第7章
需求、用户画像与文档
7.1 从零散研究中创建用户画像
你的利益相关者在路线图规划前需要用户画像。你手头有零散的研究资料:上季度的客户访谈、显示行为模式的分析数据、揭示痛点的支持工单、以及包含买家关注点笔记的销售电话记录。构建用户画像意味着将这些信息综合成连贯的用户原型。传统做法是:阅读所有资料,手动识别模式,将用户画像写成放在Google Slides中的演示文稿,被参考一次后就被遗忘。
Claude Code将用户画像创建为存放在仓库中的可版本化产物。你向它提供研究数据,指定哪些特征能让画像对你的产品上下文有价值,然后得到与你工作流集成的结构化画像文档。当工程师问"这个功能是为谁做的?"时,你可以指向仓库中的docs/personas/enterprise-admin.md。当画像基于新研究发生变化时,你更新文件并提交变更。画像不是一张静态幻灯片,而是活文档。
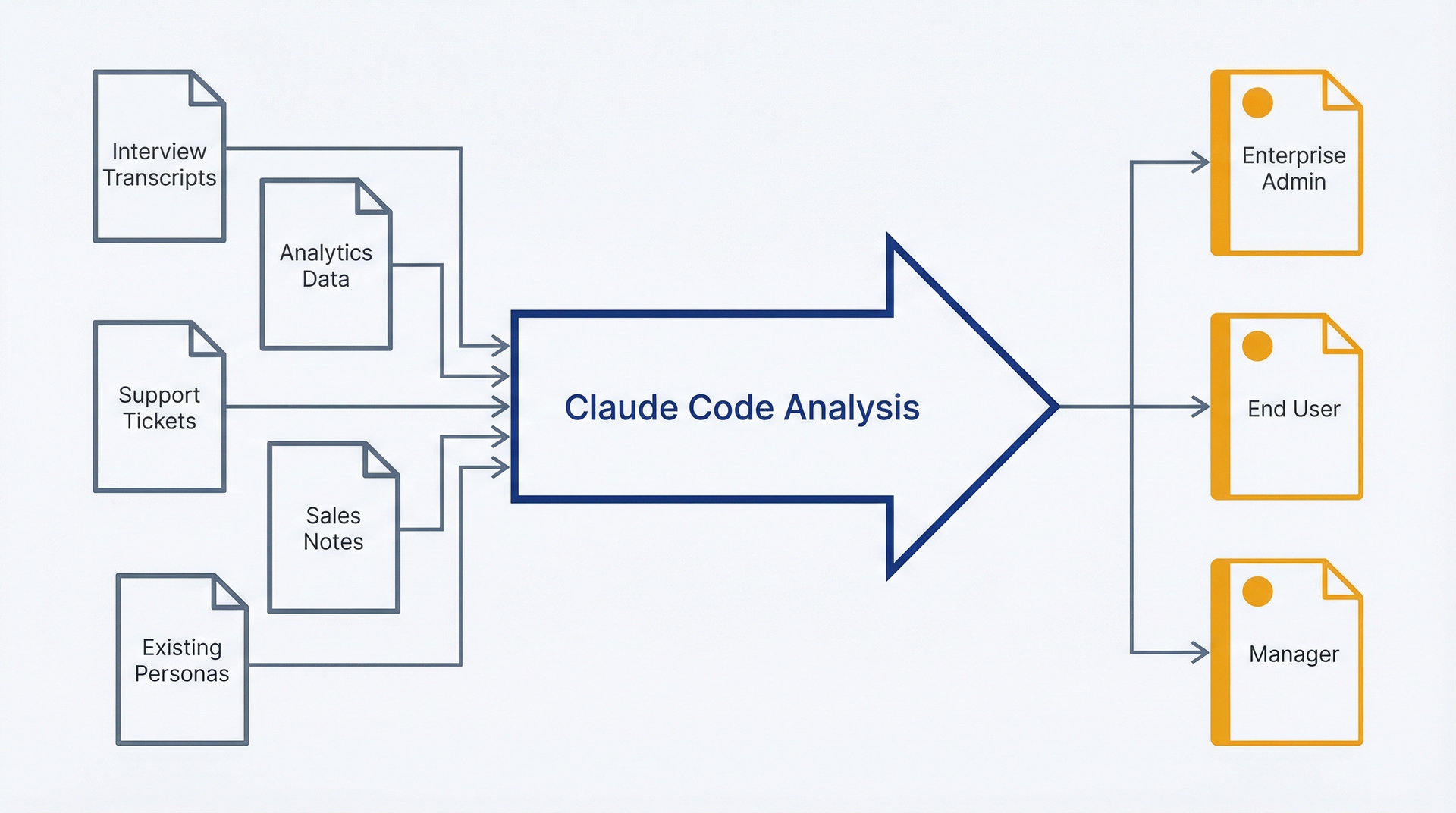
图7.1:用户画像生成工作流——使用此流程将零散的研究转化为结构化、可版本化的画像文档。研究来源(访谈、分析数据、支持数据)通过Claude Code分析,生成存放在仓库中、随产品演进的画像文件。
输入:研究数据、分析数据、现有知识。在生成画像之前,收集你对用户的了解。你不需要全面的研究,只需足够的信号来创建有用的用户原型即可。
需要收集的研究来源:- 访谈记录:用户调研会话、客户访谈、销售探索通话 - 分析数据:用户行为模式、功能采用率、工作流序列 - 支持数据:常见问题、痛点、具有不同问题的用户群体 - 销售情报:买家画像、决策标准、异议 - 现有知识:你和你的团队已经了解的用户类型
像准备反馈综合(第6章)一样准备这些数据。导出为文件,移除个人身份信息,组织到一个目录中:
mkdir -p research/persona-development
放置源材料:
research/persona-development/├── interviews-enterprise-users.txt├── analytics-summary.md├── support-ticket-themes.md├── sales-notes.txt└── existing-personas-critique.md
如果你有旧的画像,将其与关于哪些内容过时或不准确的笔记一起包含进来。Claude Code可以以此为起点进行改进。
提示模板:画像生成。启动Claude Code:
claude --permission-mode plan
先从分析开始,然后在具有写入权限的第二个会话中生成画像。
提示:画像分析
查看research/persona-development/中的研究材料,并基于以下维度识别不同的用户类型:
- 目标和动机:他们试图完成什么?
