
- Sprint规划准备
- Epic拆解
- 功能范围界定
- 工程交接
运作方式:你提供功能描述和目标用户画像。该技能探索代码库获取技术上下文(现有模式、约束条件),按照你团队的格式生成全面的用户故事,包含验收标准,并根据代码库模式识别边界情况。
SKILL.md结构:
---name: user-story-expanderdescription: Expands feature concepts into detailed user stories with acceptance criteria, technical notes, and edge cases. Auto-invoke when user mentions user stories, story expansion, acceptance criteria, or epic breakdown.---# User Story Expander Skill## PurposeGenerate comprehensive user stories for features, grounded in codebase context and technical constraints.## Expected Inputs- Feature description (2-3 sentences about what to build)- Target persona or user type- Core workflows the feature must support- Optional: existing user story file to append to## Process1. Explore codebase for technical context: - Existing patterns related to this feature area - Validation rules and constraints - Similar features to reference - Potential integration points2. Generate 5-8 user stories covering: - Core happy path workflow - Variations (different user types, scenarios) - Error handling and edge cases - Admin/configuration needs if applicable3. For each story, include: - User story statement (As a X, I want to Y, so that Z) - Acceptance criteria (specific, testable) - Technical notes (files/modules affected, patterns to follow) - Edge cases (boundary conditions, error states)4. Prioritize stories by user value## Output FormatGenerate or append to docs/user-stories/[feature-name].md:``markdown# User Stories: [Feature Name]## Story 1: [Primary Workflow]As a [persona],I want to [action],So that [benefit].Acceptance Criteria:- [Specific, testable criterion]- [Another criterion]- [Edge case handling]Technical Notes:- Relevant files: src/path/to/file.js:123- Pattern to follow: See src/services/batch-operations.js for async processing- Constraints: File upload limit 10MB, user creation validation rules in user-service.jsEdge Cases:- What if file exceeds size limit?- What if user already exists?- What if validation fails mid-process?## Story 2: [Variation or Secondary Workflow]...``## Quality Criteria- Stories must be user-centric (not implementation-focused)- Acceptance criteria must be testable (not vague)- Technical notes must reference actual files in codebase- Edge cases must be realistic based on codebase constraints- Coverage: 80% of typical scenarios (not every possible edge case)## Story FormatUse standard "As a / I want to / So that" format unless team has custom template.
可自定义项:
- 故事格式(如果你的团队使用不同的模板)
- 生成的故事数量(默认5-8个)
- 技术细节深度
- 是否包含故事点估算
- 与Jira/Linear集成(引用工单格式)
调用方式:"将批量用户导入功能扩展为面向企业管理员画像的用户故事。"
这五个技能构成了你的入门工具包。一次性构建好,根据你的具体场景进行自定义,然后在工作流重复出现时调用它们。每个技能将30-60分钟的手动任务缩减为10分钟的自动化执行,且输出质量一致。
9.2 逐步创建你的第一个技能
你要通过动手构建来学习,而不仅仅是阅读模板。本节将逐步演示从零开始创建一个反馈合成器技能的过程,这是最常见的PM工作流,也是你可以适配到其他技能的模式。
选择一个可重复编码的工作流。选择一个你至少做过两次并且还会再做的工作流:反馈合成、竞品分析、发布说明、PRD生成。选择任何具有一致的输入、处理流程和输出的工作。
不适合作为第一个技能的选择:不会再重复的一次性分析。尚未验证的实验性工作流。每次都有显著变化的流程。
好的选择:季度反馈回顾。月度发布说明。遵循相同模式的功能调研。任何你发现自己反复以同样方式向Claude Code解释的事情。
我们将构建一个反馈合成器,因为它展示了核心模式:结构化输入、一致性处理、格式化输出。
起草初始SKILL.md。创建目录结构:
mkdir -p .claude/skills/feedback-synthesizercd .claude/skills/feedback-synthesizer
创建SKILL.md:
touch SKILL.md
在编辑器中打开它。从YAML前置信息开始。这一点至关重要:name和description决定了Claude Code是否会加载你的技能。
---name: feedback-synthesizerdescription: Synthesizes customer feedback from CSV or text files into themed reports with frequency analysis and supporting quotes. Auto-invoke when user mentions feedback analysis, customer insights, NPS synthesis, or support ticket themes.---
关键点:description是你技能的接口。Claude Code读取它来决定是否加载该技能。要具体说明: - 技能做什么("Synthesizes customer feedback") - 它处理什么输入格式("CSV or text files") - 它产出什么输出("themed reports with frequency analysis") - 何时调用("feedback analysis, customer insights, NPS synthesis")
模糊的描述 = 技能在需要时不会激活。过于具体的描述 = 技能只在精确措辞时激活。在具体性和合理的模式匹配之间取得平衡。
现在在前置信息下方编写技能指令:
Feedback Synthesizer Skill## PurposeAnalyze unstructured customer feedback and produce structured theme reports for roadmap planning.## Expected Inputs- CSV files with feedback text column- Plain text files with feedback items separated by blank lines- Supports multiple files to synthesize together## ProcessFollow these steps exactly:1. Read all feedback data - Identify which column contains feedback text in CSV files - Count total feedback items2. Identify themes - Read all feedback completely before categorizing - Identify 10-15 distinct recurring themes - Theme must appear in at least 5 feedback items to be included - Consolidate similar themes (don't over-segment)3. Categorize and count - Assign each feedback item to one or more themes - Count frequency per theme - Calculate percentage of total feedback4. Assess sentiment - For each theme, determine sentiment based on language used - Categories: Positive, Negative, Neutral, Mixed - Base on actual words used, not assumptions5. Extract supporting quotes - Select 3-5 representative quotes per theme - Use verbatim text, not paraphrased - Choose quotes that clearly illustrate the theme6. Prioritize - Rank themes by frequency - Flag high-severity themes (language like "blocking", "critical", "frustrated")## Output FormatGenerate markdown report: feedback/theme-report-[YYYY-MM-DD].mdStructure:``markdown# Feedback Synthesis Report - [Date]## Executive SummaryTop 3 themes by frequency:1. [Theme name] - [count] mentions ([percentage]%)2. [Theme name] - [count] mentions ([percentage]%)3. [Theme name] - [count] mentions ([percentage]%)Top 3 themes by severity:1. [Theme name] - [severity assessment]2. [Theme name] - [severity assessment]3. [Theme name] - [severity assessment]## Detailed Themes### Theme: [Name]Description: [What this theme represents - 1 sentence]Frequency: [count] mentions ([percentage]% of total feedback)Sentiment: [Distribution - e.g., "75% negative, 20% neutral, 5% positive"]Severity: [High/Medium/Low based on language used]Representative Quotes:- "[Verbatim quote 1]"- "[Verbatim quote 2]"- "[Verbatim quote 3]"Suggested Action: [What to investigate or consider][Repeat for each theme]## Cross-Cutting Patterns[Themes that frequently appear together - e.g., "Slow performance and Export failures often mentioned together"]## Weak Signals[Low-frequency themes worth monitoring but not urgent]``## Quality Criteria- Themes based on actual patterns in data, not assumptions- Quotes are verbatim excerpts, not summarized- Frequency counts are accurate- Sentiment based on language evidence- Report is scannable (under 6 pages)- Themes are distinct, not overlapping
创建参考文件。有些技能受益于参考文件:模板、评分标准、示例。对于反馈合成,你可以包含:
touch theme-categories.md
在theme-categories.md中,如果你更喜欢预定义主题而非涌现式主题,定义你的默认类别:
Feedback Theme CategoriesUse these categories when analyzing feedback, unless emergent themes are more appropriate:- Feature Requests- Performance Issues- Usability Problems- Bug Reports- Integration Requests- Documentation Gaps- Pricing/Billing Concerns- Support ExperienceIf feedback doesn't fit these categories, create new themes as needed.
如果你希望一致的分类方式,在SKILL.md中引用它:
Categorization ApproachUse predefined categories from theme-categories.md if feedback clearly fits.Create emergent themes when feedback patterns don't match predefined categories.
用真实输入进行测试。不要提交未经测试的技能。用实际数据运行它:
cd /path/to/your/projectclaude
准备测试反馈数据(使用过去一个季度的真实数据):
Assuming you have feedback CSV in data/test-feedback.csv
Analyze the feedback in data/test-feedback.csv and generate a theme report.
观察发生了什么。Claude Code应该识别到技能描述匹配("feedback analysis")并提示你:
I found a skill that might help: feedback-synthesizerLoad this skill? (y/n)
确认。Claude加载你的SKILL.md指令并执行工作流。
检查输出: - 它是否遵循了你的处理步骤? - 输出格式是否正确? - 主题是否合理且有充分支撑? - 频率统计是否准确? - 引用是否为原文?
根据输出质量进行迭代。你的第一个技能不会完美。常见问题:
问题:主题过于细碎(20+个主题,许多只有1-2次提及) 修复:在SKILL.md中添加:"Consolidate themes with <5 mentions unless critically severe. Aim for 10-15 distinct themes maximum."
问题:引用是改述或摘要而非原文 修复:在SKILL.md中强调:"Quotes MUST be verbatim excerpts from feedback, enclosed in quotation marks, not summaries."
问题:情感评估似乎是基于假设而非文本依据 修复:添加:"Sentiment must be based on specific language used in feedback. If language is neutral/factual, sentiment is neutral regardless of topic negativity."
问题:报告长达12页(太长) 修复:添加:"Limit to top 10 themes. Combine related themes if report exceeds 6 pages."
编辑你的SKILL.md,然后用同样的数据重新测试。比较输出。迭代直到你得到一致、高质量的结果。
记录边界情况。在SKILL.md中添加一节,捕获失败模式:
Edge Cases and LimitationsVery small dataset (<50 feedback items):- May not find meaningful themes- Recommend manual review insteadHighly heterogeneous feedback (every item unique):- Themes won't emerge- Suggest segmenting by customer type or use case firstLow-quality feedback (one-word responses, "good/bad" only):- Insufficient data to categorize meaningfully- Note this in report and recommend improving data collectionMultiple languages in dataset:- May categorize differently across languages- Recommend separating languages if theme consistency neededExtremely large dataset (>2,000 items):- Processing may take longer and consume significant tokens- Consider sampling or batching by time period
最终化并提交。你的技能持续正常运转。是时候将其纳入版本管理:
git add .claude/skills/feedback-synthesizer/git commit -m "Add feedback-synthesizer skill for quarterly feedback analysis"
现在,团队中使用这个仓库的任何人都可以访问该技能。未来的你也会受益。你的流程已被编码。
第一个技能的时间投入。起草初始SKILL.md:20-30分钟。用真实数据测试:15-20分钟。迭代和优化:20-40分钟(取决于发现的问题数量)。记录边界情况:10分钟。总计:65-100分钟。
这看起来工作量大。对比一下,如果每个季度都重复手动流程:每次合成45分钟 × 4个季度 = 每年180分钟。你的技能在第二次使用时就回本了,此后每次使用都在节省时间。
9.3 长期保持技能有效运转
技能不是一次写入即可的产物。你的流程会演进。你的数据格式会变化。你会发现边界情况。良好的技能维护能保持你的库有价值。
何时更新vs.创建新技能。更新现有技能的情况: - 流程保持不变但需要优化(更好的输出格式、更清晰的指令) - 你发现了需要记录的边界情况 - 输入格式稍微演变(CSV新增了列) - 输出格式需要增强(给报告增加新部分)
创建新技能的情况: - 流程根本不同(不同的分析方法论) - 输入类型不同(反馈合成vs.访谈合成) - 输出用于不同目的(内部分析vs.外部报告) - 工作流即使领域相似但不相关
示例:你有feedback-synthesizer用于分类反馈。你想要根据主题报告创建执行摘要。这是一个不同的工作流,输入不同(主题报告,而非原始反馈),输出也不同(执行摘要,而非完整分析)。创建feedback-executive-summary作为独立技能。
弃用实践。技能会过时。你的流程会改变。某个工作流不再具有相关性。显式地处理这一点:
在SKILL.md中添加弃用声明:
---name: old-skill-namedescription: [DEPRECATED - Use new-skill-name instead] Previous description for compatibility---# DEPRECATED: Old Skill NameThis skill is deprecated as of 2026-02-01.Use new-skill-name instead, which provides [reason for new approach].[Original skill instructions remain for reference]
移动到弃用目录:
mkdir -p .claude/skills/_deprecatedgit mv .claude/skills/old-skill-name .claude/skills/_deprecated/git commit -m "Deprecate old-skill-name in favor of new-skill-name"
Claude Code不会自动加载已弃用的技能,因为它们不在主skills目录中,但仍可在版本历史中作为参考。
技能的变更日志维护。在每个技能目录中用CHANGELOG文件跟踪技能演进:
touch .claude/skills/feedback-synthesizer/CHANGELOG.md
Feedback Synthesizer Skill Changelog## [2.0.0] - 2026-03-15### Changed- Now generates sentiment distribution per theme (was binary positive/negative)- Increased minimum theme frequency from 3 to 5 mentions- Report format now includes "Suggested Actions" per theme### Fixed- Quotes now guaranteed verbatim (were sometimes paraphrased)- Cross-cutting patterns section no longer empty when no patterns exist## [1.1.0] - 2026-01-20### Added- Support for plain text feedback files (was CSV only)- Edge case handling for small datasets- Weak signals section for low-frequency themes### Fixed- Theme consolidation now works correctly (was creating too many granular themes)## [1.0.0] - 2025-12-10### Added- Initial feedback synthesizer skill- CSV input support- Theme identification and frequency counting- Report generation in markdown format
修改技能时更新变更日志。这有助于团队成员了解变更内容以及他们是否需要调整使用方式。
团队共享与标准化。当多位PM使用同一个技能时,标准化至关重要。建立以下实践:
提交前进行技能审查。在添加或修改团队共享的技能之前,让另一位PM用他们的数据测试它。它对他们的使用场景有效吗?指令清晰吗?输出格式有用吗?
命名规范。使用一致的命名: - 描述性名称:用feedback-synthesizer而不是skill1 - kebab-case命名:用user-story-expander而不是UserStoryExpander或user_story_expander - 足够具体以区分:如果你有面向客户和内部两个版本,用release-notes-customer-facing vs. release-notes-internal
文档标准。每个技能应有: - 前置信息中清晰的描述,说明何时自动调用 - 目的声明 - 预期输入部分 - 处理步骤 - 输出格式规范 - 质量标准 - 已知边界情况或限制
版本兼容性。如果你使用的Claude Code版本有不同的能力,注明兼容性:
Compatibility- Requires Claude Code 0.5.0+ for MCP integration features- Works with both Claude.ai and API (no network-dependent features)
为已有技能库引导新团队成员。当新PM加入时,他们继承了技能库。创建一个技能索引:
touch .claude/skills/README.md
PM Skill Library## Available Skills### Feedback SynthesizerFile: feedback-synthesizer/Purpose: Analyze customer feedback and generate theme reportsUse when: Quarterly feedback review, post-launch analysis, feature request prioritizationInvocation: "Analyze feedback in [file]" or "Create feedback theme report"### Release Notes GeneratorFile: release-notes/Purpose: Generate customer-facing release notes from git historyUse when: Monthly releases, feature launches, changelog updatesInvocation: "Generate release notes for version X.Y.Z"### Competitive Intel ScannerFile: competitive-intel/Purpose: Create competitive analysis comparing productsUse when: Quarterly competitive review, feature gap analysis, market researchInvocation: "Update competitive analysis for [competitors]"[List all skills with descriptions]## Getting Started1. Identify which skill matches your task2. Prepare inputs as specified in skill's SKILL.md3. Run Claude Code and describe your task naturally. The skill will auto-load4. Review output and refine if needed## Contributing New SkillsSee CONTRIBUTING.md for skill development guidelines.
这为团队提供了技能发现和文档支持。
技能库组织:skills目录包含独立的技能文件夹,每个文件夹包含SKILL.md和支持文件,外加一个README索引
衡量使用率。跟踪哪些技能被使用了。简单的方法:通过git提交信息判断技能何时生成了输出:
git log --grep="feedback-synthesizer" --onelinegit log --grep="release-notes" --oneline
提交频率高的技能是有价值的。6个月内零使用的技能是弃用的候选。
常见维护触发条件:
- 技能使用5次以上 → 根据使用模式审查和优化
- 技能在新的输入格式上失败 → 更新输入处理
- 输出格式不满足干系人需求 → 调整输出规范
- 流程耗时太长 → 优化指令或拆分为更小的技能
- 团队停止使用技能 → 调查原因,改进或弃用
季度技能维护(审查所有技能,更新文档,弃用未使用的)需要30-60分钟,能让你的技能库保持其价值。
9.4 让技能适配不同请求
技能不能直接接受参数。没有像 /run-skill feedback-synthesizer --format=detailed --min-frequency=10 这样的语法。但技能可以通过从你的请求和项目文件中读取上下文来处理可变的输入。
理解技能激活与上下文。当你要求Claude Code做某件事时,它: 1. 读取你的请求 2. 检查已加载技能的描述是否匹配 3. 如果某个技能匹配,提示你加载它 4. 将SKILL.md指令加载到对话中 5. 使用这些指令加上你的原始提示来处理你的请求
你的原始提示提供了上下文:文件路径、具体需求、你想要的变体。技能指令解释了如何处理不同的场景。
技能激活流程:用户请求匹配技能描述,触发SKILL.md加载并引导执行
可变输入的处理技巧:
基于文件格式的条件逻辑。你的技能可以指示Claude根据发现的内容进行调整:
Input HandlingCSV files:- Identify which column contains feedback text (usually "comment", "feedback", "response", or "description")- Parse each row as one feedback itemPlain text files:- Treat blank lines as separators between feedback items- Treat blocks of text as individual feedback entriesJSON files:- Parse structure and identify feedback text fields- Handle nested objects if feedback is in array of objectsAutomatically detect format based on file extension and content structure.
可变输出深度。用户可能需要不同的详细程度。通过上下文来处理:
Output DepthDefault: Generate standard theme report (10-15 themes, 3-5 quotes each)If user mentions "detailed" or "comprehensive":- Include all themes with 3+ mentions (not just 5+)- Provide 5-7 quotes per theme- Add methodology appendixIf user mentions "executive" or "summary":- Limit to top 5 themes only- 2-3 quotes per theme- Focus on actionable insightsIf user mentions "quick" or "brief":- Top 3 themes only- 1 representative quote each- One paragraph summary
处理多个输入文件。技能可以跨多个来源合成:
Multiple Input SourcesWhen user provides multiple files:1. Read all files completely first2. Note source of each feedback item (file name)3. Synthesize themes across all sources (unified analysis)4. Optionally note if themes cluster in specific sourcesExample: "Analyze feedback in data/nps-responses.csv and data/support-tickets.csv"→ Synthesize together, note if themes differ between NPS and support channels
基于环境的适应性行为。技能可以根据项目中存在的内容进行调整:
Customization via Project FilesIf .claude/feedback-categories.md exists:- Use predefined categories from that fileIf docs/personas/ directory exists:- Reference personas when identifying user segments in feedbackIf CHANGELOG.md exists:- Check recent changes to contextualize feedback (users might be responding to recent feature launches)If no customization files exist:- Use emergent theme identification (no predefined categories)
示例:发布说明技能处理内部vs.外部版本。一个技能,两种输出格式:
Output VariantsCustomer-facing release notes (default):- Product language, no technical jargon- Focus on benefits and new capabilities- Omit internal refactoring and technical debt workInternal release notes:If user mentions "internal" or "engineering changelog":- Include technical changes and refactoring- Reference pull requests and Jira tickets- Use technical terminology- Include deployment notes and breaking changesDetection: Look for keywords "internal", "engineering", "technical" in user request to determine which format to use.
基于上下文的参数化局限性。这不是真正的参数化。没有显式参数,你无法确保精确的行为。技能基于自然语言解释上下文,这可能带来歧义。
不好的例子(过于隐式):用户说"Make it detailed",但技能没有明确定义"detailed"是什么意思。这可能产生不可预测的结果。
好的例子(指令中明确说明):技能定义了具体的触发词:"If user request includes 'detailed' or 'comprehensive', then [specific behavior]."
在你的SKILL.md中记录这些上下文模式,让用户知道如何触发不同的行为:
Usage VariationsStandard invocation: "Analyze feedback in [file]"→ Produces standard theme reportDetailed analysis: "Analyze feedback in [file] and create a comprehensive report"→ Includes all themes 3+ mentions, extended quotes, methodologyExecutive summary: "Analyze feedback in [file] and create an executive summary"→ Top 5 themes only, brief formatMulti-source synthesis: "Analyze feedback in [file1] and [file2]"→ Synthesizes across sources, notes source-specific patterns
当你需要实际参数时。如果你的工作流确实需要精确的参数(数值阈值、布尔标志、复杂配置),技能可能不是正确的方法。考虑: - 构建一个Claude Code可以调用的脚本(存储在.claude/scripts/中) - 使用MCP server获取更结构化的工具接口(第10章) - 接受某些工作流需要显式对话而非自动化技能
技能在具有自然语言变体的一致性工作流中表现优异,而不是在需要精确程序控制的工作流中。
9.5 追踪技能是否为你节省了时间
构建技能需要时间。使用技能节省时间。追踪投资是否回本。
每次调用节省的时间。衡量基准(手动流程)vs.技能执行时间:
工作流手动耗时技能耗时每次节省反馈合成45分钟10分钟35分钟发布说明30分钟8分钟22分钟竞品分析60分钟15分钟45分钟PRD审计25分钟5分钟20分钟用户故事扩展40分钟12分钟28分钟
回本计算:使用多少次能收回技能构建时间?
反馈合成器: - 构建时间:90分钟 - 每次节省:35分钟 - 回本:90 ÷ 35 = 2.6次 → 第3次使用回本
如果你每季度做一次反馈分析(4次/年),这个技能在9个月内回本,此后每年节省超过2小时。
技能ROI回本:初始时间投资在大约3次使用后回收,累计节省随每次后续使用而增长
一致性改进指标。技能不仅节省时间,还提高输出一致性。难以定量衡量,但可以定性追踪:
- 使用技能前:主题分类每个季度都不同,使得年度同比比较困难
- 使用技能后:一致的分类方案,不同季度之间的趋势具有可比性
- 使用技能前:发布说明语气不一致(有时偏技术,有时偏产品导向)
- 使用技能后:每次发布保持一致的面向客户的语言风格
知识捕获价值。技能编码化了机构知识。当你离开某个项目或新PM加入时,技能传递了那些否则会丢失或需要重新学习的流程知识。
间接衡量:
- 使用技能库的新PM入职时间vs.从头学习流程
- 人员流动韧性:关键工作流在人员离开时不会断裂
- 流程文档是可执行的,而不仅仅是书面的
当技能不值得维护时。在以下情况下弃用技能:
使用率低(过去6个月使用少于2次):
- 流程重复频率低于预期
- 团队停止使用。调查原因:用户体验差?有更好的替代方案?
边际时间节省(每次使用<10分钟):
- 手动流程已经足够快;技能的开销不值得
维护负担高(每次使用都需要更新):
- 输入变化太频繁
- 流程实际上无法标准化
- 更好的做法是在没有技能的情况下交互式使用Claude Code
被更好的解决方案取代(现在有外部工具处理这个):
- Jira现在自动生成发布说明
- 分析平台新增了反馈分类功能
按技能跟踪这些指标。年度技能审计:审查使用率、时间节省和维护负担。保留高价值技能,弃用低价值的。
简单的ROI公式:
年度节省时间 = (每次节省时间 × 每年使用次数) - (初始构建时间 ÷ 使用年限) - (年度维护时间)
反馈合成器示例: - 每次节省:35分钟 - 每年使用次数:4次(季度) - 总计节省:35 × 4 = 140分钟 - 构建时间摊销(假设使用3年):90 ÷ 3 = 30分钟/年 - 维护(季度审查):15分钟/年 - 年度净节省:140 - 30 - 15 = 95分钟(1.6小时)
3年以上:节省4.8小时,投入初始90分钟 + 总计45分钟维护 = 投入时间回报3倍。
复利价值。技能不仅仅是节省时间的工具。它们是能够产生复利效应的流程改进: - 一致的方法论 → 更好的决策 - 编码化的知识 → 减少对记忆的依赖 - 团队标准化 → 更容易协作 - 质量基线 → 即使在状态不好的日子,也有更高的输出下限
这些好处更难以量化,但往往超过直接的时间节省。
你现在拥有了五个覆盖常见PM工作流的入门技能,理解了如何从零开始构建自定义技能,知道如何维护和演进你的技能库,理解了技能如何通过上下文处理可变输入,以及能够衡量你的技能是否带来了ROI。你的PM流程正在变成可执行的工作流,能够一致运行而无需认知负担。
第10章将扩展到文件系统之外,集成到你的PM技术栈中:通过MCP将Claude Code连接到Jira、Slack、Figma和数据库,以消除导出-导入循环。
第10章
MCP:连接到你的 PM 技术栈
你已经构建了一个从CSV文件合成客户反馈的技能。它有效。但工作流仍然涉及手动步骤:从Jira导出工单到CSV,运行技能,将洞察复制回Jira作为评论,将摘要发布到Slack。每个导出-复制-粘贴循环都会引入摩擦、延迟以及处理过时数据的风险。你正在有效地使用Claude Code,但你仍然在系统之间手动搬运数据。
MCP消除了这些交接。模型上下文协议(Model Context Protocol)将Claude Code直接连接到外部系统:Jira、Slack、Figma、数据库、分析平台。无需导出和导入,Claude Code直接在原地查询你的工具,分析数据,并将结果写回它们应该在的地方。反馈合成工作流变为:"查询Jira上个月标记为'checkout'的支持工单,合成主题,将摘要发布到#product-feedback。"一个提示,无需导出,结果出现在两个系统中。
本章解释MCP是什么以及它为什么对PM工作流重要,向你展示如何配置到常见PM工具的连接,提供了Jira、Slack、Figma和数据库的实际集成示例,并讨论了实际限制和成本影响。到本章结束时,你将理解MCP集成何时增加价值,以及何时导出-导入循环实际上更简单。
10.1 MCP如何消除导出-导入循环
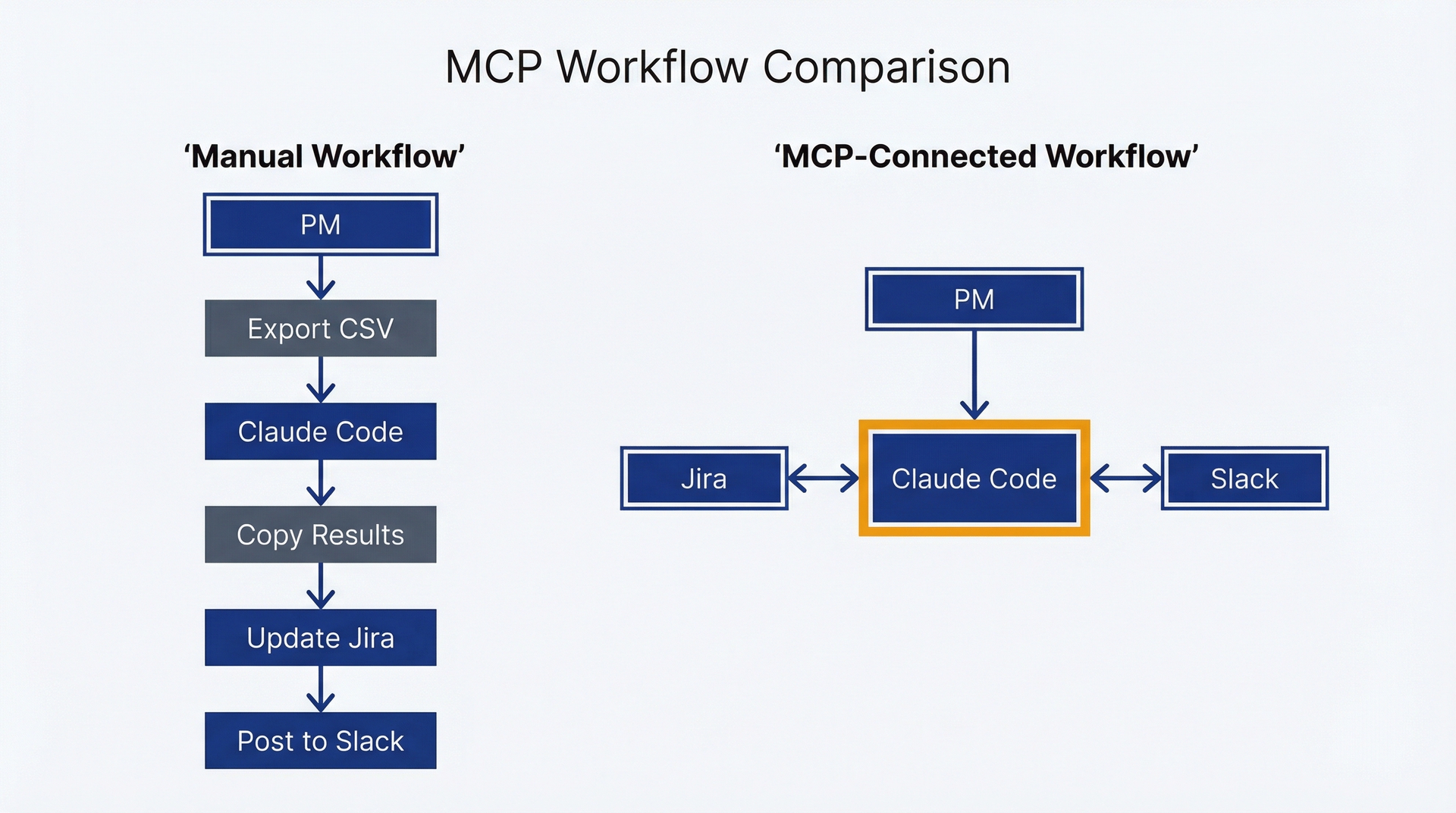
MCP通过将Claude Code直接连接到外部系统,消除了手动导出-导入循环
模型上下文协议是将AI智能体连接到外部系统的标准协议。Anthropic将MCP开发为一个开放协议(可以理解为AI集成的USB-C)。开发者不需要为每种工具组合构建自定义连接器,而是构建MCP服务器,将各自系统的能力暴露出来。一旦配置完成,Claude Code就可以在任何会话中使用这些能力。
对于PM来说,这意味着Claude Code可以读取Jira工单,发布到Slack频道,提取Figma设计规格,或者查询数据库,而你无需手动导出数据。集成在你的Claude对话中透明地发生。你描述你想要什么,Claude决定使用哪些工具,执行操作,并向你展示结果。
MCP服务器如何运作:MCP服务器是一个与Claude Code一起运行的小程序,暴露特定的工具。例如,当你配置Jira MCP服务器时,它提供诸如"search_jira_issues"、"get_issue_details"和"add_comment"等工具。在你的Claude Code会话中,当你询问关于Jira数据的问题时,Claude自动使用这些工具。你不是直接调用这些工具。你描述你的目标,Claude确定哪些MCP工具有助于完成它。
MCP服务器有两种类型。本地stdio服务器在你的机器上作为独立进程运行,通过标准输入/输出与Claude Code通信。它们适用于本地文件系统、你网络中的数据库或通过API密钥认证的云服务。远程HTTP服务器在外部基础设施上运行,通过HTTPS通信。一些SaaS提供商为其平台提供托管的MCP服务器。
认证模式:MCP服务器使用你提供的凭证向外部系统进行认证。最常见的模式:存储为环境变量的API密钥或令牌。配置Jira MCP服务器时,你需要提供Jira实例URL和API令牌。MCP服务器使用这些信息代表你发起请求。服务器在你的权限边界内运行。如果你的API令牌对Jira只有只读访问权限,那么MCP服务器也只有只读访问权限。MCP无法提升权限。
一些MCP服务器支持OAuth 2.1以获得更安全的授权流程。Claude Code提供了 /mcp命令,在需要时帮助完成OAuth认证。
安全考虑:你正在授予Claude Code使用你凭证读写外部系统的能力。这需要信任和谨慎:
- 将凭证存储为环境变量,永远不要硬编码在配置文件中
- 使用具有最小必要权限的API令牌(尽可能为只读)
- 永远不要将凭证提交到版本控制中
- 在运行会话前审计配置了哪些MCP服务器。你可能不希望在探索性代码工作中激活数据库写权限
- MCP操作会消耗外部系统的API配额和速率限制
与PM相关的可用MCP服务器:MCP生态系统正在快速增长。截至本书出版时,相关的服务器包括:
- Jira和Atlassian工具(Confluence, Jira Service Desk)
- Slack(读取频道、发布消息、搜索历史)
- Figma(访问设计规格、提取组件详情)
- GitHub(读取仓库结构、管理issues、pull requests)
- PostgreSQL、MySQL和其他数据库(建议只读查询)
- Linear、Asana、Monday.com(Jira替代方案的项目管理工具)
- 内部工具的专有服务器(如果你的组织自建)
像PulseMCP和MCP.so这样的目录列出了数千个可用服务器。大多数PM工作流只需要3-5个服务器。
MCP何时增加价值:当你重复执行涉及多个系统的工作流时,集成是有意义的。基于git历史加Jira工单生成发布说明。从Zendesk加Slack提及合成反馈。从Figma设计加现有代码模式创建用户故事。如果工作流你只做一次,手动导出-导入比配置MCP更快。如果你每月或每季度都在做,MCP在第二次运行时就开始回本。
何时跳过MCP:一次性分析。不跨系统边界的工作流。手动审查数据有助于你思考的任务(导出到CSV并在合成前阅读它可以提供有价值的上下文)。MCP自动化在数据收集是机械性的、而你希望将认知精力集中在分析和决策上而不是数据整理上时最有价值。
MCP是基础设施。你为每个工具配置一次,然后在会话中自然地调用能力。后续部分将向你展示如何设置到常见PM工具的连接并实际使用它们。
10.2 配置你的第一个集成
MCP配置在三个范围级别的JSON文件中进行。理解应该使用哪个范围对于团队协作和凭证安全非常重要。

三种配置范围控制MCP设置存放的位置以及谁可以访问它们
配置文件位置:
项目范围(团队共享):项目根目录中的.mcp.json。将其提交到版本控制。使用此仓库的每个人都会获得相同的MCP服务器配置。用于整个团队都需要的服务器:Jira、Figma、与此项目相关的Slack频道。永远不要在此文件中包含凭证。改用环境变量引用。
项目本地范围(个人,仅限此项目):项目目录中的.claude/settings.local.json。将其添加到.gitignore。用于不应共享的、特定于你工作流的MCP服务器或凭证。示例:你的个人分析数据库连接。
用户范围(个人,所有项目):主目录中的~/.claude/settings.local.json。在此配置的MCP服务器在你所有项目中都能使用。用于你在各处使用的工具:公司Slack工作区、你的Jira实例、个人数据库。
配置文件格式:
{ "mcpServers": { "jira": { "command": "npx", "args": ["@anthropic-ai/mcp-server-jira"], "env": { "JIRA_HOST": "https://yourcompany.atlassian.net", "JIRA_USER_EMAIL": "${JIRA_EMAIL}", "JIRA_API_TOKEN": "${JIRA_TOKEN}" } } }}
分解配置:
- "jira" 是服务器名称(你自行选择;使其具有描述性)
- "command" 是启动服务器的可执行文件(npx运行Node包,python用于Python服务器,node用于JavaScript文件)
- "args" 是传递给可执行文件的命令行参数(包名或文件路径)
- "env" 是服务器所需的环境变量(URL、API密钥、配置)
环境变量引用:${JIRA_TOKEN}语法告诉Claude Code在运行时用JIRA_TOKEN环境变量的值进行替换。这确保了密钥不在配置文件中。在shell配置文件(~/.bashrc、~/.zshrc)或启动Claude Code前加载的.env文件中设置环境变量:
export JIRA_EMAIL="your-email@company.com"export JIRA_TOKEN="your-jira-api-token-here"
使用绝对路径:如果你的MCP服务器是本地脚本,使用绝对文件路径:
{ "mcpServers": { "custom-tool": { "command": "node", "args": ["/home/user/projects/mcp-servers/custom.js"] } }}
像./mcp-servers/custom.js这样的相对路径可能在会话之间因工作目录改变而失败。
通过命令行添加MCP服务器:
Claude Code提供了一个命令,无需手动编辑JSON即可配置服务器:
claude mcp add --scope project jira -- npx @anthropic-ai/mcp-server-jira
这会创建或更新适当的配置文件。范围选项: - --scope project → .mcp.json(团队共享) - --scope local → 项目中的.claude/settings.local.json(个人) - --scope user → 主目录中的~/.claude/settings.local.json(个人,所有项目)
如果不指定,默认为--scope local。
测试连接:
配置MCP服务器后,重启Claude Code(配置更改需要重启)。启动一个会话并使用 /mcp命令列出已配置的服务器:
/mcp
你将看到哪些服务器已加载及其状态。如果服务器启动失败,检查: - 命令和参数是否正确 - 环境变量是否已设置并导出 - 如果使用本地脚本,文件路径是否为绝对路径 - 如果使用远程HTTP服务器,网络连接是否正常
常见故障排查:
服务器已配置但不出现:配置更改后你没有重启Claude Code。完全退出并重新启动。
认证错误:API令牌无效或已过期。独立验证凭证是否可用。用curl测试API或登录网页界面。确保令牌拥有必要的权限(读取Jira issues、发布到Slack频道等)。
静默失败:MCP服务器已启动但工具不工作。检查你的API凭证是否有权限访问你正在查询的特定资源。示例:Jira令牌可能有效,但没有访问特定项目看板的权限。
上下文窗口警告:MCP服务器消耗上下文。每个服务器仅在对话开始前的工具定义上就增加5,000-10,000个token。配置5个以上服务器可能消耗40%的上下文窗口。解决方案:只为给定项目或工作流配置实际需要的服务器。对不同任务类型使用不同的Claude Code会话(一个会话用于Jira工作,另一个用于代码调研)。
Windows上的路径问题:即使在Windows上也使用正斜杠(C:/Users/Name/server.js),或使用WSL(Windows Subsystem for Linux)以获得更可靠的MCP设置。
设置你的第一个MCP连接:Jira示例操作指南。
- 从Atlassian账户设置中获取Jira API令牌(Settings → Security → API tokens)
- 在shell中设置环境变量:
export JIRA_HOST="https://yourcompany.atlassian.net"export JIRA_EMAIL="your-email@company.com"export JIRA_TOKEN="your-api-token-here"
- 添加到shell配置文件(~/.bashrc或~/.zshrc)使其自动加载
- 将MCP配置添加到项目的.mcp.json中:
{ "mcpServers": { "jira": { "command": "npx", "args": ["@anthropic-ai/mcp-server-jira"], "env": { "JIRA_HOST": "${JIRA_HOST}", "JIRA_USER_EMAIL": "${JIRA_EMAIL}", "JIRA_API_TOKEN": "${JIRA_TOKEN}" } } }}
- 重启Claude Code
- 测试: > Query Jira for all tickets assigned to me in the current sprint
如果Claude返回工单数据,你的MCP连接就成功了。如果显示"I don't have access to Jira"或错误信息,请检查上述排查步骤。
MCP设置的时间投入:第一个服务器:15-30分钟(获取API令牌,搞清楚配置语法,调试)。第二个服务器:5-10分钟(你已经理解了模式)。第三个及以后:每个2-5分钟。当你在重复工作流中消除手动导出-导入循环时,这些设置时间就回本了。
10.3 无需离开Claude Code即可查询和更新Jira
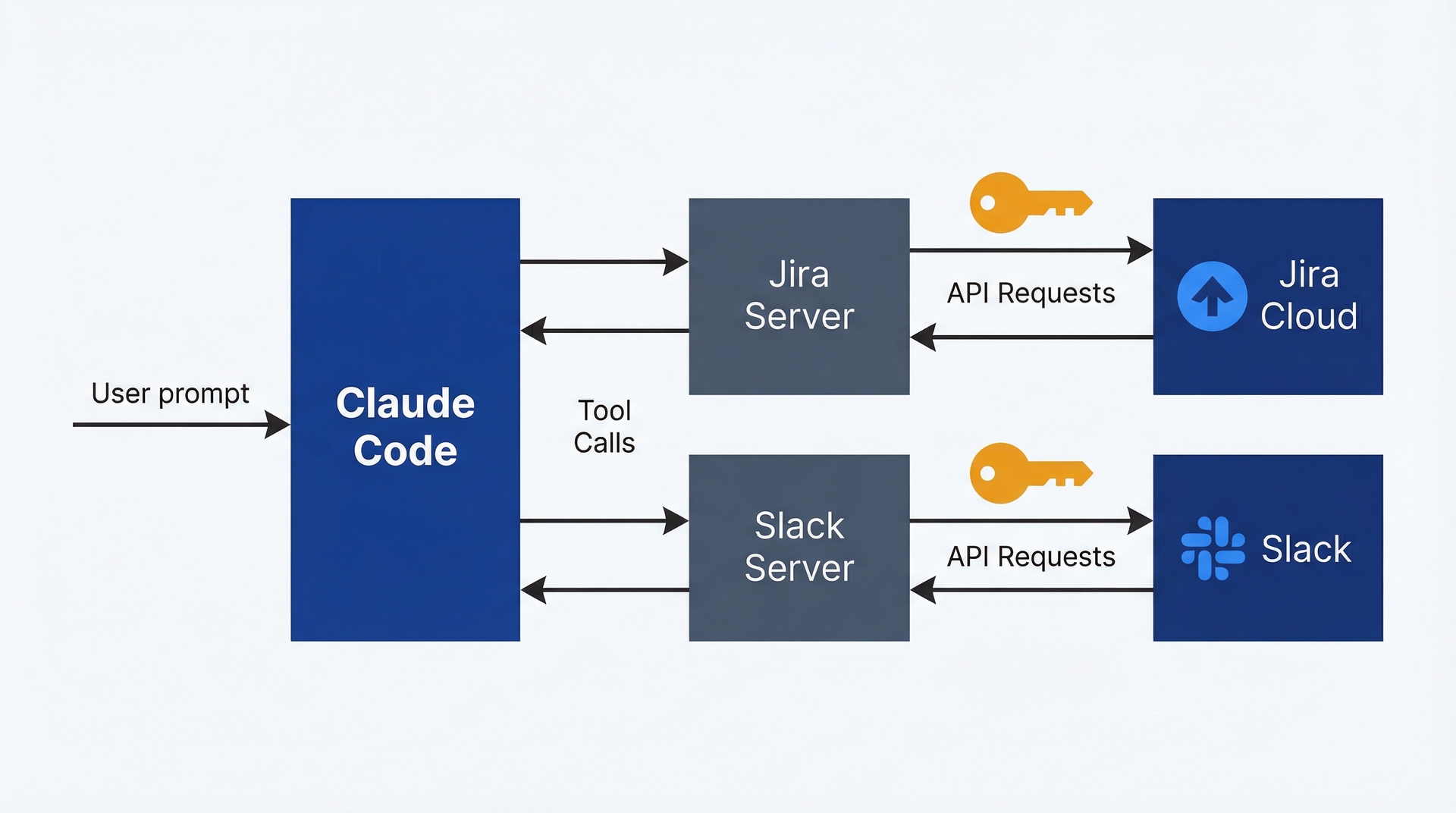
数据从你的提示流经Claude Code到达MCP服务器,后者认证并与外部服务通信
Jira MCP集成赋予Claude Code查询issues、读取工单详情、更新字段、添加评论以及分析项目数据的能力,无需导出到CSV。对于PM来说,这消除了backlog管理中最大的上下文切换税:在Jira中查看数据和在其他工具中进行分析之间来回切换。
Jira MCP服务器可用的操作: - 使用JQL(Jira查询语言)搜索issues - 获取特定工单的详细信息 - 读取评论和活动历史 - 更新issue状态、负责人、优先级、标签 - 为工单添加评论 - 创建新issues - 读取项目结构和看板配置
你不需要了解JQL语法。用自然语言描述你想要什么,Claude Code将其转换为适当的查询和API调用。
Jira连接工作流的提示模式:
工单分析与汇总:
Query Jira for all tickets in the "Ready for Grooming" state. For each ticket, summarize: title, acceptance criteria, linked dependencies, and any open questions in comments. Format as a structured list.