- 行为:他们如何使用产品或类似工具?
- 痛点:什么让他们感到沮丧或阻碍了他们的工作?
- 背景:公司规模、角色、技术技能、决策权限
从这些数据中能得出多少个不同的画像?对于每个潜在的画像:
- 是什么定义了这个用户类型?(2-3个关键特征)
- 这个细分群体有多大?(用户百分比或粗略估计)
- 有什么证据支持将其作为一个独立画像?(引用来源)
推荐3-5个涵盖我们主要用户类型、且不过度细分的画像。
Claude Code读取你的研究材料,识别模式,并提出画像。你会得到类似这样的结果:"三个不同的画像浮现出来:(1) Enterprise Admin,关注安全性和可扩展性的技术采购者,占用户的15%,但推动采购决策。证据:12次销售电话中有8次聚焦企业需求。(2) End User,关注易用性和日常工作流效率的个人贡献者,占用户的70%。证据:支持工单和访谈主要来自该群体。(3) Manager,管理团队使用情况,关注报告和可见性,占用户的15%。证据:功能请求和分析数据显示仪表盘/报告功能有不同的使用模式。"
审查提议的画像。它们是否与你的直觉相符?是否缺少某些群体?是否有应该合并的重叠?如果需要,通过后续提示来优化分析。
输出格式:结构化画像文档。一旦验证了画像集合,生成详细的画像文档:
退出plan模式,并以写入权限启动:
/exitclaude
提示:画像文档生成
基于画像分析,在docs/personas/中创建详细的画像文档。为每个画像生成一个markdown文件:[persona-name].md。
每个画像文档的结构如下:
- 概述
- 姓名和角色(虚构但有代表性)
- 一句话总结:他们是谁,关心什么
- 照片占位符:[描述,不需要实际图片]
- 人口统计信息
- 角色/职位
- 公司规模
- 行业(如相关)
- 技术技能水平
- 决策权限(采购者、影响者、最终用户)
- 目标和动机
- 主要目标(他们试图达成什么)
- 成功标准(他们如何衡量成功)
- 动机(驱动他们行为的因素)
- 痛点和挫折
- 当前挑战(在使用我们产品之前)
- 对现有解决方案的不满
- 工作流阻碍
- 行为和偏好
- 他们如何工作(工作流、工具、流程)
- 产品使用模式
- 沟通偏好
- 决策方式
- 对我们产品的需求
- 必备功能(决定性因素)
- 重要功能(高价值)
- 锦上添花功能(低优先级)
- 异议和顾虑
- 什么让他们对采用犹豫不决?
- 他们在评估过程中会问什么问题?
- 什么可能导致他们流失?
- 支持证据
- 研究中的关键引用(2-3条代表性引用)
- 验证该画像的数据点
- 来源参考
每个画像文档控制在2页以内。聚焦于可操作的洞察,而非人口统计细节。
Claude Code在docs/personas/中生成画像文件。每个画像成为一个参考文档,你可以从PRD、路线图讨论和功能规划中链接到它。
示例输出结构:
Enterprise Admin Persona: Sarah ChenSummary: IT administrator or security lead who evaluates and purchases tools for their organization. Cares about security, compliance, and scalability more than ease of use.## Demographics- Role: IT Administrator, Security Lead, or VP of Engineering- Company size: 500-5000 employees- Technical skill: High, comfortable with APIs, SSO, infrastructure- Decision authority: Primary buyer or strong influencer## Goals and Motivations- Ensure tools meet security and compliance requirements- Minimize risk of data breaches or regulatory violations- Evaluate total cost of ownership including support and maintenance- Standardize tooling across organization to reduce complexity## Pain Points and Frustrations- Tools that lack enterprise features (SSO, audit logs, role-based access)- Poor security documentation that delays evaluation- Hidden costs that appear after purchase (seat limits, API restrictions)- Vendor lock-in concerns with proprietary data formats## Behaviors and Preferences- Runs proof-of-concept trials before purchasing- Requests security audits, SOC 2 reports, penetration test results- Prefers self-service implementation over hand-holding- Values responsive support for technical issues## Needs from Our ProductMust-have:- SSO/SAML integration- Audit logging and activity monitoring- Role-based access control with granular permissions- SOC 2 Type II complianceImportant:- API access for integrations and automation- Data export capabilities (avoid vendor lock-in)- High availability SLAs- Priority supportNice-to-have:- Advanced security features (IP whitelisting, session management)- Dedicated account manager- Custom training for team## Objections and Concerns- "How do you handle data encryption at rest and in transit?"- "What happens if we need to migrate away?"- "Can we run this on-premise or in our VPC?"- "What's your security incident response process?"## Supporting EvidenceQuotes:- "We need full audit logs. If we can't prove who accessed what data and when, it's a non-starter." (Interview, Enterprise_Customer_12)- "SSO is table stakes. We're not managing another set of credentials." (Sales call, Q4 2025)Data:- 85% of enterprise deals stall on security review (sales pipeline data)- Enterprise admin personas represent 15% of users but 60% of revenue- Security-related feature requests cluster in this segment (support ticket analysis)
基于数据验证画像。不要因为AI生成了画像就盲目信任。根据你的认知进行验证:
提示:画像验证
审查生成的画像,并根据来源研究进行验证:
- 特征是否有实际数据支持,还是只是假设?