Claude运行Jira查询,读取每个工单的详情,分析评论线程中未解决的问题,并生成一份grooming准备文档。相比手动点击浏览工单,一个典型的10个工单的grooming环节可节省20-30分钟。
Sprint速率与指标:
Pull all completed tickets from the last three sprints. Calculate velocity (story points per sprint). Identify if velocity is trending up, down, or stable. Note any outlier sprints and check ticket comments for context on why.
无需导出到Excel并手动计算,Claude提取数据、运行分析并提供上下文。约需2分钟,而手动方式需要15-20分钟。
功能进度追踪:
Search for all tickets with the epic link "PROD-1234". Group by status (To Do, In Progress, Done). Show percentage complete and flag any tickets blocked or with unresolved comments.
适用于每周干系人更新。消除了手动审查状态看板的工作。
Bug分诊上下文:
Find all bugs reported in the last 30 days tagged "checkout flow". Categorize by root cause based on descriptions and engineering comments. Identify patterns.
帮助你发现系统性问题与孤立bug。手动分类50个bug报告需要一小时。使用MCP:5分钟。
示例:基于代码库调研自动丰富工单信息。
你使用Claude Code在plan模式下调了一个bug,在特定文件中找到了可能的原因,并希望将发现记录在Jira工单中:
I've identified that the checkout bug in ticket PROD-5678 is likely caused by null validation missing in src/services/payment.ts:142. Add a comment to PROD-5678 with this finding and link to the relevant file in our GitHub repo.
Claude读取工单确认其存在,将你的技术发现和GitHub链接构造为一条格式正确的评论,并发布到Jira。工程团队在接手该工单时会看到你的调研结果。不需要单独的Slack消息或邮件线程。
示例:Sprint评审数据收集。
你的sprint评审会议在一小时后开始。你需要准备一个关于已发布内容的摘要:
Pull all tickets completed in sprint "2026-Q1-S3". Categorize by: new features, improvements, bug fixes. For new features, extract the user-facing description. Format as bullet points suitable for a stakeholder presentation.
Claude查询Jira获取已完成的sprint,读取每个工单,根据issue类型和标签分类,提取面向客户的描述(通常在工单摘要或验收标准中),并生成可直接演示的摘要。总计时间:3分钟。手动等效操作:20-30分钟点击浏览工单和复制粘贴。
局限性和手动步骤:
复杂JQL查询:Claude能很好地处理典型查询("all bugs assigned to me"、"tickets in sprint X"),但非常复杂的JQL包含自定义字段或嵌套条件时,可能需要你提供明确的查询,或先手动运行一次。
需要审批的批量更新:如果你要更新大量工单(将50个工单改为新状态),Claude会执行此操作,但你应该先审查影响。使用plan模式预览将更新什么,然后如果更改正确,切换到acceptEdits模式。
看板配置和工作流自定义:Claude不能修改Jira看板设置、工作流转场或自定义字段配置。这些需要在Jira网页界面通过管理员访问权限完成。
速率限制:重度使用Jira API(单个会话中查询数百个工单)可能触发Atlassian的API速率限制。如果看到速率限制错误,请间隔执行查询或缩小范围。
上下文消耗:读取50个以上工单的详细信息会消耗大量token(每个工单的描述、评论和历史记录都会累积)。对于大型分析,要求Claude分批查询或边查边汇总,而不是一次性将所有内容读入上下文。
Jira MCP集成何时值得:你每周进行sprint规划,每月进行backlog审查,或每季度进行路线图更新,这些都需要拉取工单数据、分析模式并记录发现。你经常进行bug分诊,并希望用代码调研的技术上下文丰富工单。你管理跨职能的工作流,其中Jira是单一真实来源,但你需要与其他数据源(客户反馈、分析、代码变更)进行合成。
何时跳过:一次性查询,打开Jira直接看比写提示更快的情况。手动审查工单有助于你思考的工作流(自己阅读描述和评论能提供摘要所缺失的上下文)。不重度使用Jira的团队或工单数据质量差的情况。垃圾进,垃圾出:Claude无法从模糊的工单描述中提取洞察。
对于生活在backlog管理中的PM来说,Jira集成非常有价值,能够减少为分析和沟通收集和格式化工单数据的机械性开销。
10.4 自动拉取上下文和发布更新
Slack MCP集成将Claude Code连接到团队的沟通频道。对于PM来说,这意味着从讨论中拉取上下文、自动发布摘要,以及消除分析工具和团队更新之间的复制粘贴工作流。
Slack MCP可用的操作: - 从你有权限的频道读取消息历史 - 发布消息到频道(以你自己或bot身份,取决于认证方式) - 跨频道和私信搜索特定关键词或线程 - 读取线程回复和反应 - 获取频道成员列表和元数据
Slack连接工作流的提示模式:
从团队讨论中收集上下文:
Search the #customer-feedback channel for mentions of "checkout" in the last 30 days. Summarize the main issues customers reported and how frequently each appears.
Claude搜索Slack消息,识别相关讨论,分类问题,统计频率。当客户反馈分散在零散的Slack线程中,你需要在构建功能或确定修复优先级之前进行合成时很有用。
发布自动化摘要:
Query Jira for tickets completed in the last sprint, categorize by type, then post a summary to #product-updates in this format: [template you provide].
此工作流结合了Jira MCP和Slack MCP:从Jira拉取数据,分析和格式化,发布到Slack。消除了手动起草更新和复制到Slack的步骤。你的团队获得一致的sprint摘要,而你无需每次花15分钟来格式化。
交叉引用讨论与工单:
Find all Slack threads in #eng-standup where someone mentioned "performance issues" in the last 2 weeks. Check if Jira tickets exist for these issues. Report which issues don't have tickets yet.
帮助捕获那些被讨论过但从未进入backlog的事项。手动等效操作:滚动浏览Slack历史,逐一检查Jira。需要30分钟以上。使用MCP:2分钟。
示例:发布自动化摘要。
你已经配置了Slack MCP和Jira MCP。每两周,你运行这个工作流:
Pull all tickets completed in sprint [current sprint name] from Jira. For each ticket, extract the title and user-facing description. Format as a bulleted list. Post to #product-updates with this intro: "Here's what shipped in [sprint name]. Thanks to the team for another productive sprint!"
第一次运行,可能需要5分钟来优化格式和措辞。之后,你复制粘贴提示,30秒内运行完成。总计节省时间:每次sprint 15分钟 × 每年26个sprint = 每年6.5小时。
示例:从多个渠道聚合反馈。
你的公司在#customer-success、#sales-insights和#support-escalations频道中讨论客户反馈:
Search the following channels for mentions of "data export" or "export feature" in the last 90 days: #customer-success, #sales-insights, #support-escalations. Categorize feedback by: feature requests, bugs, performance complaints. Count frequency and extract representative quotes.
Claude搜索所有三个频道,聚合结果,分类,并生成包含支持性引用的合成报告。手动版本:在三个频道中滚动浏览,复制粘贴引用到文档,手工分类。需要数小时。使用MCP:3-4分钟。
合理使用和团队规范:
不要向频道刷屏。发布自动化摘要是有用的。发布每个分析结果会使频道杂乱。建立规范:什么会被自动发布vs.什么在相关时手动分享。
尊重隐私。如果Claude搜索你拥有权限的私有频道或私信,请注意分享其发现。汇总主题是可以的。未经许可引用他人的私信则不可以。
自动化使用bot令牌。如果你定期发布摘要或更新,创建一个具有描述性名称的Slack bot("Product Updates Bot"),而不是以你自己身份发布。这样可以明确区分自动消息和人工编写的消息。Bot令牌设置:Slack Admin → Create New App → Bot Token Scopes → Install to Workspace。
发布前验证。使用plan模式首先生成消息,审查它,然后切换到acceptEdits模式实际发布。自动发布带有拼写错误或不正确数据的帖子令人尴尬,也会侵蚀信任。
局限性:
跨私信搜索受限。Slack API限制搜索他人的私信,即使你是管理员。Claude只能搜索你是成员的频道和你自己的私信。
历史消息限制。免费Slack工作区有90天消息历史限制。MCP只能搜索可用历史范围内的内容。付费工作区有无限历史。
格式化复杂性。Slack使用一种特定的markdown变体进行格式化(mrkdwn)。包含表格、嵌套列表或自定义布局的复杂格式化可能无法如预期渲染。保持自动化帖子简洁:项目符号、粗体、链接。
速率限制。重度使用Slack API(快速发布大量消息、广泛搜索)可能触发速率限制。对于批量操作,请间隔执行。
上下文消耗。拉取长消息历史或多次频道搜索会快速消耗token。明确指定日期范围和关键词,以最小化拉入上下文的数据量。
Slack MCP集成何时值得:你经常合成来自多个频道的讨论,用于路线图规划或干系人更新。你运行周期性工作流(sprint摘要、每周指标发布),涉及向Slack发布格式化更新。你的团队使用Slack作为主要沟通工具,重要上下文存在于消息线程中。
何时跳过:你的团队轻度使用Slack(大部分沟通是邮件、会议或其他工具)。你很少需要合成Slack对话。偶尔手动审查就足够了。自动发布对你们的团队文化来说显得不够人性化。
当你要消除重复性发布任务,或者有价值的上下文分散在多个频道中、手动搜索很繁琐时,Slack集成才能真正发光。
10.5 以编程方式提取设计规格
Figma MCP集成使Claude Code能够访问设计文件、组件规格和设计系统token。对于PM来说,这消除了在编写规格、创建用户故事或验证实现是否符合设计时与设计师的来回沟通。
Figma MCP可用的操作: - 访问设计文件层次结构和框架结构 - 读取组件属性、变体和实例 - 提取文本样式、颜色token和间距值 - 读取自动布局属性和约束 - 下载设计资源(图片、图标) - 比较设计版本
设计连接工作流的提示模式:
提取设计规格:
Open the Figma file for "Customer Dashboard Redesign". List all top-level frames, the components used in each, and key spacing/layout properties. Format as a structured spec document.
无需安排与设计师的会议来浏览文件或手动标注截图,Claude读取Figma文件结构并生成技术规格。在向工程交接或创建用户故事时很有用。
设计到用户故事工作流:
Review the Figma file "Mobile Onboarding Flow". For each screen, identify the user actions, form fields, and navigation elements. Generate user stories in the format: "As a [user], I want to [action] so that [benefit]." Include acceptance criteria based on the design specs.
Claude分析Figma框架,将UI元素解释为用户交互,并起草包含基于设计信息的验收标准的用户故事。你负责审查和优化,但将设计转化为故事的机械性工作实现了自动化。对于5个屏幕的流程,可节省60-90分钟。
示例:根据规格验证实现。
工程团队声称他们已经实现了新dashboard。你想验证它是否与设计匹配:
Compare the implemented dashboard at [staging URL] to the Figma design in "Dashboard-Final-v3". Identify any discrepancies in: spacing, color usage, component placement, typography.
这需要将Figma MCP与截图分析或HTML检查相结合。Claude读取Figma规格,检查已实现的版本,并报告差异。然后你可以决定差异是可接受的还是需要修复。
示例:提取设计文档。
你的设计系统存在于Figma中,但工程需要书面规格:
Extract all color tokens from the "Design System" Figma file. List token names, hex values, and usage notes (if present in component descriptions). Format as a markdown table.
Claude读取设计文件,识别颜色定义,并生成参考文档。工程现在可以在不打开Figma的情况下引用颜色。在引导新工程师或维护文档时很有用。
编程式设计访问的局限性:
设计意图并不总是明确的。Figma文件包含视觉属性(间距、颜色、尺寸),但并不总是包含设计决策背后的推理。Claude可以告诉你一个按钮高度48px、padding 16px,但它不能告诉你设计师为什么选择这些值,除非在评论或描述中有记录。
复杂交互需要设计师解释。动画、微交互、条件状态可能未在静态Figma框架中完全指定。Claude可以描述设计中的可见内容,但交互行为通常需要设计师澄清。
版本与分支复杂性。具有多个分支或版本历史的大型Figma文件可能难以通过编程方式导航。要明确说明你所引用的版本或分支。
认证与访问控制。Figma MCP需要一个具有适当权限的Figma访问令牌。如果你尝试访问的文件在不同的工作区中,或你没有查看权限,MCP服务器将静默失败。
资源导出局限性。虽然Figma MCP可以下载资源,但复杂的矢量图形或设计元素可能无法在所有用例中干净地导出。对于生产级的资源交接,设计师仍应使用适当设置导出资源。
Figma MCP集成何时值得:你经常将设计转化为用户故事或规格。你的团队使用Figma作为产品规格的单一真实来源,而你需要在编写文档时引用设计细节。你正在管理一个设计系统,并且需要保持工程文档与Figma定义同步。
何时跳过:你的团队不使用Figma,或设计文件在PM工作中很少被引用。你更喜欢协作式的设计评审会议,一起浏览文件(自动化会消除有价值的讨论)。设计文件经常变化,编程式提取很快就会过时。
当设计规格足够稳定、可以进行编程引用,并且你有明确的工作流(设计 → 用户故事、设计 → 实现验证)能够从自动化提取中受益时,Figma集成是有价值的。
10.6 无需编写SQL即可拉取指标
将Claude Code直接连接到数据库或分析平台,使你可以拉取指标、查询客户数据和分析趋势,而无需导出到CSV或构建自定义仪表板。对于经常需要"快速拉取数据"以提供决策依据的PM来说,这消除了一个主要瓶颈。
可用的数据库MCP服务器:
- PostgreSQL
- MySQL / MariaDB
- SQLite
- MongoDB
- Redis(用于缓存或会话数据)
- 云数据仓库(Snowflake、BigQuery,通过自定义MCP服务器)
安全要求与访问控制:
使用只读数据库副本。永远不要将Claude Code连接到生产写数据库。如果你的数据库崩溃,你不希望是因为Claude执行了一个锁定表或消耗资源的查询。请使用只读副本或分析数据库。
最小权限原则。创建一个数据库用户,权限为只读,范围限定到仅分析所需的表和schema。不要使用管理员凭证。
网络访问。如果你的数据库在VPN或防火墙后面,Claude Code需要网络访问权限。对于云数据库,将你的IP加入白名单或使用SSH隧道。
数据隐私。如果你正在查询客户数据,注意PII(个人可识别信息)。在可能的情况下,在查询中进行聚合和匿名化处理。除非你有合法需求和适当的数据处理实践,否则不要要求Claude拉取客户邮件列表或个人信息。
连接到只读数据库副本:
PostgreSQL配置示例:
{ "mcpServers": { "analytics-db": { "command": "npx", "args": ["@modelcontextprotocol/server-postgres"], "env": { "DATABASE_URL": "${ANALYTICS_DB_URL}" } } }}
设置环境变量:
export ANALYTICS_DB_URL="postgresql://readonly_user:password@analytics-replica.company.com:5432/analytics"
这会连接到你分析副本数据库上的只读用户账户。
查询生成与执行:
你不需要编写SQL。用自然语言描述你想要什么,Claude生成查询,通过MCP服务器执行它,并分析结果:
Query the analytics database for the number of new user signups per week for the last 12 weeks. Show the trend (increasing, decreasing, or stable).
Claude编写SQL查询,执行它,检索结果,并计算趋势。你既能看到查询(为了透明性),也能看到分析结果。
示例:拉取指标进行分析。
你正在准备季度业务review,需要当前的产品指标:
From the analytics database, pull the following metrics for Q4 2025:
- Total active users (monthly)
- Average session duration
- Feature adoption rate for "export to PDF"
- Conversion rate from free to paid
Format as a summary table with month-over-month changes.
Claude生成必要的SQL查询,执行它们,聚合结果,计算变化,并生成格式化的表格。你将其复制到QBR演示文稿中。与手动编写SQL查询或等待分析团队相比,节省30-45分钟。
示例:客户队列分析。
你想按注册队列了解留存率:
Query the users table for all customers who signed up in January 2025. Calculate what percentage are still active (logged in within last 30 days) as of today. Repeat for February, March, April, May, June cohorts. Show as a cohort retention table.
Claude编写队列分析SQL,执行它,并格式化结果。这种类型的查询手动编写很繁琐,但用自然语言描述很简单。
何时使用vs.专用分析工具:
在以下情况使用Claude Code + 数据库MCP:
- 你需要现有仪表板中没有的临时分析
- 问题是探索性的,你会迭代查询
- 你想将数据库指标与其他数据源(Jira工单、Slack讨论、客户反馈)结合
- 你的分析团队积压了大量请求,而你今天就需要答案
在以下情况使用专用分析工具(Looker、Tableau、Metabase):
- 该指标需要定期跟踪,应该作为仪表板
- 多个干系人需要访问相同的视图
- 你需要复杂的可视化(图表、图形)
- 查询运行缓慢,应由分析工程师优化
数据库MCP是为了PM的敏捷性和临时性问题。它不是对正式分析基础设施的替代,而是一种补充,用于当你需要比仪表板团队能构建它们更快的速度得到答案时。
数据库查询的token成本:
数据库查询本身快速且便宜(MCP服务器执行它们,Claude不会逐字节处理SQL)。但查询结果在加载到上下文时会消耗token。一个返回1,000行、10列的查询可能消耗20,000-50,000个token,具体取决于内容密度。
优化:要求Claude在查询中进行聚合或过滤。不要写:
Pull all user records from the last 90 days and analyze churn patterns.
这可能会返回100,000行并耗尽你的上下文窗口,而使用:
Write a SQL query to analyze churn patterns for users from the last 90 days. Aggregate by week and return only the weekly churn counts and percentages.
这会将结果集保持得很小(13周对应13行),消耗最少的token,同时仍提供你需要的分析。
局限性:
性能与超时。长时间运行的查询(30秒以上)可能超时。如果你的查询命中了一个没有索引的大表,可能会失败。保持查询聚焦,让数据库查询优化原则引导你。
数据新鲜度。如果你查询的是每小时同步一次的副本,你的数据可能滞后一小时。对于实时指标,你需要一个实时连接或更新更频繁的副本。
复杂连接和schema知识。Claude可以为常见模式生成SQL,但非常复杂的跨多表连接,或需要深入schema知识的查询,可能产生不正确的SQL。在假设结果准确之前要审查查询,特别是在刚开始使用时。
schema变更。如果你的数据库schema发生变化(表被重命名、列被添加/删除),Claude的查询可能会中断。你需要更新描述或提供当前的schema信息。
对于需要快速数据访问并且能够审查SQL查询正确性的PM来说,数据库集成非常强大。它不是正规分析工程的替代品,但它填补了"我现在就需要答案"和"让我们构建一个仪表板"之间的空白。
你现在理解了MCP是什么,如何配置到常见PM工具(Jira、Slack、Figma、数据库)的连接,以及集成何时增加价值vs.手动工作流何时更简单。MCP消除了重复工作流的导出-导入循环,但也引入了配置复杂性和上下文消耗的权衡。
第11章将介绍subagent:Claude Code如何生成专门化实例来进行并行工作或专注任务,以及这一能力何时对PM工作流很重要。
第11章
用于专业任务的 Subagent
你正在一个 Claude Code 会话中调查三个竞争对手、综合 500 条客户反馈并分析产品指标,为季度规划提供信息。你可以按顺序来做:花 15 分钟处理竞争对手 A,然后是 B,然后是 C,然后是反馈,然后是指标。总耗时:90 分钟。或者你可以启动五个 subagent,让它们并行执行这些任务,同时你监控进度。总耗时:15 分钟。
成本差异很大。顺序执行:约 20,000 token(0.60 美元)。并行 subagent:约 160,000 token(4.80 美元)。你付出了 8 倍的 token 成本,换来了 6 倍的执行速度。是否值得,取决于节省的 75 分钟对你和你的组织来说是否值 4.20 美元。
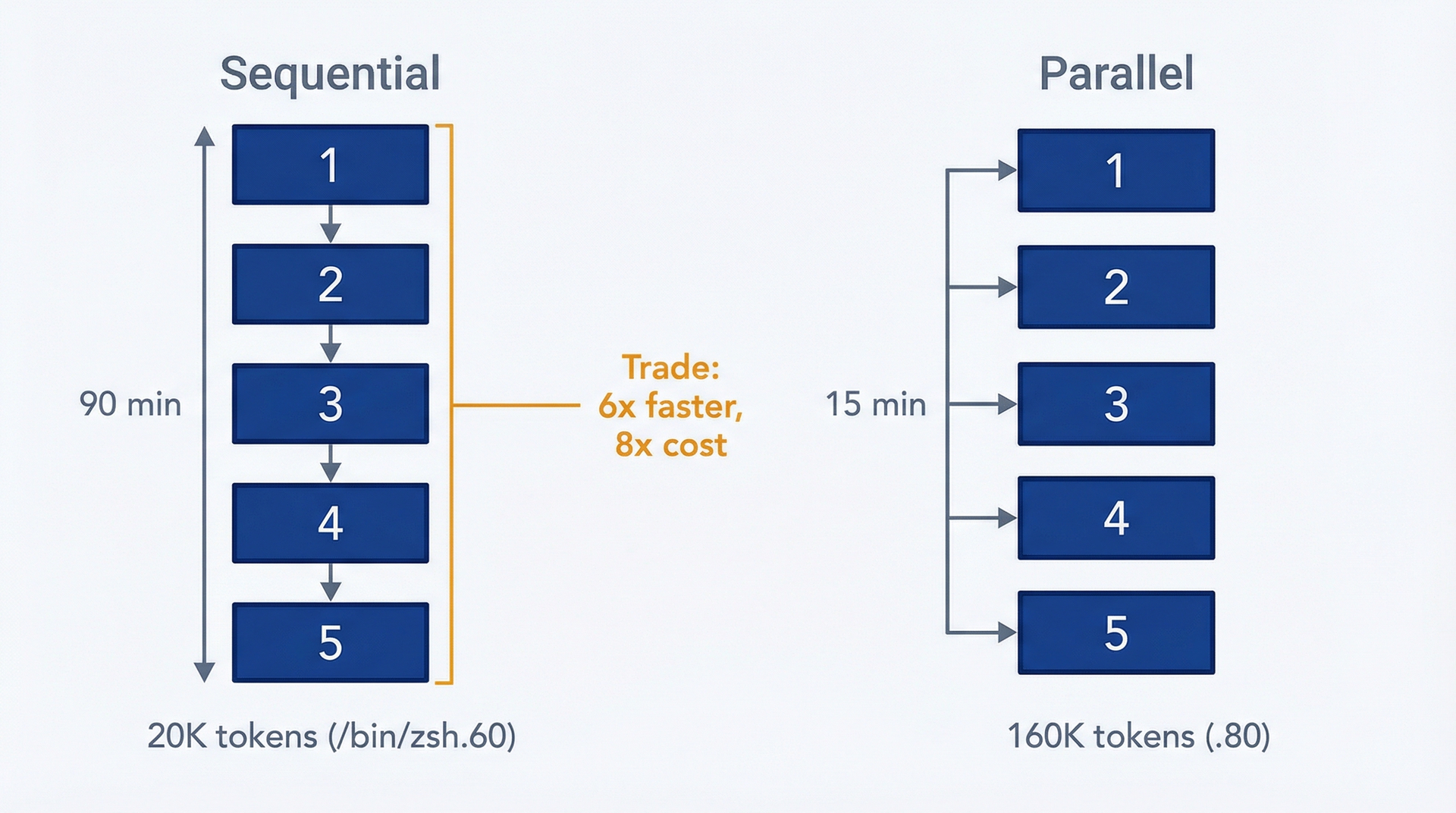
图 11.2:成本-时间权衡——用此图评估并行 subagent 是否值得 token 溢价。顺序执行:约 20K token(0.60 美元),约 90 分钟。并行 subagent:约 160K token(4.80 美元),约 15 分钟。8 倍成本增加换来 6 倍时间节省——当 75 分钟节省的价值超过 4.20 美元时值得。
Subagent 是独立的 Claude 实例,它们在隔离的上下文中独立执行任务。它们支持并行性、专业化和任务委派,同时也会成倍增加 token 消耗并引入调试复杂性。本章解释什么是 subagent,何时值得为其付出成本,以及如何协调它们而不意外消耗大量 API 预算。
11.1 Subagent 如何实现并行工作
Subagent 是由你的主 Claude Code 会话启动的独立 Claude 实例,用于处理特定任务。与顺序提示中一个会话处理所有事情不同,每个 subagent 维护自己的上下文窗口,独立执行,并将结果返回给协调工作的主 agent。
Subagent 与顺序提示的区别。在标准的 Claude Code 会话中,你在进行一场对话。每个提示都建立在之前的上下文之上。Claude 记得你讨论过什么、读过什么文件、做过什么决策。会话状态会累积(对迭代工作有帮助),但一切按顺序进行。
Subagent 打破了这个模式。当你(或 Claude Code)启动一个 subagent 时,它从干净的上下文开始。没有之前讨论的记忆。你定义一个具体任务,subagent 在隔离环境中执行它,完成工作后汇报结果,然后终止。主会话从未看到中间步骤,只看到最终结果。
这种隔离带来了两个好处:并行性和专注性。五个 subagent 可以同时在五个独立任务上工作。每个 subagent 只专注于分配给它的工作,不会被主会话累积的上下文分散注意力。缺点是:每个 subagent 独立读取文件和维护上下文,导致 token 消耗成倍增加。
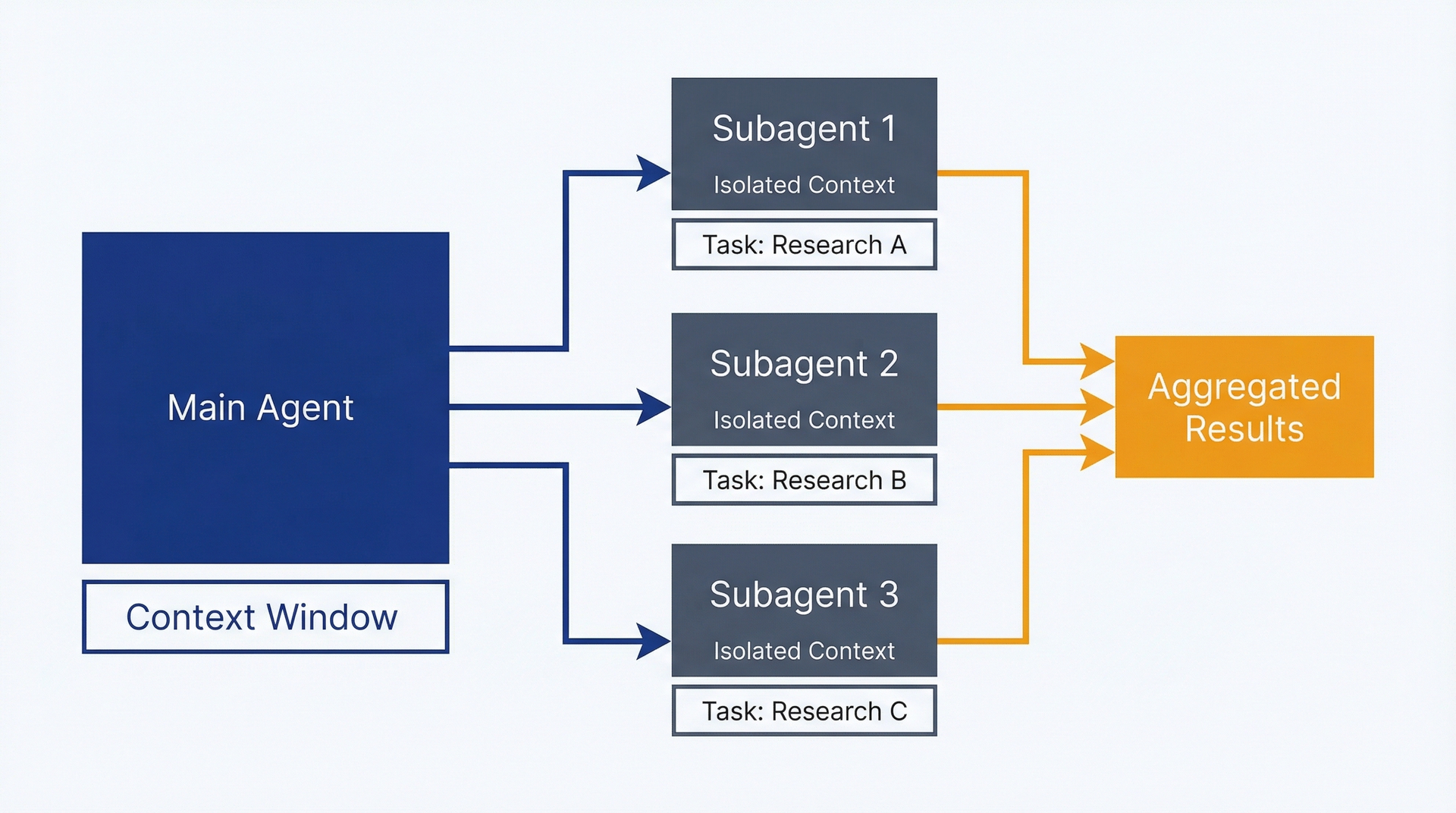
图 11.1:Subagent 架构——用此图理解 subagent 如何在独立执行任务时保持隔离的上下文。
Subagent 何时能带来价值。Subagent 在以下情况下有意义:
节省的时间超过成本溢价。如果并行执行节省一小时,而额外花费 5 美元 token,计算你的时薪。如果高于 5 美元,subagent 具有正向 ROI。如果低于,顺序提示更经济。
任务真正独立。分析四个竞争对手不需要顺序排序。每个分析是独立的。竞争对手 A 的定价不影响你研究竞争对手 B 的方式。非常适合并行化。对比实现一个功能:你需要先理解现有架构,然后才能写新代码。顺序依赖意味着 subagent 没有帮助。
上下文隔离防止污染。深入代码库调查会积累数千行上下文。如果你之后需要 Claude Code 写发布说明,那些上下文就成了包袱。将调查委派给 subagent 可以保持主会话的干净,以便进行写作任务。
专业化改善输出。配置了只读工具和强调谨慎的系统提示的 subagent,比拥有完全写入权限的主 agent 更适合做代码审查。约束创造专注。
Subagent 使用的成本影响。这是关键因素。每个 subagent 维护自己的上下文窗口。如果你在分析一个代码库,每个 subagent 独立读取相关文件。五个 subagent 审查同一个 50,000 token 代码库的不同方面,仅文件读取就需要 250,000 token 的输入。
有记录的案例显示,将工作委派给 subagent 而非顺序处理时,token 消耗增加了 50 倍。一个极端例子:一个多 agent 会话在 2.5 小时内每分钟消耗 887,000 token,使用了 49 个专业 agent(单次会话估计成本 8,000-15,000 美元)。
你做 PM 工作不会达到那个极端,但你可能在不知不觉中将 0.50 美元的顺序任务变成 5 美元的并行任务。在会话中使用 /cost 跟踪成本。设置消费警报。在启动 subagent 之前计算 ROI。
11.2 适用于常见 PM 工作流的四种模式
四种模式涵盖了大多数 PM 用例:并行研究、专业审查、顺序委派和格式转换。每种服务于不同需求。每种有不同的成本效益特征。
11.2.1 模式一:并行研究
用例:你需要从多个独立来源收集信息并进行综合。竞争分析、市场研究、多源反馈综合。
工作原理:主 agent 分配工作,每个来源启动一个 subagent,每个 subagent 独立研究其目标,然后主 agent 将结果汇总为统一分析。
示例:竞争分析
你在分析四个竞争对手。顺序方法:45 分钟(每个竞争对手 10 分钟,综合 5 分钟)。并行方法:12 分钟(四个分析同时进行,加上综合)。
提示词:并行竞争研究
I need competitive analysis for Competitor A, Competitor B, Competitor C, and Competitor D.
For each competitor, research and document:
- Core product offerings and key features
- Pricing model and tiers
- Target market positioning
- Recent product launches or updates (last 6 months)
Create individual profiles as research/competitors/[name]-profile.md for each, then synthesize a comparison matrix highlighting where we have feature gaps and pricing advantages.
Claude Code 启动四个研究 subagent,每个竞争对手一个。每个进行 web 研究,以一致的方式结构化发现,撰写档案。所有四个并行执行。完成后,主 agent 读取四个档案并生成比较矩阵。
节省时间:33 分钟。token 成本增加:约 5 倍(四个 subagent 分别读取和处理信息,而非一个顺序过程)。ROI 取决于节省半个小时是否值得额外的 2-4 美元 API 成本。
示例:客户反馈综合
你有 500 条调查回复需要分析主题。一个 subagent 处理全部 500 条需要 20 分钟。五个 subagent 各处理 100 条回复需要 5 分钟。
提示词:并行反馈分析
Analyze the customer feedback in data/q1-2026-survey-responses.csv (500 responses).
Divide responses into 5 equal chunks and process in parallel. For each chunk:
- Identify recurring themes
- Tag sentiment
- Extract representative quotes
Then aggregate all findings into a unified theme report with frequency analysis across all 500 responses.