- 痛点是否与用户在访谈和工单中实际表达的一致?
- 群体规模在我们的分析数据中是否现实?
- 画像与实际用户行为之间是否存在矛盾?
标记出任何看起来是推测性的或缺乏充分支持的要素。
这能捕捉到Claude Code用听起来合理的细节填补空白、但这些细节并不基于你数据的情况。如果Enterprise Admin画像列出了"偏好电子邮件而非Slack",但你没有关于沟通偏好的证据,就删除它或将其标记为需要验证的假设。
将画像提交到你的仓库:
git add docs/personas/git commit -m "Add user personas based on Q4 2025 research"
画像开发的时间和成本。分析研究并识别画像类型:15-20分钟,30,000-50,000 tokens,$0.15-0.25。生成3-4个详细画像文档:20-30分钟,40,000-70,000 tokens,$0.20-0.35。总计:35-50分钟,$0.35-0.60。相比数天的手动综合和格式编排工作。
画像生成失败的情况。如果你的研究数据薄弱(访谈少、数据有限、信号弱),Claude Code会产生可以描述任何产品用户的通用画像。"Sarah希望工具易于使用并能提高生产力"——这不是可操作的洞察。这是数据问题,而非工具问题。在生成画像之前收集更多研究资料。
如果你的用户群极其多样化,没有清晰的群体划分,每个用户都想要不同的东西,那么画像就没有帮助。这表明可能存在产品-市场匹配问题,或者你正在采用试图服务所有人的功能工厂方法。按用例或垂直领域细分,而不是按用户类型。
画像更新频率。稳定市场每年一次。快速变化的产品每季度一次。当进入新市场领域或研究发现用户需求发生显著变化时更新。将画像视为活文档;版本控制展示了其随时间演进的过程。
7.2 从功能概念生成全面的用户故事
你有一个功能概念。利益相关者一致认为值得开发。现在你需要为工程团队编写用户故事:关于用户需要什么、为什么需要、以及如何判断是否成功的结构化描述。传统做法是:手动编写故事,安排一次细化会议,花一小时与工程师澄清模糊点,在实现过程中发现遗漏的边界情况。
Claude Code从功能概念生成全面的用户故事。你提供关于功能和目标用户的背景信息。Claude Code将其扩展为包含验收标准、边界情况和技术注意事项的故事——这些基于对你代码库的理解。故事并非最终版本(你仍需要与工程师一起细化),但它们是完成了80%的成果,而非从零开始。
从功能概念到用户故事。从你已知的信息开始:
- 你在构建什么功能?
- 它的目标用户是谁?(如果有画像则引用)
- 它解决什么问题?
- 它需要支持哪些关键工作流?
首先以plan模式启动Claude Code,探索代码库获取上下文:
claude --permission-mode plan
提示:功能上下文分析
我正在规划一个功能:[功能的简要描述]
在编写用户故事之前,帮助我了解技术上下文:
- 这个功能与哪些现有功能或代码区域相关?
- 这个功能需要访问什么数据?
- 我应该了解什么技术约束?(认证、权限、集成、性能考虑)
- 类似功能存在哪些边界情况?
这些上下文将为用户故事的创建提供参考。
例如,规划一个"批量用户导入"功能:
我正在规划一个批量用户导入功能,让管理员可以上传CSV文件来自动创建用户账号。
在编写用户故事之前,帮助我了解技术上下文:
- 目前用户创建是如何工作的?
- 创建单个用户时有哪些验证?
- 账号创建是否存在速率限制或约束?
- 如何处理重复的电子邮件地址?
Claude Code调查代码库并回复:"用户创建在src/services/user-service.js:78-156中实现。当前验证包括:邮箱格式、数据库中邮箱唯一性、密码强度要求、角色必须有效。重复邮箱会被拒绝并报错。目前用户创建没有速率限制,这对批量导入来说可能是个问题。类似的批量操作(批量项目创建)位于src/services/batch-operations.js,具备进度跟踪和错误报告功能。"
现在你知道了存在哪些约束、应该遵循什么模式、以及哪些边界情况很重要。
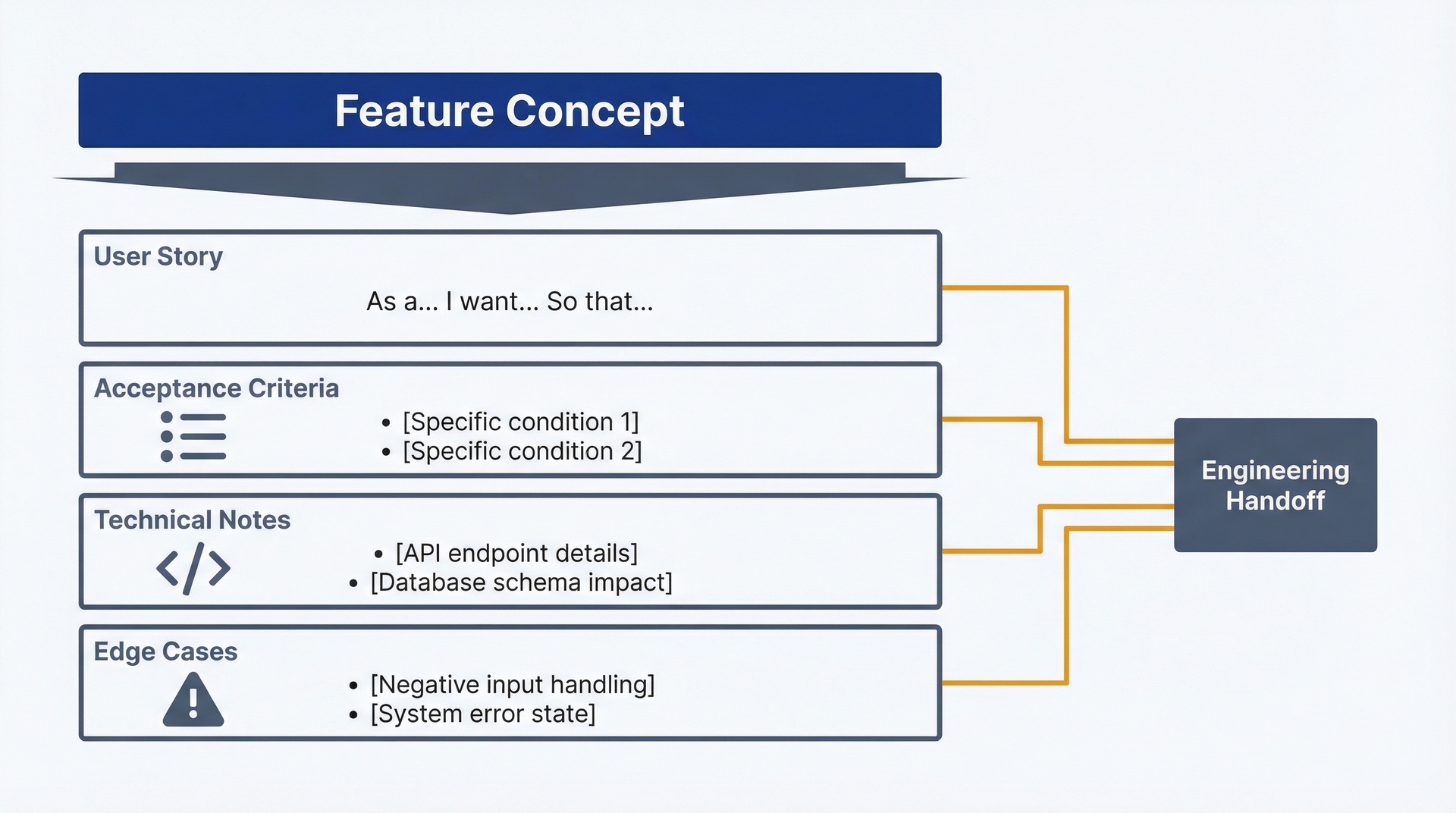
图7.2:用户故事剖析——使用此图理解功能概念如何扩展为全面的用户故事。展示了结构:用户故事格式(作为/我想要/以便于)、验收标准(可测试的需求)、技术说明(代码库引用、应遵循的模式)和边界情况(失败模式、边界条件)。
提示模板:用户故事展开。退出plan模式并以写入权限启动:
/exitclaude
提示:用户故事生成
为[功能名称]功能在docs/user-stories/[feature-name].md中生成用户故事。
功能描述:[2-3句话描述该功能]
目标画像:[画像名称或描述,例如"Enterprise Admin"或链接到docs/personas/enterprise-admin.md]
需要支持的核心工作流:1. [主要工作流] 2. [次要工作流] 3. [错误/边界情况工作流]
技术上下文:[来自你探索的结果摘要:现有模式、约束、相关功能]
按以下格式生成用户故事:
User Story: As a [persona], I want to [action], So that [outcome/benefit].
Acceptance Criteria: - [Specific, testable criterion 1] - [Specific, testable criterion 2] - [Edge case or error handling criterion]
Technical Notes: - [Implementation considerations from codebase context] - [Related files or patterns to follow] - [Constraints or dependencies]
Edge Cases: - [Scenario that could go wrong] - [Boundary condition] - [Error state]
创建5-8个涵盖核心功能、变体和边界情况的故事。按用户价值排序优先级。
Claude Code生成包含用户故事、验收标准和技术上下文的结构化文档。
批量用户导入的示例输出:
User Stories: Bulk User Import## Story 1: Upload CSV to Create Multiple UsersAs an Enterprise Admin,I want to upload a CSV file with user information,So that I can onboard multiple team members at once instead of creating accounts individually.Acceptance Criteria:- Admin can upload CSV file via file picker in admin dashboard- CSV format is documented with required columns: email, name, role- System validates CSV format before processing (rejects invalid files with clear error)- Success message shows number of users to be created before confirmation- Admin can review first 5 rows as preview before confirmingTechnical Notes:- Follow pattern from src/services/batch-operations.js for batch processing- Reuse validation logic from src/services/user-service.js:78-156- Consider file size limits (current upload limit is 10MB in config)- Store uploaded file temporarily for processing, clean up afterEdge Cases:- If CSV file exceeds size limit, reject with error message- If CSV has malformed rows, report which rows failed validation- If CSV contains 1000+ rows, consider async processing to avoid timeout## Story 2: Validate User Data Before ImportAs an Enterprise Admin,I want to see validation errors before users are created,So that I can fix issues in my CSV rather than partially importing bad data.Acceptance Criteria:- System validates all rows before creating any users- Validation checks: email format, unique email, valid role, required fields present- Validation errors list row numbers and specific issues- Admin can download error report CSV showing failed rows- No users are created if any validation fails (all-or-nothing)Technical Notes:- Extend existing validation from src/services/user-service.js- Check for duplicate emails both against database AND within the CSV- Role validation should match allowed roles from src/models/user.js:12-16Edge Cases:- If duplicate email exists in database, report as validation error- If multiple rows have same email in CSV, report as validation error- If role name has typo, suggest closest valid role if possible- If required field is missing, specify which column and row## Story 3: Track Import Progress and StatusAs an Enterprise Admin,I want to see progress while users are being created,So that I know the import is working and don't navigate away prematurely.Acceptance Criteria:- Progress indicator shows number of users created vs. total- Process doesn't block other admin dashboard usage- Admin can navigate away and return; progress persists- Completion notification appears when import finishes- Summary shows success count and any errorsTechnical Notes:- Use async batch processing pattern from src/services/batch-operations.js- Store import job status in database with progress tracking- Consider websocket for real-time progress updates or polling approach- Clean up completed jobs after 24 hoursEdge Cases:- If user navigates away mid-import, import continues in background- If import fails partway through, show partial success state and report which users were created- If database connection lost during import, retry failed users or fail entire batch?## Story 4: Handle Import Failures GracefullyAs an Enterprise Admin,I want to understand what went wrong if import fails,So that I can correct the issue and retry.Acceptance Criteria:- Error messages specify root cause (database error, validation, timeout)- Partial failures show which users were created successfully- Admin can download failed rows as CSV to fix and re-import- Failed import doesn't leave system in inconsistent state- Retry mechanism available for failed importsTechnical Notes:- Wrap user creation in database transaction if possible for atomicity- Log detailed errors to logs/import-errors.log for debugging- Reference existing error handling in src/services/user-service.js:142-156Edge Cases:- If database transaction too large, split into smaller batches- If rate limiting triggered by rapid user creation, implement throttling- If duplicate users created from retry after partial success, add idempotency check## Story 5: Send Welcome Emails to Imported UsersAs an imported user,I want to receive a welcome email with account setup instructions,So that I know my account was created and can log in.Acceptance Criteria:- Welcome email sent to each successfully created user- Email includes temporary password or password reset link- Email sending happens after all users created (don't spam if import fails)- Failed email sends are logged but don't fail the import- Admin can optionally suppress welcome emails for importTechnical Notes:- Use existing email service from src/services/email-notifications.js- Consider queue for sending emails to avoid blocking import completion- Follow email template pattern from src/templates/email/welcome.htmlEdge Cases:- If email service down, queue emails for retry; don't fail import- If some emails bounce, log bounces so admin can resend manually- If 500+ users imported, batch email sending to avoid rate limits[Additional stories for role assignment variations, audit logging, CSV template download...]
验收标准生成。验收标准将用户故事转化为可测试的需求。好的标准是具体、可衡量和可测试的。差的标准是模糊的:"用户可以轻松导入账号。"好的标准是:"管理员可以通过管理后台的文件选择器上传CSV文件"以及"确认前显示将要创建的用户数量的成功消息。"
Claude Code基于功能描述和代码库模式生成验收标准。审查并优化:消除模糊点,补充遗漏的情况,确保可测试性。
边界情况识别。Claude Code生成的用户故事的价值在于发现你可能遗漏的边界情况。它了解你的代码库约束(文件上传限制、验证模式、错误处理方法),并根据可能失败的情况提出边界情况:
- 如果文件太大怎么办?
- 如果存在重复邮箱怎么办?
- 如果导入过程中数据库连接失败怎么办?
- 如果邮件发送失败怎么办?
审查这些边界情况。有些可能过于谨慎。有些可能揭示你之前未考虑到的实际风险。用你的判断力来确定哪些边界情况需要在初始实现中处理,哪些留待未来迭代。
引用代码库获取技术约束。技术说明部分将故事与实现联系起来。"遵循batch-operations.js中的模式"告诉工程师去哪里找现有解决方案。"重用user-service.js中的验证逻辑"防止逻辑重复。"当前上传限制是10MB"设定了现实的预期。
这架起了产品与工程的桥梁。故事不是抽象的需求,而是基于你的系统实际运作方式而制定的。
提交用户故事:
git add docs/user-stories/git commit -m "Add user stories for bulk user import feature"
时间和成本。探索代码库获取技术上下文:10-15分钟,20,000-40,000 tokens,$0.10-0.20。生成全面的用户故事文档(5-8个故事):15-25分钟,30,000-60,000 tokens,$0.15-0.30。总计:25-40分钟,$0.25-0.50。
与工程团队进行细化。生成的故事是起点,不是最终规格。与工程团队一起审查:
- 技术说明是否准确?
- 边界情况是现实的还是过度设计的?
- 验收标准是否可测试?
- 缺少什么?
这种细化需要30-60分钟,但是从一个扎实的草稿开始,而不是从空白页开始。工程师花时间改进故事,而不是从零开始编写。
7.3 编写保持更新的PRD
产品需求文档处于两难境地:太重要而不能跳过,太繁琐而难以维护。你在Google Docs中编写PRD,分享以获取反馈,最终定稿,然后在实现过程中需求发生变化时从不更新。工程师构建了某些东西,PRD就过时了,未来的读者不知道是文档还是代码代表了真相。
解决方案不是更好的纪律,而是更好的存放位置。PRD应该作为markdown文件存放在你的仓库中,像代码一样进行版本控制。Claude Code帮助生成PRD各部分,保持与现有文档的一致性,并使需求与实现保持同步。
PRD作为仓库中的活产物。创建一个docs结构:
mkdir -p docs/prds
PRD变为markdown文件:docs/prds/bulk-user-import.md、docs/prds/api-rate-limiting.md、docs/prds/sso-integration.md。当需求变更时,你更新文件并提交。Git跟踪其演进过程。工程师直接引用该文件,没有会失效或需要权限申请的Google Doc链接。
提示模板:PRD各部分生成。PRD有标准的各部分。Claude Code基于你的研究、用户故事和代码库上下文来生成它们。
启动Claude Code:
claude
提示:PRD生成
为[功能名称]在docs/prds/[feature-name].md中创建一份PRD。
上下文:- 功能描述:[2-3句话] - 目标用户:[画像或用户类型] - 用户故事:参见docs/user-stories/[feature-name].md(如存在) - 相关研究:[如适用,链接到研究文档]
生成包含以下各部分的PRD:
- 概述 - 一段话总结:这个功能是什么,我们为什么要构建它? - 成功指标:我们如何衡量成功?