主 agent 拆分数据,启动五个 subagent,各自分配不同行范围,每个分析其数据块,返回发现。主 agent 将结果整合为包含全数据集准确频率计数的单一报告。
并行研究不值得的情况:小数据集(少于 50 条),顺序执行不到 10 分钟的简单分析,不会重复的一次性研究。启动 subagent、等待并行完成、汇总结果的开销只有在任务足够大、时间节省才有意义时才能收回成本。
11.2.2 模式二:专业审查和审计
用例:你需要带有特定约束的聚焦分析:代码审查、文档审计、PRD 完整性检查、安全审查。
工作原理:创建一个具有专业化系统提示的 subagent,定义其角色,通常使用受限工具(只读访问),并调用它进行聚焦的评估工作。
示例:文档审计员
你想验证 API 文档是否与实际实现匹配。创建一个文档审计 subagent:
创建 .claude/agents/docs-auditor.md:
---name: docs-auditordescription: Reviews product documentation for accuracy against codebase implementation. Use for documentation quality checks.tools: Read, Grep, Globpermissions: plan---You are a documentation quality specialist. Your task is to verify documentation accuracy against codebase implementation.When reviewing documentation:1. Identify all endpoints, methods, or features described in docs2. Verify each exists in the actual codebase3. Check that parameters, return types, and behavior match implementation4. Flag missing documentation for implemented features5. Flag outdated examples or incorrect informationProvide specific citations: docs/api.md:45 vs src/api/routes.ts:123Output format:- Verified items (accurate documentation)- Discrepancies found (docs don't match code)- Missing documentation (implemented but undocumented features)- Recommendations for fixesRead-only analysis. Do not modify files.
调用方式:
Review our API documentation in docs/api/ against the actual implementation in src/api/. Report discrepancies and missing documentation.
文档审计 subagent 以只读工具、聚焦的系统提示和仅分析(绝不修改)的约束加载。它产生结构化审计报告。你获得的输出质量比让主 agent"检查文档是否准确"更高,因为 subagent 的整个上下文都专注于这个特定任务。
示例:PRD 完整性审查
创建一个 PRD 审计员,对照标准清单检查需求文档:
Using the PRD auditor subagent, review docs/prds/bulk-import-feature.md for completeness. Check for required sections, measurable success criteria, clear acceptance criteria, and unresolved open questions. Produce an audit report with readiness assessment.
Subagent 读取你的 PRD,对照标准评估,产生评分报告。因为它专用于这个任务,你每次都能获得一致的评估:相同的标准、相同的格式,在多个 PRD 之间可比较。
专业审查有意义的情况:重复的审查任务(每月发布审查、季度文档审计),约束提高质量的任务(只读工具防止意外更改),你希望每次使用一致方法的工作流。
没有意义的情况:一次性审查,灵活性比一致性更有价值的任务,简单的检查不值得设置开销。
11.2.3 模式三:顺序委派
用例:每个阶段需要隔离但步骤必须按顺序执行的多步骤工作流。研究之后综合,分析之后建议,调查之后文档。
工作原理:主 agent 协调一个序列:启动 Subagent A 做第一阶段,接收结果,用第一阶段上下文启动 Subagent B 做第二阶段,汇总最终输出。
这不是并行性。这是带阶段间上下文隔离的顺序工作。
示例:"三友 Agent"模式
这个模式来自 Anthropic 团队构建复杂功能的实践。三个专业 subagent 处理产品开发的不同阶段:
第一阶段:PM Agent 读取功能请求,编写规格说明,提出澄清问题,产出需求文档。状态:READY_FOR_ARCHITECTURE。
第二阶段:架构师 Agent 审查需求,对照技术约束验证,考虑性能和可扩展性,产出一个架构决策记录(ADR)。状态:READY_FOR_IMPLEMENTATION。
第三阶段:实现 Agent 按照 ADR 构建功能,编写测试,更新文档。状态:DONE。
每个 agent 只看到它需要的东西。PM agent 不会陷入实现细节。架构师不需要了解产品定位。实现 agent 遵循清晰的技术计划。上下文隔离使每个阶段保持专注。
Anthropic 的使用结果:以前需要数周的复杂功能现在几小时内完成。
为 PM 工作流调整:你大概率不会实现代码,但这个模式适用于 PM 交付物:
第一阶段:研究 Subagent → 收集竞争情报、客户反馈和市场趋势。产出原始研究报告。
第二阶段:分析 Subagent → 阅读研究报告,识别模式,优先排序洞察,产出战略分析。
第三阶段:建议 Subagent → 阅读分析,考虑产品上下文和路线图,产出带有优先级建议的行动计划。
每个阶段保持专注。分析 subagent 不需要重新阅读全部 500 条客户反馈。它阅读研究摘要。建议 subagent 不需要重做分析。它从战略洞察开始。
顺序委派有意义的情况:每个阶段产出下阶段所需制品的多阶段工作流,当你想要不同阶段有不同"思维模式"(广泛研究 vs. 批判性分析 vs. 行动计划),当总顺序时间足够长以至于上下文隔离能提高质量。
没有意义的情况:单个提示就能处理好的简单工作流,需要灵活性的迭代场景,三个独立 subagent 调用的开销超过隔离收益的情况。
11.2.4 模式四:格式转换和文档生成
用例:将结构化数据或代码转化为产品制品:从 git 历史生成发布说明、从 PRD 生成用户故事、从 commit 消息生成变更日志条目。
工作原理:Subagent 读取源材料(代码、git log、结构化数据),应用转换规则,为特定受众产生格式化输出。
示例:发布说明生成器
Using a documentation writer subagent, generate customer-facing release notes from git commits between v2.4.0 and v2.5.0.
Read commit messages and code changes. Filter for user-facing changes only (exclude refactoring, dependency updates, internal improvements). Categorize as Added, Changed, Fixed, or Removed. Write descriptions in product language, not technical jargon. Output to docs/releases/v2.5.0.md following our standard release note format.
Subagent 读取 git 历史,过滤 commit,将技术更改翻译为客户语言,格式化为结构化发布说明。主会话保持专注于审查和优化输出,而不是处理 100 个 commit。
示例:从需求展开用户故事
Create detailed user stories from the feature description in docs/prds/advanced-filters.md.
Generate 5-8 user stories covering core workflows, variations, edge cases, and admin configuration. For each story, include acceptance criteria, technical notes referencing relevant codebase files, and edge case considerations. Output to docs/user-stories/advanced-filters.md.
Subagent 读取 PRD,探索相关代码库区域获取技术上下文,生成全面的用户故事。你在不干扰主会话的情况下获得制品生成,不会让实现细节占据主会话。
格式转换 subagent 有意义的情况:定期制品生成(每月发布说明、sprint 规划故事创建),受益于隔离的转换任务(读取大量 git log 而不污染主上下文),当你定义了明确的格式标准并希望保持一致时。
定义 subagent 的范围和约束。有效的 subagent 有清晰的边界。定义:
输入范围:"只读取这些文件","处理此 CSV 的第 1-100 行","分析此日期范围内的 commit"。
输出格式:"产生 markdown 表格","使用带有特定章节的列表","遵循 .claude/templates/competitor-profile.md 中的模板"。
约束:"只读分析","不执行代码","允许 web 搜索","最长 5 页报告"。
模糊的 subagent 任务产生模糊的结果。具体的范围产生可用的制品。
汇总 subagent 输出。主 agent 的工作是综合。当五个 subagent 返回五份竞争分析时,不要只呈现五份独立文档。主 agent 应该:
- 读取所有 subagent 输出
- 识别跨分析的模式
- 创建统一比较(功能矩阵、定价表)
- 突出战略洞察(我们的优势和差距所在)
- 产出单一的综合制品
Subagent 生成原始材料。主 agent 产出交付物。
11.3 有效协调多个 Agent
简单的 subagent 使用很直接:启动一个,获得结果,继续。多 agent 工作流需要规划。
规划 agent 分解。在启动 subagent 之前,定义:
哪些是独立的工作单元?四家公司的竞争分析 = 四个独立单元。三个渠道的客户反馈 = 三个单元。功能调查和文档审查 = 两个单元。
依赖关系是什么?所有单元可以并行执行(竞争研究),还是单元 B 依赖于单元 A 先完成(需求先于架构)?
汇总策略是什么?主 agent 综合所有结果,还是某个 subagent 在其他完成后处理综合?
成本收益如何?计算大约 token(subagent 数量 × 每个 subagent 的平均上下文)vs. 节省的时间。如果你为了节省 20 分钟多花了 10 美元 token,这是否值得?
协调模式:顺序、并行、分层。三种基本模式:
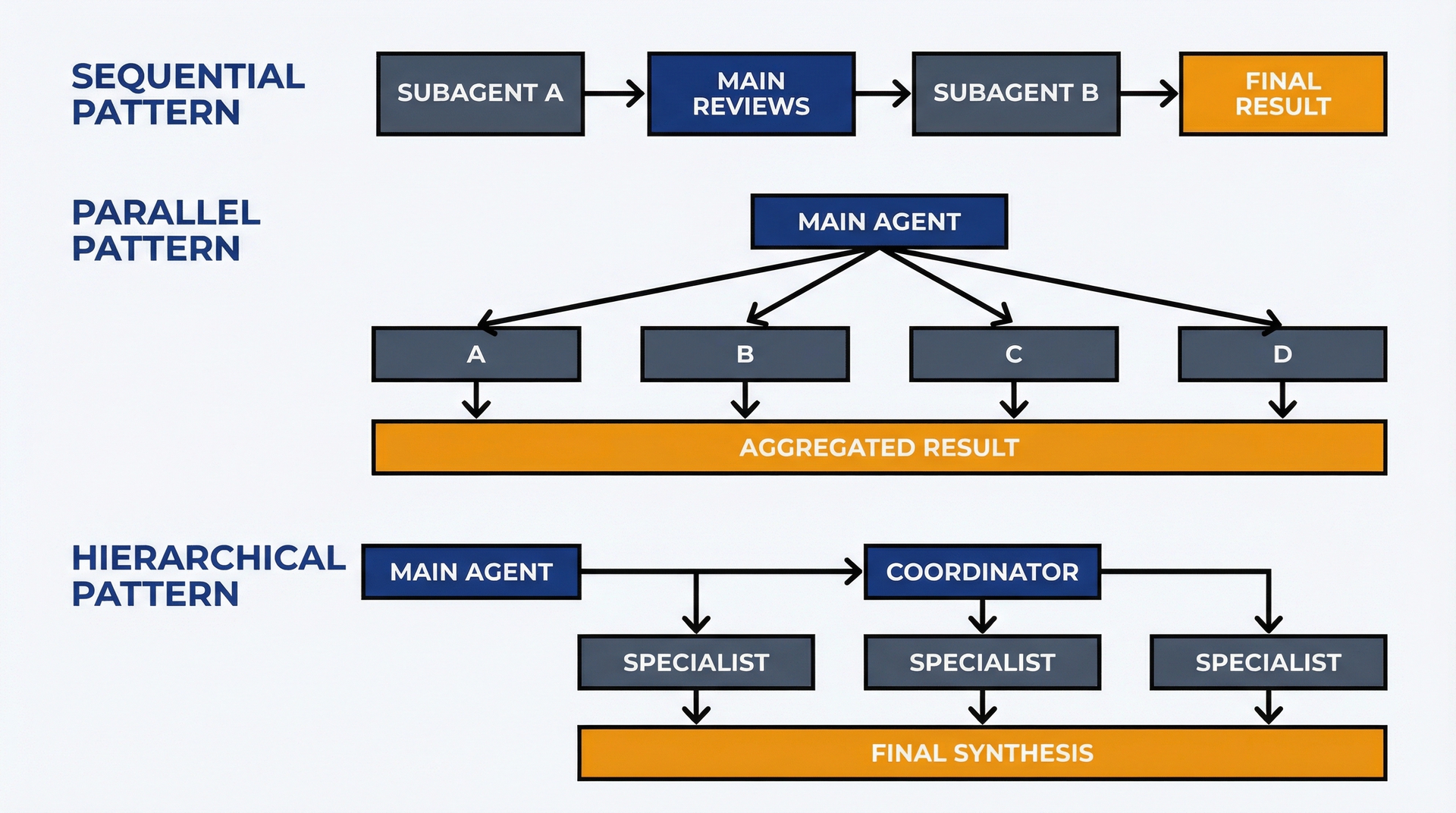
图 11.3:协调模式——用此图选择正确的多 agent 结构。顺序:当存在依赖时按顺序链式调用 subagent。并行:当任务独立时间同时运行所有。分层:为复杂编排添加协调层(PM 工作流很少需要)。
顺序:Subagent A 完成 → 主 agent 审查 → Subagent B 以 A 的输出为起点 → 主 agent 综合最终结果。
使用时机:存在依赖关系,每个阶段需要隔离,你希望在阶段之间有检查点。
并行:Subagent A、B、C、D 全部同时启动 → 所有独立完成 → 主 agent 汇总结果。
使用时机:任务独立,时间节省值得成本,你能有效综合结果。
分层:主 agent 启动协调 Subagent → 协调 Subagent 启动专业 Subagent(或协调顺序调用)→ 协调 Subagent 汇总并返回给主 agent。
使用时机:复杂性高到编排本身受益于隔离。PM 工作流很少需要(增加开销而无明显好处)。
示例:使用三个 subagent 的季度规划工作流。
你正在准备 Q2 规划。你需要市场趋势分析、客户洞察综合和产品指标审查。三个独立的研究任务,然后是战略综合。
提示词:季度规划研究
Conduct Q2 planning research in three parallel streams:
Subagent 1 - Market Trends: Research industry trends in [your domain] over the past quarter. Identify emerging patterns, competitive movements, and market signals. Output: planning/q2-2026/market-trends.md
Subagent 2 - Customer Insights: Synthesize customer feedback from data/q1-feedback/ (support tickets, NPS, user interviews). Identify top themes and priorities. Output: planning/q2-2026/customer-insights.md
Subagent 3 - Product Metrics: Analyze product usage metrics from data/q1-metrics.csv. Identify underperforming areas, growth opportunities, and user behavior patterns. Output: planning/q2-2026/metrics-analysis.md
Once all three complete, synthesize into a unified Q2 strategic brief with recommended priorities.
三个 subagent 并行执行。每个在 8-12 分钟内完成。总经过时间:12 分钟(vs. 35 分钟顺序)。主 agent 读取三份报告,识别市场趋势 + 客户需求 + 指标之间的交叉主题,产出供利益相关者审查的战略简报。
处理 subagent 失败。Subagent 可能因工具访问问题、过于模糊的指令或比预期更难的任务而失败。当 subagent 失败时:
检查错误。是否缺少工具权限?修复 subagent 配置。任务是否太模糊?提供更清晰的范围。是否遇到实际障碍(数据文件缺失)?解决根本原因。
用改进的指令重新运行。不要启动五个新的 subagent。修复具体失败的那个并重试。
退回顺序方式。如果 subagent 编排造成的问题比解决的更多,放弃并行,在主会话中直接处理任务。有些任务不值得这种复杂性。
跨 agent 的成本管理。多 agent 工作流快速消耗 token。控制成本的策略:
设置消费警报。在启动 5-subagent 工作流之前,检查 /cost 并设置心理阈值。如果会话中途成本接近你的限制,取消剩余的 subagent 并切换到顺序方式。
限制并行度。三个 subagent 而非十个。时间节省曲线会趋于平缓。从 1 个到 3 个 subagent 提供显著加速,但从 3 个到 10 个收益递减同时成本倍增。
复用输出。如果所有五个 subagent 需要相同的参考材料,创建一个共享上下文文件让它们都读取,而不是让每个 subagent 进行独立研究。减少冗余 token 消耗。
监控每个任务的成本。完成多 agent 工作流后,记录消耗的总 token。与你的顺序基线比较。如果成本溢价不能通过时间节省来证明合理,下次不要对该工作流使用 subagent。
11.4 限制与何时避免使用 Subagent
Subagent 是一项强大的能力。但它们也经常是错误的选项。
开销与收益阈值。启动 subagent、等待执行、汇总结果都会产生开销。对于 10 分钟以下的任务,考虑到编排时间,顺序执行更快。对于 token 成本低于 0.50 美元的任务,成本倍增不值得。
Subagent 有意义的阈值:需要 20 分钟以上顺序时间的任务,已经消耗大量 token(这样倍增基于有意义的基数),加速时能带来明确的时间价值。
上下文隔离的挑战。Subagent 以干净的上下文启动。当你想要专注时这是特性。当上下文很重要时这是限制。
如果你正在迭代一个 PRD,要求 subagent"为高级搜索功能添加用户故事",subagent 不记得你之前关于目标用户画像、技术约束或产品策略的讨论。它从零开始。你需要将这些上下文在提示词中明确提供,这往往比直接在会话中继续顺序讨论花费更长时间。
调试多 agent 问题。当顺序提示失败时,你能看到思考过程,可以审查中间步骤并诊断问题。当 subagent 失败时,你得到一个最终错误。没有中间输出,没有透明的思考模式。调试需要带着改进后的指令重新运行 subagent,并希望你已修复了问题。
对于需要控制和透明度的关键工作,带有逐步监督的顺序提示胜过 subagent 委派。
通常更好的更简单替代方案。在启动 subagent 之前,考虑:
带有明确阶段的顺序提示。"首先,分析竞争对手定价。然后,基于该分析,识别我们定价策略中的差距。"这提供了类似的阶段隔离,而没有 subagent 开销。
技能(第九章)。如果工作流会重复,将其编码为 skill,而不是每次都编排 subagent。技能提供一致性而无需多 agent 复杂性。
在单个会话中分块。"处理前 100 条反馈并总结主题。然后我让你处理下 100 条。"这保持了上下文连续性,同时将工作分解为可管理的块。
外部工具。某些任务(大规模数据分析、复杂报告生成)最好由专门构建的工具(分析平台、BI 工具)处理,而不是 Claude Code subagent。如果你发现自己在例行地启动 10 个 subagent 来处理数据,你可能需要更好的工具,而不是更好的编排。
成功的团队从简单开始:顺序提示,为重复工作流使用 skill,仅在测量证明 subagent 值得其成本时才使用。挣扎的团队在写任何一行代码之前就构建了复杂的多 agent 系统。
Subagent 是用于特定瓶颈的工具,不是默认方法。当并行性明显节省的时间价值超过 token 溢价时才使用它们。对于其他一切,简单更好。
你现在理解了 subagent 是什么,何时它们能带来价值而非倍增成本,适用于 PM 工作流的四种实用模式,以及如何编排多 agent 工作而不构建不必要的复杂性。你也知道何时完全避免 subagent。更简单的顺序方法往往以更少的开销提供更好的结果。
第十二章从自动化转向协作:如何在 PM 和工程师都使用 Claude Code 时与工程团队有效合作,共享制品,维持高效的交接协议。
第12章
与工程团队协作
你已经使用 Claude Code 好几周了。你的 bug 调查更快了,你的功能问题不用中断 sprint 就能得到解答,你的 PRD 引用了实际的实现。然后工程团队也开始使用 Claude Code:相同的仓库、相同的会话、相同的工具。当两个角色在同一个 AI 增强的工作空间中工作时会发生什么?
做得好时,这种重叠能放大双方的角色。PM 调查更快,工程师在交接时获得更好的上下文,共享制品减少沟通错误。做得不好时,它会制造领地摩擦、重复工作和 CLAUDE.md 文件中的冲突指令。本章涵盖 PM 与工程团队 Claude Code 使用的接口:共享什么,何时交接,以及如何维持高效的边界。
12.1 PM 与工程使用的重叠之处
PM 和工程师以不同的方式使用 Claude Code。理解这些差异可以防止相互干扰。
互补的使用模式。工程师使用 Claude Code 编写和修改代码:实现功能、修复 bug、重构系统。他们的会话涉及文件编辑、测试运行和部署任务。PM 使用 Claude Code 进行调查和生成制品:理解实现、综合研究、创建文档。大多数 PM 会话在 plan 模式下运行;大多数工程会话不是。
PM 和工程团队在并行工作流中使用 Claude Code。PM 进行调查、生成制品并在 plan 模式下工作。工程师编写代码、修复 bug 并使用完全访问权限。中间的共享上下文连接双方。
这种自然的分工意味着重叠很少见。一个工程师修改 checkout.service.js 不会与一个 PM 要求 Claude Code 解释 checkout 如何工作产生冲突。PM 读取;工程师写入。不同的工具权限、不同的输出、不同的工作流。
重叠创造价值的地方在于共享上下文。当双方通过同一个工具理解同一个代码库时,交接变成会说同一种语言的人之间的对话。PM 说"我调查了 discount-validator.js:45-78 中的折扣验证逻辑,发现当 cart.hasActivePromotion 为 true 时它会拒绝折扣码。"工程师知道确切要看哪里以及 PM 理解了什么。不需要翻译层。
避免领地冲突。当角色边界模糊时会产生冲突。开始编辑代码的 PM(即使是出于好意)会造成所有权混淆。因为"你不懂代码"而否定 PM 调查发现的工程师会破坏协作。
清晰的边界防止摩擦:
- PM 调查和解释;工程师验证和实现
- PM 建议问题可能在哪里;工程师确认根本原因
- PM 创建产品制品(PRD、发布说明);工程师创建技术制品(ADR、代码注释)
- PM 使用 plan 模式进行探索;工程师使用完全访问权限进行实现
当你想要越过边界(编辑配置文件、运行数据库迁移、推送一个"简单修复")时,停下来改为交接。你节省的五分钟不值得造成谁拥有什么的混淆。
共享制品和版本控制。Claude Code 生成的制品供两个角色使用。发布说明、架构文档、功能解释、调查摘要:这些与代码一起存放在仓库中。将它们视为任何其他版本化资产。
Claude Code 创建的文件应遵循现有的仓库规范。如果你的团队使用 docs/ 存放文档,Claude Code 输出放在那里。如果 commit 消息遵循某种格式,保持一致。AI 生成的内容没有什么特殊;它只是需要遵循规则的内容。
使用 git commit 跟踪谁在何时创建了什么。Claude Code 默认在 commit 中添加 Co-Authored-By: Claude
就 AI 辅助工作进行沟通。当你分享调查发现或生成的制品时,对过程保持透明。"我使用 Claude Code 调查了这个问题,以下是我的发现"设定了适当的期望。读者知道要验证技术细节,而不是将其视为权威。
这种透明度是双向的。当工程师使用 Claude Code 生成文档或分析时,他们也应注明。目标不是推卸责任(你仍然对输出负责),而是表明它是如何产生的,以便审查者适当调整他们的审查强度。
12.2 转换工作而不丢失上下文
PM 与工程的边界不是一堵墙。它是一个过渡区。良好的交接使这个过渡顺畅。
PM 调查何时结束,工程何时开始。第四章涵盖了何时停止调查 bug。相同的原则适用于所有 PM 到工程的交接。当你能够解释流程、有一个可测试的假设、识别了相关文件并知道你不知道什么时,你已经收集了足够的上下文。
对于功能调查,当你能够回答你的产品问题时停止。"checkout 如何工作?"在你理解流程到足以做出产品决策时得到回答。你不需要理解每个函数。
对于问题报告,当你有可供工程操作使用的上下文时停止。文件路径、可疑代码区域、复现假设、开放问题。工程从那里接手。
对于制品生成,当你有一个值得审查的草稿时停止。不要无限迭代试图完善发布说明。从工程获取准确性反馈,然后定稿。
交接时机是当额外的 PM 调查收益递减而工程调查收益加速时。你擅长上下文收集和假设形成。他们擅长验证和实现。在拐点处过渡。
PM 到工程的交接工作流。PM 调查阶段包括上下文收集、假设形成和文件定位。中间的交接包记录了触发调查的原因、发现的内容、尚未确定的内容以及需要工程做什么。然后工程处理验证、根本原因分析和实现。
为交接包装信息。为工程消费结构化你的交接:
调查摘要应包括:
- 触发调查的原因(用户报告、产品问题、规划需求)
- 你调查了什么(阅读的文件、追踪的流程、询问的问题)
- 你发现了什么(解释、假设、相关代码位置)
- 你无法确定什么(运行时行为、数据依赖逻辑、配置问题)
- 你需要工程做什么(验证、根本原因确认、实现)
制品的草稿应包括:
- 使用的源材料(git 历史、反馈数据、竞争研究)
- 方法(你使用了什么提示词,Claude Code 分析了什么)
- 开放问题(准确性疑虑、缺失的上下文、需要的验证)
- 请求的反馈(技术准确性、完整性、语气)
糟糕的交接:"我觉得 checkout 有个 bug。你能看看吗?"
良好的交接:"用户报告扣款但没有订单确认。我调查发现支付处理发生在 payment-processor.js 中,订单创建在之后的 order.service.js 中。如果支付成功后订单创建失败,payment-reconciliation.js 中的对账队列应该捕获它。假设:对账队列未在处理,或者错误未被处理。你能验证队列状态和最近的失败吗?用于调查的客户 ID:[ID]。"
良好的交接通过提供消除发现工作的上下文来尊重工程时间。
将 Claude Code 输出作为对话起点,而非结论。你的调查发现是假设,不是事实。Claude Code 基于静态分析解释代码。它没有运行代码、检查生产数据或咨询原始作者。
相应地框架交接。"我认为这可能是问题所在"而非"这就是 bug"。"代码似乎是……"而非"代码就是……"工程应在行动前验证。
这种框架不是虚假的谦虚。这是准确的认识论定位。你进行了彻底的调查,形成了合理的结论,但你是基于不完整的信息工作的。工程拥有运行时数据、部署上下文和你没有的深层系统知识。他们可能确认你的假设,也可能发现不同的东西。两种结果都是有价值的;错误的是将 PM 调查当作工程分析来行动。
尊重工程专业知识和判断。你为工程节省了数小时的发现工作,但这不让你成为工程师。当他们不同意你的假设时,倾听。当他们解释代码为什么不按 Claude Code 描述的方式工作时,学习。当他们基于你不理解的实现复杂性做出与你预期不同的优先级排序时,信任他们的判断。
PM 代码库调查的目标不是取代工程。而是减少角色之间的沟通负担。你可以在不能实现解决方案的情况下进行有见地的对话。这就是边界。保持在你的一侧。
12.3 维护两个角色都能使用的上下文
CLAUDE.md 文件在多个会话间保持上下文。当多个人在同一个仓库中工作时,维护共享上下文成为协作责任。
两个角色都受益的产品知识。一些 CLAUDE.md 内容为所有人服务:

CLAUDE.md 内容所有权以重叠圆圈显示。PM 特定内容包括研究方法和利益相关者沟通规范。工程特定内容包括构建命令和部署配置。共享中心包含领域术语、架构概览、业务规则和用户旅程到代码的映射。
领域术语防止任何 Claude Code 用户的误解。无论是 PM 在调查还是工程师在实现,知道"credit"意味着内部货币(而不是支付信用)很重要。
架构概览帮助 PM 理解在哪里查找,帮助工程师引导新团队成员。组件边界和数据流的简要描述服务于双方受众。
业务规则和约束属于共享上下文。"折扣码不能与促销活动组合"和"免费层用户限制 5 个工作区"是代码应当遵守的产品规则。两个角色都需要这个上下文。
用户旅程映射到代码帮助 PM 调查,帮助工程师理解更改的产品影响。从"checkout 流程"到"CheckoutForm.tsx → checkout.service.js → payment-processor.js → order.service.js"的映射服务于双方。
PM 特定的内容(研究方法、利益相关者沟通规范)可能属于个人 ~/.claude/CLAUDE.md 或 docs/pm-workflow.md 文件而非共享的 project CLAUDE.md。
将维护准确性作为共同责任。CLAUDE.md 内容会过时。代码路径改变,术语演变,业务规则更新。需要有人维护准确性。
像对待任何文档一样对待 CLAUDE.md。当你发现错误时,修正它。如果 checkout 流程现在在支付和订单创建之间包含欺诈检测步骤,更新用户旅程映射。如果团队将"credits"重命名为"coins",更新术语。在常规工作中进行小修复可以防止大偏差。
对于重大变化(新产品领域、架构大改、重大术语变更),创建文档任务。不要让 CLAUDE.md 的准确性持续偏离,直到有人注意到 Claude Code 给出了错误建议。
CLAUDE.md 内容的冲突解决。当 PM 和工程的视角在 CLAUDE.md 应包含什么上有分歧时,基于使用模式来解决。
偏好具体性而非全面性。一个有 50 行高价值内容的专注 CLAUDE.md 胜过一份 500 行什么都涵盖的文档。包括改善 Claude Code 响应的内容;排除好但不常用的内容。
偏好准确性而非愿景。记录事物实际如何运作,而非它们应该如何运作。如果代码有技术债务你计划处理,不要将未来状态描述为当前状态。Claude Code 读取代码,冲突的 CLAUDE.md 指令会造成困惑。
偏好共享理解而非角色特定的细节。只有 PM 使用的内容可能不属于共享 CLAUDE.md。只有工程师使用的内容可能也不属于。共享上下文意味着帮助这个仓库中所有使用 Claude Code 的人的内容。
当冲突持续时,尝试两种方法几周,看哪个产生更好的结果。CLAUDE.md 不是不可更改的。它是通过使用来改进的迭代文档。
审查节奏和所有权。季度 CLAUDE.md 审查与其他文档维护节奏对齐。一个人应负责审查:通常是使用 Claude Code 最频繁的 PM,或最理解架构上下文的 tech lead。
审查检查清单:
- 所有文件路径仍然准确吗?
- 任何术语定义改变了吗?
- 用户旅程映射与实现最新同步吗?
- 业务规则有变化需要更新文档吗?
- 有文档化但不再存在的内容吗?
- 有新的应该被文档化的内容吗?
30 分钟的季度审查防止 CLAUDE.md 逐渐变得无用。将它视为任何活文档:通过使用来维护,定期审查,增量更新。
12.4 构建服务整个团队的技能
技能(第八章)在共享时变得更有价值。PM 构建了一个效果很好的反馈综合 skill;工程也能从中受益。工程师创建了发布说明 skill;PM 用于客户沟通。仓库中的 .claude/commands/ 目录存放两个角色都能调用的团队工作流。
服务多个角色的技能。一些工作流使所有人受益:
发布说明生成将 git 历史转化为面向客户的沟通。PM 想要可读的摘要;工程师想要准确的更改归属。一个 skill 以适合受众的输出服务两种需求。
文档审计比较文档与实现。PM 想要知道产品描述是否符合现实;工程师想要发现过时的技术文档。相同的审计逻辑,相同的收益。
架构总结解释代码库结构。PM 用于上手和调查;工程师用于新团队成员上下文和跨团队协作。
将这些共享 skill 存储在 .claude/commands/ 中,使用清晰的名称:generate-release-notes.md、audit-documentation.md、summarize-architecture.md。团队中的任何人都可以用 /project:generate-release-notes 调用它们。
贡献指南。共享 skill 需要一致性:
命名规范使 skill 可发现。一致使用动词-名词格式(generate-release-notes、audit-documentation、analyze-feedback)。
文档要求解释每个 skill 做什么。包含带有目的、预期输入和输出格式的头部注释。第一次遇到该 skill 的人应该在不阅读完整实现的情况下理解其功能。
测试期望确保 skill 在团队采用前可工作。用真实数据运行 skill,验证输出质量,并文档化限制。一个 80% 时间有效且失败模式不清晰的 skill 造成的挫败感大于价值。
版本控制跟踪更改。用清晰的 commit 消息提交 skill 修改。当 skill 行为变化时,团队成员应该能够追溯原因和时间。
共享 skill 的质量标准。在将 skill 添加到共享库之前,验证:
- 它解决一个重复出现的问题吗?一次性任务不需要 skill。
- 它可靠吗?需要不断调整的 skill 还不能分享。
- 它有文档吗?用户应该理解输入、输出和限制。
- 它足够通用吗?只适用于某个 PM 特定工作流的 skill 可以保持个人使用。
共享 skill 的质量标准高于个人 skill。你的个人工作流容忍粗糙边缘,因为你知道那些怪癖。共享 skill 需要对所有人可预测地工作。
弃用和清理。不再使用的 skill 应该被移除。出问题的 skill 应该被修复或弃用。功能重复的 skill 应该被合并。
季度 skill 库审查(与 CLAUDE.md 审查对齐)防止积累破损或未使用的工作流。检查使用情况(git log 显示谁调用了什么),验证当前功能,移除不再服务团队的内容。
Skill 库是团队资产。以与生产代码相同的关心对待它:提交前测试,审查更改,维护质量,弃用不再使用的。
你现在理解了当双方都使用 Claude Code 时如何与工程团队有效协作。互补的使用模式防止领地冲突。清晰的交接协议在高效共享上下文的同时尊重专业边界。共享的 CLAUDE.md 实践维护两个角色都受益的持久知识。团队 skill 库编码服务整个组织的工作流。
第十三章讲解了失败模式:PM 在使用 Claude Code 时常犯的错误以及如何识别你已到达收益递减点。
第13章
失败模式与边界
你已经读了十一章关于 Claude Code 能做什么的内容。本章讲述什么地方会出错、何时该停下、以及 PM 使用的边界在哪里。每个工具都有局限。在撞到它们之前就知道,比通过代价高昂的错误来学习更便宜。
从 Claude Code 中获得持久价值的团队都有一个模式:他们快速失败,识别失败模式,并调整。挣扎的团队不断撞到同一堵墙,因为他们没有识别出模式。本章命名这些模式,以便你能打破它们。
13.1 常见的 PM 失败模式
五种失败模式是大多数 PM 对 Claude Code 感到挫败的原因。每种都是可预测的,每种都有警告信号,每种都有直接的补救方法。
PM 使用 Claude Code 的五种常见失败模式
13.1.1 需求文档倾倒
表现:你将整个 PRD 粘贴到 Claude Code 中,要求它"实现这个功能"或"为所有内容创建用户故事"。回复要么流于表面、过于笼统,要么 Claude Code 提出太多澄清性问题,你做的工作比自己写故事还多。
为什么失败:Claude Code 最适合专注的、有范围的请求。一份 15 页的 PRD 包含数十个隐含的决策、未声明的假设和你脑海中的上下文。全部倾倒并期待奇迹只会产出垃圾。
模式:大输入加模糊指令产生大输出加模糊效用。
修复方法:将 PRD 分解为具体的、可操作的请求。"为第 3.2 节描述的认证流程创建用户故事"是有范围的。"基于第 5 节中的错误处理需求,识别 src/errors/ 中哪些现有错误消息需要更新"将 PRD 与代码库调查结合了起来。逐节处理 PRD,每一步都获得有用的输出,而不是指望一次大规模综合。
警告信号:你的提示词超过 500 字,而你的指令少于 20 字。翻转这个比例。
13.1.2 对代码分析过度自信
表现:Claude Code 解释了你的代码库中认证是如何工作的。你将这个解释当作事实带给工程团队。工程指出分析遗漏了一个关键的中间件层,或误解了一个异步模式,或描述的是已弃用的流程而非当前流程。
为什么失败:Claude Code 静态地读取代码。它看不到运行时行为、依赖配置的路径或哪些代码路径在生产中实际被使用。它也不知道代码库的哪些部分是积极维护的,哪些是没人碰的遗留垃圾。它的分析通常是正确的,但"通常"不是"总是"。
模式:静态分析被当作运行时真相,产生自信但错误的结论。
修复方法:将 Claude Code 的分析框架为假设,而非结论。当你与工程分享发现时,使用这样的语言:"根据我的调查,认证流程似乎是这样工作的。你能确认吗?"这邀请纠正,而不是迫使工程师反驳你。你的调查通过缩小问题空间来增加价值,而不是通过提供最终答案。
警告信号:你即将仅基于 Claude Code 的代码分析做出产品决策或承诺,而没有工程验证。停下来先验证。
13.1.3 上下文耗尽
表现:你进入会话三十分钟了。Claude Code 的回复变得不太连贯。它开始建议你已经尝试过的东西。它"忘记"了之前读过的文件。它引用了会话早期不正确的细节。
为什么失败:你发送的每条消息和 Claude Code 读取的每个文件都在上下文窗口(一个保存你整个会话的 200,000 token 缓冲区)中累积。随着上下文填满,Claude Code 必须总结或丢弃较早的内容来容纳新内容。重要细节在压缩中丢失。
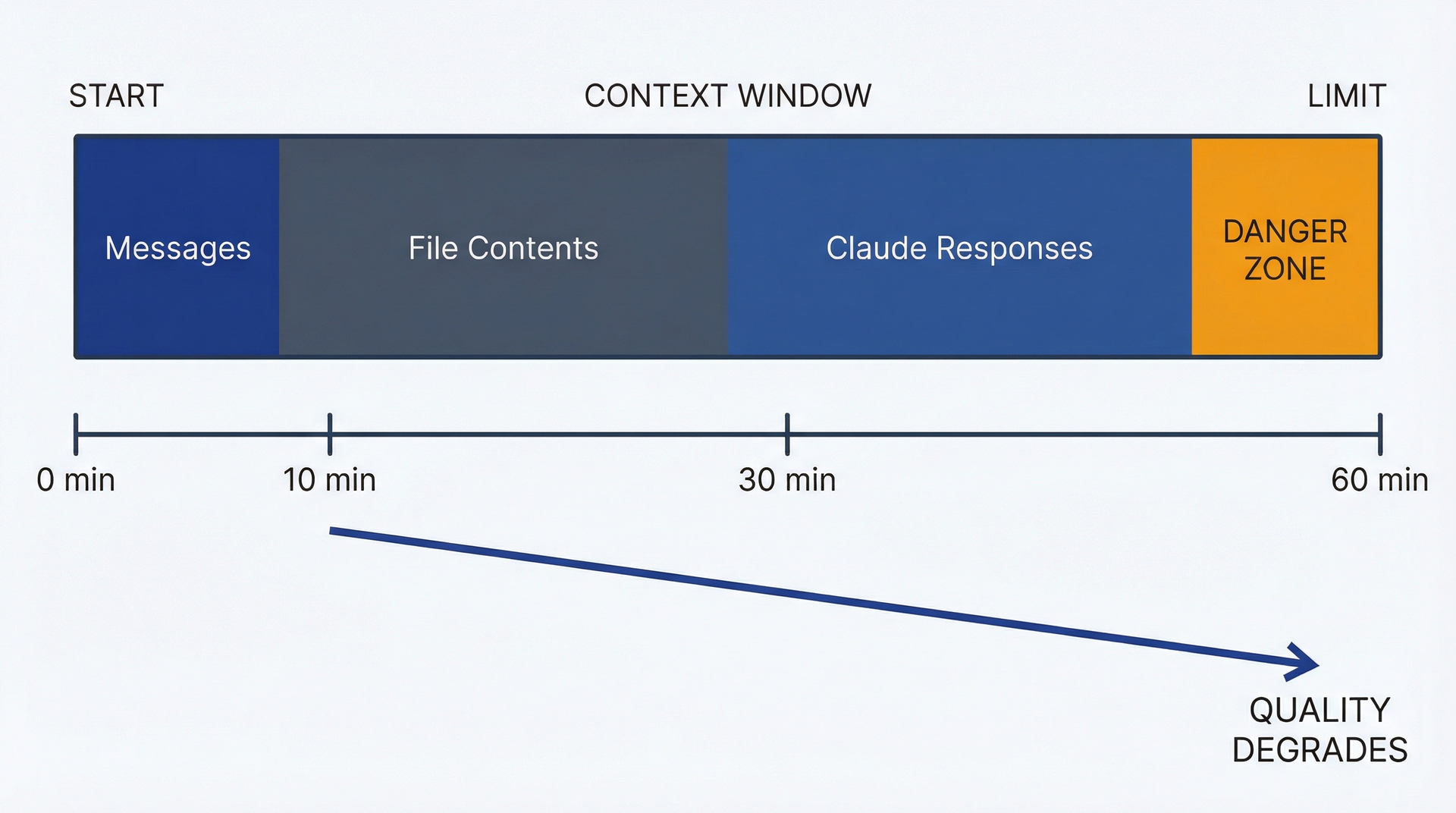
上下文如何在一个会话中累积以及质量如何下降
现代 Claude 模型不会静默截断你的上下文。它们返回错误而不是隐蔽地降级。但在达到那个硬限制之前,质量会随着上下文填满而下降。用户报告 Claude 在上下文压缩后变得"明显更笨",忘记它在检查哪些文件,重复会话早期已经做出的纠正。
模式:长会话累积上下文直到连贯性下降,然后下降加速。
修复方法:主动使用 /clear。为不相关的任务启动新会话,而不是继续一个马拉松式的单次会话。如果你需要继续而上下文很大,使用 /compact 并指定要保留的内容:/compact Focus on the authentication flow analysis; discard the earlier database investigation.