- 用户画像和用例 - 为谁而做?(如果有画像文档则引用) - 主要用例(3-5个场景)
- 需求
功能需求:- 功能必须做什么(按优先级排序:必备、应该具备、锦上添花)
非功能需求:- 性能、安全性、可扩展性、可访问性方面的考虑
- 用户体验 - 关键用户工作流(分步骤) - UI/UX考虑(界面、流程、交互)
- 技术方案 - 高层次技术设计 - 与现有代码的集成点(引用具体文件/区域) - 数据模型变更(如适用) - 第三方依赖
- 不在范围内 - 我们明确不做的事情(防止范围蔓延)
- 待解决问题 - 尚未解决的决策 - 需要进一步研究的领域
- 成功标准 - 发布标准:什么时候可以上线? - 成功指标:发布后什么样才算好?
- 时间线和里程碑(PM填写的占位符)
- 附录 - 链接到用户故事、研究、设计、相关文档
对于技术方案部分,分析代码库以识别:
- 我们应该遵循的现有模式
- 需要变更的文件或模块
- 潜在的技术风险或复杂性
PRD控制在6页以内。聚焦于清晰度和决策支持,而非详尽的细节。
Claude Code生成一份结构化的PRD。技术方案部分受益于代码库上下文:它引用实际文件、现有模式和实现约束,而非泛泛而谈的架构描述。
批量用户导入的PRD节选示例:
PRD: Bulk User Import## OverviewEnable enterprise administrators to create multiple user accounts simultaneously by uploading a CSV file, reducing onboarding time for large teams from hours to minutes.Success metrics:- 50% of enterprise customers use bulk import within first month of availability- Average time to onboard 50+ users decreases from 2 hours to under 10 minutes- Import success rate >95% (fewer than 5% of imports fail due to validation or errors)## User Personas and Use CasesPrimary persona: Enterprise Admin (see docs/personas/enterprise-admin.md)Use cases:1. New customer onboarding, provisioning accounts for entire team at once2. Seasonal hiring, adding interns or contractors in batches3. Department expansion, creating accounts for newly acquired team members4. Migration from competitor, importing existing user lists## Requirements### Functional RequirementsMust-have:- Upload CSV file with user details (email, name, role)- Validate CSV format and data before creating users- Show validation errors with specific row numbers and issues- Create all users atomically (all succeed or all fail)- Send welcome emails to imported users- Display import progress and completion status- Download error report for failed importsShould-have:- CSV template download with example data- Preview first 5 rows before confirming import- Audit log of import activity (who imported, when, how many users)- Option to suppress welcome emailsNice-to-have:- Support additional user fields (phone, department, manager)- Schedule imports for future date- Import existing users to update roles or details### Non-Functional Requirements- Performance: Handle CSV files up to 1,000 users without timeout (< 2 minutes processing)- Security: Validate admin permissions before allowing import, log all import activity- Reliability: Transaction-based import to prevent partial failures- Usability: Clear error messages that specify how to fix issues## User ExperiencePrimary workflow:1. Admin navigates to Users > Import Users2. Downloads CSV template (optional) to see required format3. Prepares CSV file with user data4. Clicks "Upload CSV" and selects file5. System validates file and shows preview of first 5 users6. Admin reviews and confirms import7. Progress indicator shows creation status8. Completion message displays results (success count, errors)9. Admin downloads error report if any validations failed10. Admin can fix errors in CSV and retryError state workflow:1. Admin uploads CSV