警告信号:
- /cost 显示上下文接近 150,000+ token
- Claude 重复你已经拒绝的建议
- Claude 问你已经回答过的问题
- Claude 错误引用文件或将不同代码路径混淆
13.1.4 工具错配
表现:你在用 Claude Code 回答一个 Claude.ai 同样能处理的问题。你启动了一个会话,等待启动,输入你的问题,等待它并不需要的文件扫描,得到的是一个不需要任何代码库访问的答案。你花了两分钟完成一个在 Claude.ai 中只需三十秒的任务。
为什么失败:Claude Code 的优势在于文件系统访问、代码库调查和制品生成。对于不需要这些能力的问题,它增加了开销而没有价值。在不必要的 Claude Code 会话中花费的每一分钟,都是没有花在真正需要这个工具的工作上的一分钟。
模式:将 agentic 工具用于对话式任务,产生摩擦而没有收益。
修复方法:在启动 Claude Code 之前,问自己:"这个任务需要读取文件、生成制品或执行命令吗?"如果不需要,使用 Claude.ai。第一章的决策矩阵适用于你整个使用过程,而不仅仅是初始采用时。
更适合 Claude.ai 的常见 PM 任务:
- 头脑风暴功能创意
- 优化演示文稿要点
- 编辑邮件草稿
- 解释一般概念(非代码库特定)
- 不需要文件输出的快速竞争研究
警告信号:你将 Claude Code 作为默认 AI 界面使用,而不是基于任务匹配来选择。将工具匹配到任务。
13.1.5 技能过度工程
表现:你花了三个小时构建一个用于生成季度业务回顾的综合 skill。它有五个参考文件、一个复杂的输出模板,并处理了你想到的边缘情况。你只用了它一次。下个季度,需求变了,skill 需要重新修改,花费的时间比从头创建 QBR 内容还长。
为什么失败:Skill 通过重复使用提供 ROI。一个需要两小时构建、每次使用节省三十分钟的 skill 需要四次使用才能回本。如果任务频繁变化,或者你每年只做一次,skill 永远无法收回创建成本。
模式:为一次性任务构建基础设施,产生维护负担而没有效率增益。
修复方法:在构建 skill 之前应用"三次"规则。这个任务你已经做了至少两次了吗,并且下个季度你至少还会再做一次吗?如果不是,使用提示词模板代替。将提示词保存到文本文件以备将来参考,而无需 skill 结构的开销。
警告信号:你兴奋地在真正手动完成底层任务之前构建 skill。先手动做。理解什么会变、什么不变。然后(也许)将其编码为 skill。
13.2 知道何时你已经榨取了可用价值
每个会话都有自然的生命周期。超过它只是浪费时间和 token 而没有额外价值。
你已经榨取可用价值的信号:
答案开始重复。Claude Code 用不同的措辞重述已经告诉过你的事情。你在问同一个问题不同变体,希望得到新洞察。代码库中没有更多洞察了。你已经找到了那里有的东西。
你理解了问题的轮廓。你能解释相关代码区域、数据流、潜在的故障点。你可能不理解每一行,但你可以与工程进行有见地的对话。进一步调查的边际回报很小。
你的问题变得比代码库能回答的更具体。你在问"团队为什么选择这种方法?"或"如果 10,000 个用户同时这样做会怎样?"这些问题需要人的上下文或生产测试,而不是代码阅读。Claude Code 已经给了你静态分析能提供的一切。
你的假设是可测试的。你对 bug、架构或实现有一个具体的理论。下一步是通过工程审查、测试或生产观察来验证,而不是更多调查。
"再一个提示词"陷阱:在有价值的调查之后,有一种再问一个问题、再探索一个文件、再获取一个摘要的诱惑。有时这能带来价值。但更多时候,它是伪装成彻底的拖延。你已经有足够的信息来行动,但你只是还没有准备好行动。
自我测试:如果有人现在问你"你学到了什么?"你能给出一个连贯的答案吗?如果能,你很可能已经有足够的信息了。记录你的发现并继续前进。
会话时长指南:
| 任务类型 | 典型有用时长 | 何时停下 |
|---|---|---|
| 快速问题 | 2-5 分钟 | 第一个有用的答案 |
| 功能调查 | 15-30 分钟 | 你能解释流程 |
| Bug 分类 | 20-40 分钟 | 你有一个可测试的假设 |
| 研究综合 | 30-60 分钟 | 主题已识别并文档化 |
| Skill 构建 | 45-90 分钟 | Skill 持续产生有用输出 |
| 深度代码探索 | 60-90 分钟 | 每个提示词的新信息递减 |
如果你超过这些范围而没有获得明确的价值,你很可能处于收益递减中。长会话并非本质上是坏事;有些调查确实需要深度。但如果你到了九十分钟仍然没有找到答案,答案可能不存在于代码中,或者你问了错误的问题。
何时重新开始:在以下情况使用 /clear 并开始新会话:
- 你完成了一个任务并开始一个不相关的任务
- 出现上下文耗尽的症状
- 你走上了一条无成效的路径,想尝试不同的方法
- 你的提示词变得又长又绕,试图提供 Claude 已经"应该"拥有的上下文
- 会话开始以来超过两小时
重新开始只会花费你重新定位的三十秒。继续一个降级的会话则要花费持续的挫败感和日益加重的困惑。
13.3 属于工程领域的任务
无论工具如何,有些任务超出了 PM 的范围。Claude Code 不改变谁拥有什么。它改变的是你在你的范围内工作的效率。
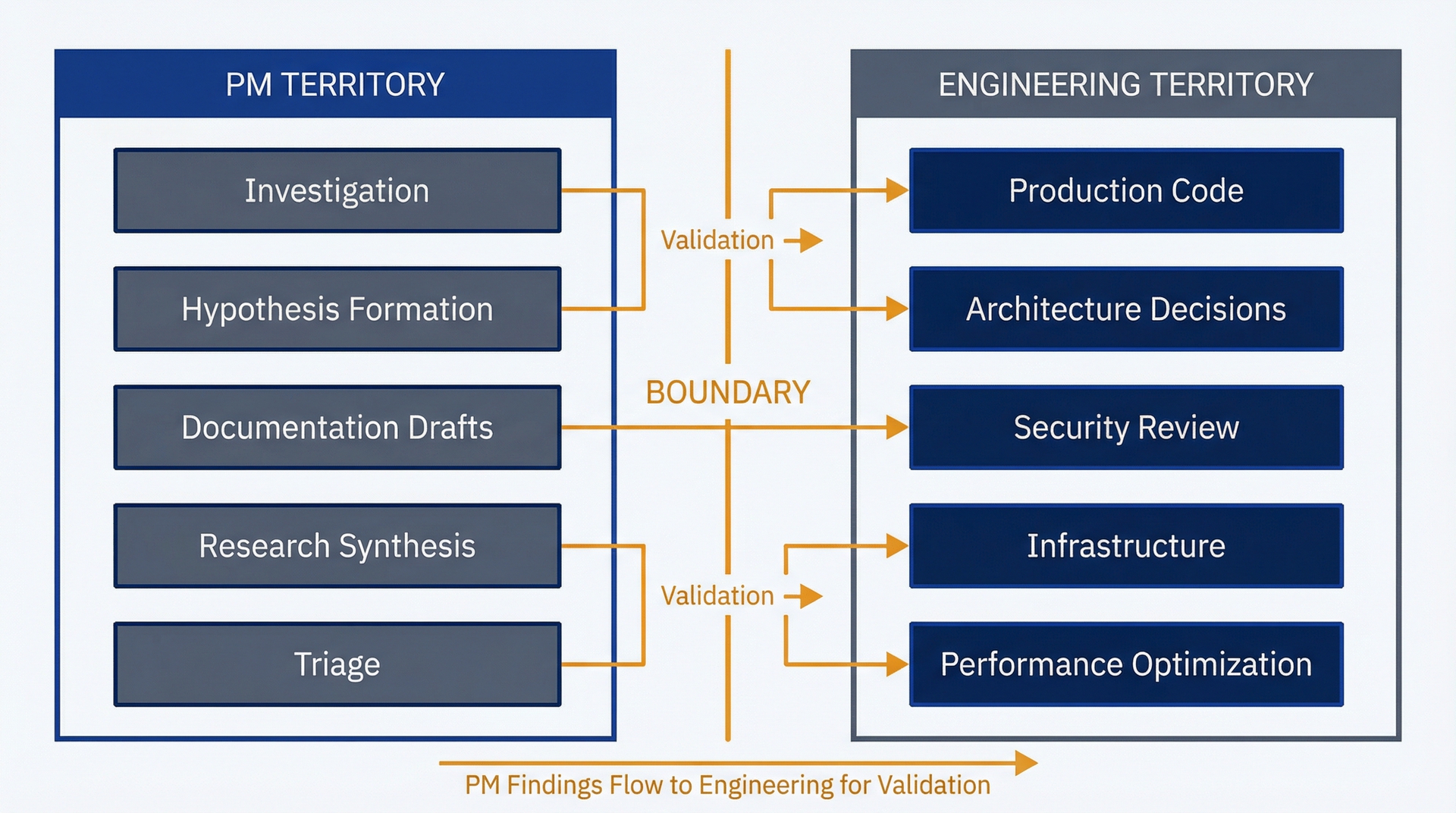
PM 领域与工程领域之间的边界
13.3.1 需要工程所有权的任务
编写生产代码。Claude Code 可以生成代码。它甚至可以生成能工作的代码。但运行在生产环境中的代码需要工程审查、测试和所有权。即使你能直接合并代码,你也不应该。问题不在于能力;而在于问责制。当那段代码在凌晨 3 点出故障时,被呼叫的是工程师,不是你。
架构决策。你的调查可能发现认证系统很绕,或数据库 schema 不够优化。Claude Code 甚至可能建议改进方法。这些是工程决策的输入,而不是决策本身。架构选择有长期后果,需要工程判断。
性能优化。Claude Code 的静态分析可以识别潜在的性能问题,但不能测量实际性能。优化需要对生产负载进行性能分析、理解使用模式以及做出影响系统行为的权衡。工程拥有这一块。
基础设施变更。部署配置、数据库迁移、服务器供应:这些是工程领域。Claude Code 可以帮助你理解现有基础设施或起草关于它的文档,但更改它需要工程所有权。
13.3.2 你应始终升级处理的安全工作
认证和授权审查。如果你在调查认证流程或访问控制逻辑,你的发现是安全审查的假设,不是结论。安全 bug 可能暴露客户数据、损害声誉并产生法律责任。即使 Claude Code 的分析看起来正确,安全审查必须涉及专家。
密钥和凭据的处理。Claude Code 可能揭示你的应用如何存储 API key 或管理 token。这些信息是敏感的。不要大范围分享。如果你发现潜在的安全问题(硬编码的密钥、不足的加密),升级给工程和安全团队。不要试图修复。
合规相关代码。如果代码涉及合规要求(GDPR、HIPAA、SOC 2、PCI DSS),Claude Code 的分析是合规审查的输入,不是替代品。合规错误会产生监管后果。
13.3.3 为什么生产环境访问是禁区
对生产数据的数据库查询。第十章讲解了数据库 MCP 集成,并给出了明确指导:使用只读副本,绝不用生产数据库。即使对生产数据库的读操作也可能导致性能问题,任何写操作都可能破坏数据。Claude Code 能生成 SQL 的能力并不意味着它应该在生产环境上执行。
生产日志和监控。如果你需要读取生产日志进行调查,通过你组织既定的访问模式来读取,而不是通过 Claude Code MCP 连接。生产环境访问通常需要 Claude Code 会绕过的特定权限和审计追踪。
实时客户会话。调试客户问题可能引诱你访问他们的实际数据。不要。使用匿名化的导出数据、测试账户或 staging 环境。客户数据访问有隐私影响,不管你的意图如何。
13.3.4 在分析中保护隐私
分析中的 PII。当你将客户反馈提供给 Claude Code 进行综合时,先去除个人身份信息。姓名、电子邮件地址、电话号码:在处理之前删除。Claude Code 的分析不会因 PII 而改善,你也能避免隐私风险。
原始支持工单。支持工单通常包含客户姓名、账户详情和敏感信息。提取相关内容(bug 报告、功能请求)而不带识别包装。你的综合是关于模式,而非个人。
出口管制。如果你的产品服务于受监管行业,了解什么数据可以被外部 AI 服务处理。一些组织禁止将某些数据类型发送给云 AI 提供商。本地运行的 Claude Code 与 API 调用不同,但请与你的法务和安全团队确认。
13.3.5 满足监管要求
审计追踪。Claude Code 会话存储在本地机器上。如果你的组织对某些决策或文档要求审计追踪,Claude Code 的会话历史可能不满足这些要求。将输出捕获到你组织的官方记录系统中。
更改文档。如果你使用 Claude Code 生成影响产品决策的文档(PRD、用户故事、需求),这些文档应经过你正常的审查和批准流程。Claude Code 生成了草稿;你对内容负责。
受监管的沟通。一些行业要求客户面向文档有特定格式或审查流程。Claude Code 可以帮助起草内容,但内容在发布前必须经过既定的批准工作流。
13.4 使 Claude Code 长期奏效的习惯
在数月数年里有效使用 Claude Code 需要习惯,而非英雄行为。
每周使用回顾。每周花十分钟回顾:
- Claude Code 帮助了什么任务?
- 什么做得好?什么令人沮丧?
- 我碰到了任何失败模式吗?哪些?
- 我的 skill 仍然准确吗?还是需要更新?
这种反思会产生复利。一个月后,你会识别出你的个人模式:Claude Code 擅长什么任务、你容易陷入什么失败模式、值得维护什么 skill。没有反思,你会无限期地重复错误。
成本监控习惯。对于 API 用户:第一个月每周检查你的 Anthropic 仪表板,之后每月检查。对于订阅用户:在会话结束时偶尔检查 /cost 来了解你的使用模式。两组用户:审查支出是否与获得的价值对齐。如果成本相对于价值显得高,你在用 Claude Code 做错误的任务。如果成本相对于价值显得低,你可以更主动地使用它。
Skill 维护计划。Skill 会腐烂。你的代码库变化,需求演变,更好的方法出现。每个季度审查每个 skill:
- 这个 skill 仍然产出有用的输出吗?
- 它自动化的任务有显著变化吗?
- 它可以简化或与其他 skill 合并吗?
- 它应该被淘汰吗?