with validation errors2. System displays error count and specific issues3. Admin downloads error report showing failed rows4. Admin fixes CSV and re-uploads5. System validates again until successful## Technical ApproachArchitecture:- Frontend: Add import UI to admin dashboard (src/client/components/Admin/UserImport.tsx)- Backend: Create import API endpoint (src/server/routes/users.js)- Service layer: Implement batch processing (src/services/user-import-service.js)- Follow existing batch operation pattern from src/services/batch-operations.jsKey technical decisions:1. CSV parsing: Use csv-parser library (already in dependencies)2. Validation: Extend existing user validation from src/services/user-service.js:78-1563. Batch processing: Process in batches of 50 users to avoid database connection limits4. Progress tracking: Store job status in user_import_jobs table, poll for progress5. Email sending: Queue emails using existing src/services/email-queue.js to avoid rate limitsIntegration points:- src/services/user-service.js - Reuse createUser logic- src/services/email-notifications.js - Send welcome emails- src/models/user.js - User model and validation- src/middleware/auth.js - Verify admin permissionsData model changes:- New table: user_import_jobs (id, admin_id, status, total_count, success_count, error_report, created_at)- Columns: id, admin_user_id, filename, status (pending/processing/completed/failed), total_rows, successful_rows, error_details (JSON), created_at, updated_atTechnical risks:- Database transaction size limit for 1,000 users: mitigate with batching- Email rate limiting: mitigate with queue and throttling- Large CSV file upload timeout: set appropriate limits and show progress## Out of Scope- Importing into multiple workspaces simultaneously (single workspace per import)- Updating existing user details via CSV (create-only for v1)- Importing group/team assignments (future enhancement)- Scheduled/recurring imports- Integration with HRIS systems for automated sync## Open Questions- Should partial success be allowed (some users created, some failed) or all-or-nothing? Decision needed from engineering re: transaction feasibility- What file size limit is reasonable? Current upload limit is 10MB; need to test how many users that represents- Should we support Excel files (.xlsx) or CSV only? CSV is simpler, covers 95% of use cases## Success CriteriaLaunch criteria:- Can successfully import 500 users in under 2 minutes- Validation catches all invalid data before creating users- Error reporting clearly identifies issues- Documentation includes CSV template and format requirements- Tested with real customer data (anonymized)Post-launch success:- 50% of enterprise customers adopt within 30 days- Support tickets about user creation decrease by 30%- Average onboarding time for 50+ user teams under 10 minutes## Timeline and Milestones[PM fills in sprint allocation, dependencies, launch date]## Appendix- User stories: docs/user-stories/bulk-user-import.md- Related research: research/feedback/enterprise-feature-requests.md- Competitive analysis: research/competitors/competitor-a-profile.md (has bulk import feature)- Design mocks: [Figma link when available]