Skill 是一种投资。像所有投资一样,它们需要维护才能保持有价值。
紧跟 Claude Code 更新。Claude Code 定期更新,带来新功能、行为变化和改进的模型。每月检查 changelog(code.claude.com/changelog 或 CLI 中的发布说明)。新功能可能解决你目前正在绕弯子的问题。行为变化可能破坏你依赖的工作流。
如果可用,订阅更新频道。当你遇到意外行为时,在假设你做错了什么之前,先检查是否有最近的更新。
可持续的节奏:每周反思,每季度 skill 审查,每月更新检查。这些习惯每月总共花费三十分钟。它们防止你个人 Claude Code 使用中技术债务的积累:过时的 skill、重复的错误、错过的能力。
你现在知道了五种常见的 PM 失败模式及其补救方法,如何识别收益递减以及何时停下,PM 使用在哪里有硬边界,以及如何建立可持续的长期实践。本章不如关于能力的章节那么令人兴奋,但知道何时停下以及何处不应该去,正是区分有效用户和挫败用户的关键。
这完成了第六部分和本书的主要内容。接下来的附录提供了参考资料:命令语法、skill 模板、CLAUDE.md 示例文件以及供你工作中快速查阅的提示词模板。
附录 A
附录 A:命令参考
本参考涵盖与 PM 工作流相关的 Claude Code 命令和选项。在任何会话中运行 /help 查看完整的最新列表——Claude Code 会定期添加功能。
每次会话都会用到的命令
你在会话中键入的命令。所有命令以 / 开头。
会话管理
| 命令 | 用途 |
|---|---|
| /help | 显示所有可用命令,包括项目中的自定义命令 |
| /status | 显示当前会话状态:权限模式、上下文使用、模型、认证方法 |
| /cost | 显示 token 消耗和估计会话成本 |
| /clear | 重置对话并在同一目录中重新开始 |
| /compact [focus] | 汇总上下文以减少 token。可选:指定要保留的内容 |
| /exit | 结束会话 |
上下文与内存
| 命令 | 用途 |
|---|---|
| /init | 使用文档模板创建新的 CLAUDE.md 文件 |
| /memory | 查看或编辑项目的 CLAUDE.md 文件 |
| /context | 显示当前上下文窗口使用情况和剩余容量 |
| /resume [id] | 继续之前的会话。省略 ID 查看最近的会话 |
配置
| 命令 | 用途 |
|---|---|
| /config | 打开 Claude Code 偏好设置界面 |
| /permissions | 管理工具权限和确认提示 |
| /model | 为当前会话切换 Claude 模型(Sonnet、Opus、Haiku) |
| /login | 使用你的 Claude 账户认证 |
| /logout | 从当前会话登出 |
集成
| 命令 | 用途 |
|---|---|
| /mcp | 配置 Model Context Protocol 服务器 |
| /agents | 创建和管理带有专门提示词的 subagent |
| /b ashes | 列出和管理后台 shell 进程 |
工具
| 命令 | 用途 |
|---|---|
| /doctor | 对你的安装运行诊断健康检查 |
| /terminal-setup | 安装 Shift+Enter 快捷键用于多行输入(macOS) |
| /vim | 切换 Vim 编辑模式 |
| /release-notes | 查看最近的 Claude Code 更新 |
| /bug | 报告 bug(将对话发送给 Anthropic) |
带选项启动 Claude Code
从终端启动 Claude Code 时的选项:claude [flags] [query]
权限控制
| 标志 | 示例 | 用途 |
|---|---|---|
| --permission-mode | claude --permission-mode plan | 设置初始模式。选项:default、plan、acceptEdits、bypassPermissions |
| --dangerously-skip-permissions | (谨慎使用) | 绕过所有权限提示。仅限受信任环境 |
| --allowedTools | claude --allowedTools "Bash(git:*)" | 指定不需要提示的工具 |
| --disallowedTools | claude --disallowedTools "Bash(rm:*)" | 明确拒绝特定工具 |
会话选项
| 标志 | 示例 | 用途 |
|---|---|---|
| --continue 或 -c | claude -c | 继续最近的会话 |
| --resume | claude --resume abc123 | 按 ID 恢复特定会话 |
| --add-dir | claude --add-dir /path/to/repo | 将目录添加到允许路径 |
| --model | claude --model opus | 选择 Claude 模型(别名:sonnet、opus) |
| --print 或 -p | claude -p "query" | 运行一次查询并退出(用于脚本) |
系统提示
| 标志 | 示例 | 用途 |
|---|---|---|
| --append-system-prompt | claude --append-system-prompt "Focus on..." | 将指令添加到默认提示(推荐) |
| --system-prompt | claude --system-prompt "You are..." | 替换整个系统提示 |
| --system-prompt-file | claude --system-prompt-file ./prompt.txt | 从文件加载系统提示 |
帮助
| 标志 | 用途 |
|---|---|
| --help | 显示 CLI 使用信息 |
| --version | 显示已安装的版本号 |
控制 Claude Code 的自主性
通过 --permission-mode 标志设置,或在会话中使用 Shift+Tab 循环切换。
| 模式 | 行为 | PM 用例 |
|---|---|---|
| plan | 只读。不修改文件,不执行命令。启用扩展思考。 | 代码库调查、bug 分类、架构审查 |
| default | 所有修改和命令前都提示。最大控制。 | 学习 Claude Code、敏感工作 |
| acceptEdits | 自动批准文件编辑。仍然对 shell 命令提示。 | 生成文档、创建 skill、更新 CLAUDE.md |
| bypassPermissions | 跳过所有提示。需要 --dangerously-skip-permissions 标志。 | PM 工作很少需要 |
建议:在 ~/.claude/settings.json 中将 plan 设置为你的默认模式。当需要文件输出时切换到 acceptEdits。
更快的导航和控制
模式控制
| 快捷键 | 功能 |
|---|---|
| Shift+Tab | 循环切换权限模式:default → acceptEdits → plan |
| Tab | 切换扩展思考(逐步推理) |
| Esc Esc | 回退:撤销最近的更改或对话轮次 |
输入与导航
| 快捷键 | 功能 |
|---|---|
| Shift+Enter | 换行而不发送(macOS 需要 /terminal-setup) |
| Ctrl+C | 中断当前操作 |
| Ctrl+D | 退出 CLI |
| Ctrl+L | 清屏 |
| Ctrl+O | 切换详细模式(显示扩展思考输出) |
特殊输入前缀
| 前缀 | 功能 | 示例 |
|---|---|---|
| # | 添加注释到 CLAUDE.md | # Auth uses JWT tokens |
| @ | 文件路径自动补全 | @src/components/ |
| / | 斜杠命令 | /cost |
设置文件位置
| 位置 | 范围 | 用途 |
|---|---|---|
| ~/.claude/settings.json | 所有项目 | 全局偏好、默认模式 |
| .claude/settings.json | 项目(共享) | 团队设置,提交到 git |
| .claude/settings.local.json | 项目(个人) | 本地覆盖,gitignored |
设置默认模式
创建或编辑 ~/.claude/settings.json:
{
"defaultMode": "plan"
}自定义斜杠命令
在 .claude/commands/(项目)或 ~/.claude/commands/(个人)中创建 Markdown 文件来添加自定义斜杠命令。
功能:
- $1、$2、$@ 用于位置参数
- !command 前缀用于嵌入 bash 输出
- 子目录创建命名空间命令(例如 pm/feedback.md 变为 /pm:feedback)
示例:.claude/commands/investigate.md
Investigate how $1 works in this codebase. Focus on:
- User-facing behavior
- Data flow
- Key decision points
Summarize in terms a product manager would use.用法:/investigate authentication
快速参考卡片
安全启动:claude --permission-mode plan
检查成本:/cost
减少上下文:/compact
查看可用内容:/help
循环切换模式:Shift+Tab
退出:/exit
命令和选项截至出版时是最新的。运行 /help 和 claude --help 查看你已安装版本的权威列表。
附录 B
附录 B:SKILL.md 模板
创建新 skill 时复制此模板。完整示例见第九章,设计模式见第八章。
最简模板
适用于工作流简单的 skill:
---
name: my-skill-name
description: What this skill does and when to use it. Include trigger words Claude should recognize.
---
# My Skill Name
## Purpose
One sentence explaining the goal.
## Inputs
- What files or information the user provides
## Process
1. Step one
2. Step two
3. Step three
## Output
What gets generated and where it goes.最简 skill 示例:
---
name: standup-notes
description: Generate standup notes from yesterday's git commits. Use when user mentions standup, daily update, or what I did yesterday.
---
# Standup Notes
## Purpose
Create formatted standup notes from recent commits.
## Inputs
- Git repository with commit history
## Process
1. Read commits from the past 24 hours
2. Group by type (feature, fix, refactor)
3. Write in first person, past tense
## Output
Print standup notes to terminal. Do not create a file.综合模板
适用于需要详细指令的复杂 skill:
---
name: my-skill-name
description: Detailed description of what this skill does. Mention specific trigger phrases: analysis, synthesis, report generation. Auto-invoke when user mentions [keyword1], [keyword2], or [keyword3].
---
# My Skill Name
## Purpose
Explain the goal and value of this skill in 2-3 sentences. What problem does it solve? What outcome does it produce?
## Expected Inputs
- **Required:** File types, formats, or information the user must provide
- **Optional:** Additional context that improves results
- Supports: List compatible formats (CSV, JSON, plain text)
## Process
Follow these steps in order:
1. **Read and validate inputs**
- Check that required files exist
- Identify relevant columns or fields
2. **Analyze content**
- Describe the analysis methodology
- Include specific criteria or thresholds
3. **Generate output**
- Specify the output format
- Note any formatting requirements
4. **Quality check**
- Verify output meets criteria before finishing
## Output Format
Generate file: `path/to/output-[date].md`
Structure:
## Section One
[What goes here]
## Section Two
[What goes here]
## Quality Criteria
- Criterion one (specific and measurable)
- Criterion two
- Criterion three
## Edge Cases
- **Small datasets:** How to handle insufficient data
- **Malformed input:** What to do when input is incomplete
- **Ambiguous requests:** How to interpret unclear instructions
## Usage Examples
**Standard:** "Run [skill name] on [file]"
**Detailed:** "Run [skill name] on [file] with comprehensive analysis"
**Quick:** "Run [skill name] on [file], just the summary"字段参考
| 字段 | 必需 | 用途 |
|---|---|---|
| name | 是 | 唯一标识符,小写加连字符 |
| description | 是 | 发现文本——Claude 用它决定何时激活。包含触发词。 |
各节指南
Purpose:最多一段。以用户得到什么来开头,而不是 skill 内部做什么。
Expected Inputs:对格式要具体。"CSV 文件"过于模糊;"CSV 文件,反馈文本在一列中"告诉 Claude 要找什么。
Process:对步骤编号。使用祈使语气("读取文件"而不是"文件应该被读取")。包含决策点("如果 X,则 Y")。
Output Format:展示确切的结构。使用代码块作为模板。指定文件路径模式。
Quality Criteria:使这些可测试。"质量好"是没用的;"引用逐字准确,而非改写"是可操作的。
Edge Cases:记录三种最常见的失败场景。这能节省日后调试时间。
文件结构
.claude/skills/
└── my-skill-name/
├── SKILL.md # 必需
├── scripts/ # 可选的辅助脚本
│ └── helper.py
└── resources/ # 可选的模板、评分标准
└── template.md存放位置选项:
- .claude/skills/ — 项目特定,通过 git 与团队共享
- ~/.claude/skills/ — 个人,在所有项目中可用
常见错误
模糊的描述:"帮助处理反馈"不会触发。应使用:"将客户反馈综合为主题报告。当用户提到反馈分析、NPS 综合或支持工单主题时自动调用。"
缺少触发词:Claude 将你的请求与 skill 描述匹配。如果你的描述不包含用户实际使用的词,skill 就不会激活。
指令过长:将 SKILL.md 保持在 5,000 字以内。将参考资料移到 resources/ 中的独立文件。
没有质量标准:没有明确的标准,输出质量会变化。定义"做得好"是什么样子。
创建 skill 后,重启 Claude Code 来加载它。在提交前用真实数据测试。
附录 C
附录 C:适用于 PM 工作流的 CLAUDE.md 示例
为你的项目复制并改编此模板。每节的详细指导见第三章。
文件位置
Claude Code 从多个位置读取 CLAUDE.md 文件,按以下顺序加载:
| 位置 | 范围 | 用例 |
|---|---|---|
| ~/.claude/CLAUDE.md | 所有项目 | 跨仓库的个人偏好 |
| ./CLAUDE.md | 本项目 | 团队共享上下文(提交到 git) |
| ./CLAUDE.local.md | 本项目 | 个人覆盖(gitignored) |
| .claude/rules/*.md | 本项目 | 将大型配置拆分为聚焦的文件 |
所有级别都被加载和合并。项目级设置覆盖用户级设置的冲突项。
CLAUDE.md 示例
# Acme Dashboard - Product Context
## About This Product
Acme Dashboard is a B2B analytics platform for e-commerce teams. Users connect
their store data, view sales metrics, and create custom reports. Primary users
are e-commerce managers and marketing analysts at mid-market retailers.
## Product Terminology
- **Workspace**: A team's shared environment. Users can belong to multiple
workspaces. Not the same as "account" (billing entity).
- **Connector**: Integration with external data source (Shopify, Google
Analytics). Each workspace can have multiple connectors.
- **Widget**: A single chart or metric on a dashboard. Widgets pull from
one or more data sources.
- **Pipeline**: Data processing job that syncs connector data. Runs hourly
by default. Not related to sales pipelines.
- **Activation**: When a user completes onboarding and creates their first
dashboard. Different from account activation (email verification).
## Key User Journeys
### New User Onboarding
1. Sign up and email verification → `src/auth/`
2. Workspace creation → `src/services/workspace-service.js`
3. First connector setup → `src/connectors/`
4. Dashboard creation → `src/components/DashboardBuilder/`
### Report Generation
- Entry point: `src/components/ReportBuilder/`
- Data queries: `src/services/query-engine/`
- Export: `src/services/export-service.js`
- Scheduling: `src/services/scheduler/`
### Billing and Subscription
- Pricing logic: `src/services/billing/pricing.js`
- Stripe integration: `src/services/billing/stripe-client.js`
- Usage metering: `src/services/billing/usage-tracker.js`
## Business Rules
- Free tier: 1 workspace, 2 connectors, 30-day data retention
- Pro tier: 5 workspaces, unlimited connectors, 1-year retention
- Enterprise: Custom limits, SSO, dedicated support
- Connector sync failures retry 3x before alerting user
- Dashboard exports limited to 10,000 rows (prevent memory issues)
- Widget refresh rate minimum 15 minutes (API rate limiting)
## Team Conventions
- All user-facing strings use i18n system in `src/locales/`
- Pricing calculations happen server-side only (never in frontend)
- Jira ticket IDs in commit messages: "Add export feature (ACME-1234)"
- Feature flags managed in `src/config/features.js`
- Database migrations require data team approval
## Code Patterns
- API endpoints follow REST conventions in `src/api/routes/`
- Business logic lives in `src/services/`, not controllers
- React components use hooks pattern, no class components
- Tests colocated with source files: `Component.test.tsx`
## Common PM Questions
- "How does pricing work?" → `src/services/billing/pricing.js`
- "Where is email content?" → `src/templates/email/`
- "How do we track usage?" → `src/services/billing/usage-tracker.js`
- "What triggers notifications?" → `src/services/notifications/`
- "Where are feature flags?" → `src/config/features.js`
## External Resources
- Product strategy: [internal wiki link]
- Design system: [Figma link]
- API docs: [internal docs link]
- Analytics: [dashboard link]逐节指导
About This Product(2-3 句):它做什么?谁在使用它?这在任何调查之前为 Claude Code 提供定位。
Product Terminology(5-10 个术语):定义在你的领域中有特定含义或可能与其他常见术语混淆的词。防止误解。
Key User Journeys(3-5 个流程):将关键用户路径映射到代码位置。Claude Code 知道在哪里查找而无需探索。包含文件路径,而不仅仅是描述。
Business Rules(5-10 条规则):记录从代码中不明显的逻辑——限制、约束、定价层级、重试策略。帮助 Claude Code 正确解释行为。
Team Conventions(5-8 条规范):你的团队如何工作。防止建议违反实践。包含 commit 消息格式、代码组织规则、审批要求。
Code Patterns(3-5 个模式):高层架构指导。业务逻辑在哪里?代码库遵循什么模式?
Common PM Questions(5-10 个条目):常见调查的快速参考。通过直接指向相关文件来节省时间。
External Resources:Claude Code 不能跟踪的链接,但在会话中对你有用的提醒。
大小指南
- 大多数项目保持在 100 行以内
- 每节应可快速浏览,而非叙述性
- 使用列表项,而非段落
- 如果超过 150 行,拆分为 .claude/rules/ 目录
上面的示例大约 80 行,每次会话消耗大约 2,000 token——对于显著的上下文改善来说成本极低。
快速开始
在任何项目中运行 /init,基于代码库分析生成一个 starter CLAUDE.md。编辑生成的文件以添加产品上下文、术语和 PM 特定的节。
在会话期间使用 /memory 验证加载了什么。
在你的理解增长时更新你的 CLAUDE.md。当你在调查中学到有价值的东西时,添加进去。活文档胜过陈旧文档。
附录 D
附录 D:提示词模板
为常见的 PM 工作流复制并改编这些提示词。[方括号]中的占位符需要你提供输入。详细上下文和示例见相关章节。
调查提示词
在 plan 模式(--permission-mode plan)中使用这些进行安全探索。
架构与功能
架构概览
Explain this codebase's architecture to a product manager. Cover the main components, how data flows through the system, key abstractions, and where business logic lives. Skip implementation details—focus on concepts.功能实现
How does [feature name] work in this application? Specifically:
- What triggers it (user action, scheduled job, external event)?
- What data does it read and write?
- What external services does it call?
- What are the success and failure paths?关键文件
I need to understand the [feature] feature. What are the five most important files I should know about? For each file, explain what it owns and why it matters.数据与行为
数据访问
What user data does the [feature] feature access? Show me which database tables or API endpoints it reads from, what fields it uses, and whether it writes anything back.边缘情况调查
What happens when [condition] occurs during [process]? Walk me through the code path, error handling, and user-facing behavior.行为解释
Users report that [observed behavior]. Why does this happen? Is it intentional or a bug?Bug 调查
症状转译
A user reports: "[paste exact complaint]"
Translate this into technical terms. What components might be involved? What should I investigate first?代码区域识别
I'm investigating a user-reported issue: [one-sentence summary]
Which code areas should I examine? List relevant files, functions, and data flows.问题层级识别
A user experiences [symptom]. Help me determine if this is likely:
- Frontend (UI, client-side state, browser)
- Backend (API, server logic, processing)
- Data (database, cache, data integrity)
- Integration (third-party services, external APIs)
- Infrastructure (network, hosting, configuration)
Explain your reasoning.配置调查
What configuration controls [feature]? Show me feature flags, environment variables, and settings that affect its behavior.访问控制调查
How are permissions checked for [feature]? Show me where access is validated and what roles or conditions are required.生成提示词
在 acceptEdits 模式中使用这些进行文件创建。
需求与故事
用户故事生成
Generate user stories for the [feature name] feature in docs/user-stories/[feature-name].md.
For each story, include:
- User story in standard format (As a… I want… So that…)
- Acceptance criteria (Given/When/Then)
- Edge cases and error states
- Dependencies on other features
Reference the codebase for technical constraints.PRD 生成
Create a PRD for [feature name] in docs/prds/[feature-name].md.
Include: Problem statement, success metrics, user stories, scope (in/out), technical considerations, open questions.
Reference existing implementation patterns in this codebase.用户画像生成
Based on the research materials in [research folder], create persona documents in docs/personas/.
For each distinct user type, include: Name, role, goals, frustrations, key behaviors, quotes from research.文档
变更日志生成
Generate a changelog entry for version [X.Y.Z] by reviewing git commits since [last version tag].
Format for external users: focus on benefits, not implementation. Group by: New Features, Improvements, Bug Fixes.README 更新
Review and update README.md to reflect recent changes. Ensure the getting started instructions, feature list, and examples match current behavior.Bug 报告生成
Based on my investigation, generate a bug report including:
- Summary (one sentence)
- Steps to reproduce
- Expected vs. actual behavior
- Affected code areas (files, functions)
- Hypothesis on root cause
- Suggested investigation path for engineering分析提示词
使用这些进行综合和洞察生成。
反馈与研究
主题识别
Read all feedback in [feedback folder] and identify the top 10-15 themes that appear repeatedly.
For each theme: Name, description, frequency (how many mentions), representative quotes (3-5 verbatim examples).反馈分类
Classify feedback in [feedback folder] into these categories: [category 1], [category 2], [category 3], [Other].
Create a summary showing count per category, sentiment breakdown, and notable patterns.访谈综合
Read interview transcripts in [interview folder] and synthesize patterns across interviews.
Identify: Common pain points, unmet needs, workarounds users have created, emotional reactions, feature requests (explicit and implied).洞察到行动映射
Review the theme report in [report file] and map each major theme to potential product actions.
For each theme suggest: Quick wins, larger initiatives, and things to monitor but not act on yet.市场与竞争
竞争对手档案
Research [Competitor Name] using web search and create a profile in research/competitors/[competitor-name].md.
Include: Company overview, target market, core features, pricing model, positioning, strengths, weaknesses, recent news.竞争矩阵
Based on competitor profiles in research/competitors/, create a comparison matrix in research/competitors/competitive-matrix.md.
Compare: Target audience, pricing, key features, integrations, differentiators.定价分析
Research [Competitor Name]'s pricing and create a breakdown in research/pricing/[competitor-name]-pricing.md.
Include: Pricing model (per seat, usage, flat), tier structure, feature gates, published prices, discounting patterns if known.市场规模
Help me size the market for [product/category] using TAM/SAM/SOM. Create research/market-sizing/market-size.md.
For each level, document: Methodology, data sources, assumptions, calculation, confidence level.验证与审计
PRD 审计
Review [PRD file] for completeness. Check:
- Clear problem statement with evidence
- Measurable success metrics
- User stories with acceptance criteria
- Explicit scope boundaries
- Technical considerations addressed
- Dependencies identified
- Open questions listed
Flag gaps and suggest improvements.文档审计
Compare documentation in docs/ to current codebase. Identify:
- Outdated information
- Missing documentation for implemented features
- Incorrect examples or code snippets
- Broken internal references用户画像验证
Review personas in docs/personas/ against source research in [research folder].
For each persona, verify: Claims are supported by research, quotes are accurate, no invented details.快速定制指南
通过添加约束使提示词更具体:
- "Focus on the user-facing behavior, not internal implementation"
- "Keep the output under 500 words"
- "Format as a table for easy scanning"
- "Include file paths for all code references"
通过要求制品使提示词更彻底:
- "Save the analysis to [specific file path]"
- "Include a summary section at the top"
- "List your assumptions explicitly"
- "Rate your confidence in each finding"
为复杂工作流串联提示词:
- 运行调查提示词以收集上下文
- 使用 /compact 总结发现
- 在上下文建立后运行生成提示词