与现有文档保持一致性。在生成PRD之前,让Claude Code检查相关文档:
是否有与[功能领域]相关的现有PRD、用户故事或技术文档?向我展示现有内容,并说明这份新PRD应该如何引用或与现有文档保持一致。
这能防止矛盾。也许另一份PRD以不同方式定义了用户角色,或建立了你应该遵循的模式。Claude Code可以确保一致性:"认证PRD在第3.2节中定义了管理员角色。在此引用该定义,而不是在此重新定义。"
需求文档的版本控制。提交PRD:
git add docs/prds/bulk-user-import.mdgit commit -m "Add PRD for bulk user import feature"
随着实现在需求演进,更新PRD并提交变更:
git commit -am "Update bulk import PRD: reduce scope to 500 user limit"
Git历史记录显示了什么发生了变化以及为什么。PRD成为反映实际决策的活文档,而非最初的猜测。
时间和成本。生成全面的PRD(6-8页):25-35分钟,50,000-80,000 tokens,$0.25-0.40。较小的功能花费更少,复杂的多组件功能花费更多。
何时PRD能增加价值。以下情况使用PRD:- 需要跨团队协调的功能(工程、设计、市场) - 具有多个集成点的复杂功能 - 涉及合规或安全影响的功能 - 在实现期间和发布后你都会引用的任何内容
以下情况跳过PRD:- 小型的bug修复 - 微小的UI调整 - 正在制作原型的实验性功能 - 只有单个利益相关者的内部工具
不要让文档开销取代对话沟通的作用。
7.4 保持产品文档与实现同步
产品经理传统上将文档视为与代码分离的东西:PRD在Google Docs中,发布说明在Confluence中,产品规格在Notion中。工程团队则以文档即代码的方式处理:仓库中的README文件、从代码注释生成的API文档、在版本控制中维护的变更日志。这种分离导致了漂移。产品文档描述的是应该存在的东西;代码代表的是实际存在的东西。
对PM来说,文档即代码意味着将产品文档与代码一起存放在仓库中。README文件、变更日志、API文档和产品指南以markdown文件的形式存在,进行版本控制,并作为正常工作流的一部分进行更新。Claude Code使其变得可行,它帮助你编写和维护这些文档,而不需要深入的技术知识。
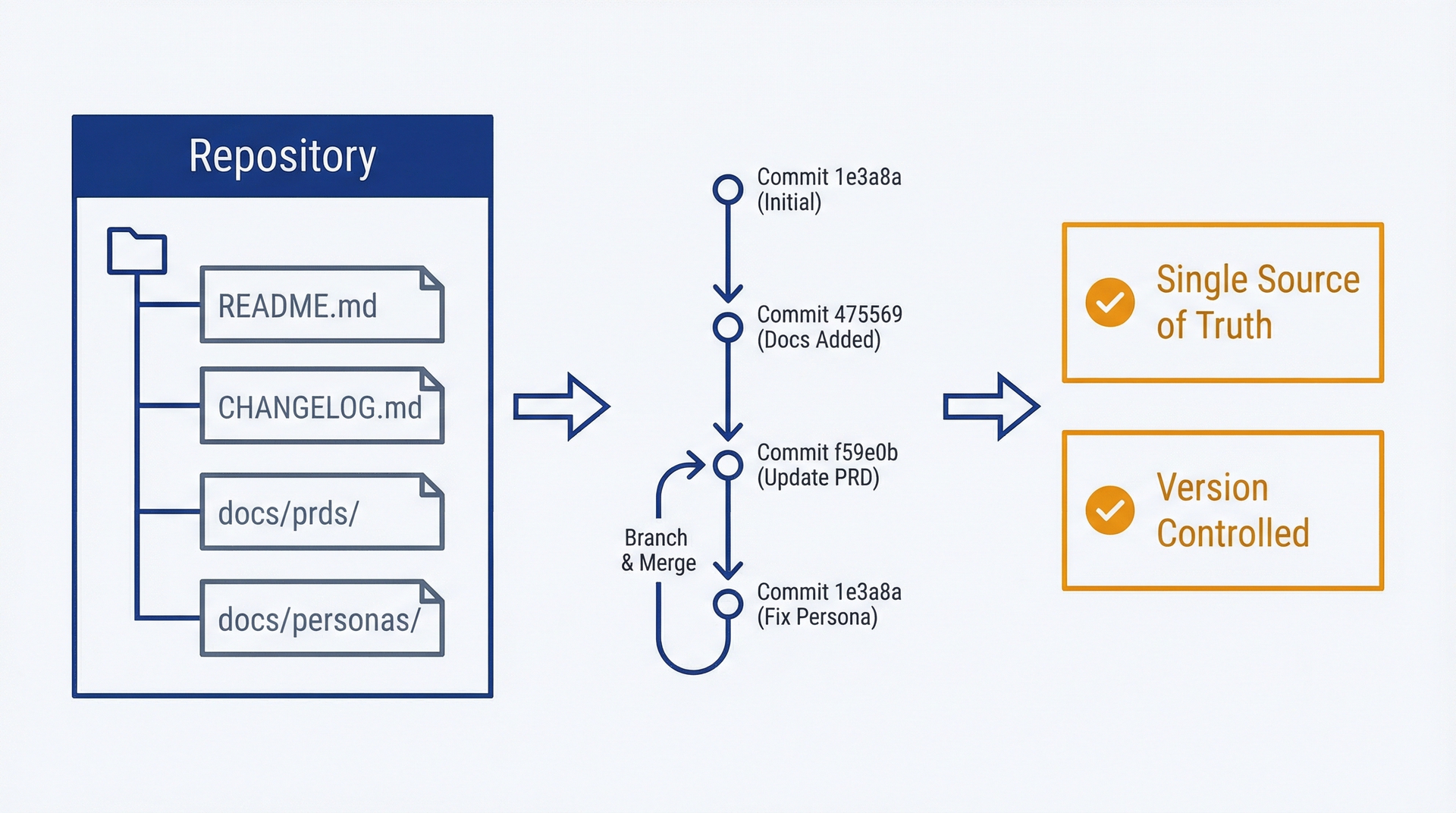
图7.4:文档即代码触发循环——使用此流程使产品文档与代码变更自动保持同步。展示了一个三阶段循环:工程合并代码(触发),Claude Code检测变更并更新文档(执行),PM审查并批准(审批)。该循环持续重复,使PRD、用户指南、变更日志和API文档始终与实现保持同步。
面向PM的文档即代码理念。核心原则:描述产品的文档应该与产品存放在一起。这并不意味着PM要写代码注释,而是说你拥有的产品知识以文件形式存在于仓库中:
- README.md——这个产品是什么,如何上手
- CHANGELOG.md——每个版本中发生了什么变化
- docs/——产品文档、用户指南、操作指南
- docs/api/——API文档(你协作,工程负责实现)
- docs/prds/——需求文档
- docs/personas/——用户画像
这种方式的好处:
唯一真实来源。仓库包含了一切。无需在Google Drive、Confluence和Notion之间寻找分散的文档。
版本控制。文档随产品一起演进。Git历史记录显示了何时发生了变化以及为什么。
接近代码。工程师在工作时看到产品文档。PM在规划时看到技术文档。跨职能的上下文感知增强了。
自动化工作流。Pull request可以同时包含代码变更和文档更新。CI可以检查当功能变更时文档是否已更新。
README更新和变更日志维护。README通常是用户看到的第一样东西。借助Claude Code保持其更新:
提示:README更新
审查并更新README.md以反映产品最近的变更。
当前状态:[简要总结发生了什么变化:新功能、移除的功能、重命名的概念]
更新以下部分:
- 概述:确保功能列表是最新的
- 快速开始:验证安装/设置步骤是否仍然准确
- 核心功能:添加最近的新增内容,移除已弃用的功能
- 配置:如果存在新的配置选项则更新
对新用户保持语气清晰和友好。移除过时信息。
变更日志记录了每个版本中发生的变化。手动维护它们很繁琐。Claude Code可以从git历史中生成变更日志条目:
提示:变更日志生成
通过审查自[上个版本标签]以来的git提交,为版本[X.Y.Z]生成变更日志条目。
格式:
[X.Y.Z] - YYYY-MM-DD### Added- [新功能]### Changed- [现有功能的变化]### Fixed- [Bug修复]### Removed- [已弃用或移除的功能]
聚焦于面向用户的变化。忽略内部重构或代码清理,除非它们影响用户。使用产品语言,而非技术术语。
Claude Code读取提交信息,识别面向用户的变化,并生成结构化的变更日志条目。你审查并编辑以确保准确性和语气适当,然后提交。
API文档贡献。如果你的产品有API,文档就很重要。工程通常负责实现,但PM贡献上下文:端点用于什么目的、服务于什么用例、常见的集成模式。
Claude Code可以帮助编写或改进API文档:
提示:API文档增强
审查docs/api/users.md中关于用户管理端点的API文档。
增强以下内容:
- 用例上下文:开发者什么时候会使用这个端点?
- 常见模式:在集成工作流中通常如何使用?
- 错误处理指南:可能出现什么错误以及如何处理?
- 示例:真实世界的请求/响应示例及说明
保持技术准确性——参考src/server/routes/users.js中的实际API实现来验证端点行为。
你在为技术文档添加产品上下文。工程确保请求/响应模式的准确性;你确保开发者理解为什么以及何时使用该API。
保持产品文档与实现同步。文档即代码的风险与任何文档相同:它会过时。通过流程来缓解这个风险:
在sprint规划期间审查文档。当规划影响面向用户行为的功能时,将"更新文档"作为用户故事中的验收标准。
将PR链接到文档更新。添加功能的工程PR应包含README或变更日志更新。将其作为审查清单的一项。
定期文档审计。每季度,让Claude Code审计文档与实现的一致性:
提示:文档审计
审查docs/中的文档并与当前代码库进行比较。
识别:
- 文档中记录的但已不存在的功能(代码已被移除)
- 存在但未记录的功能
- 文档中与实际配置文件不匹配的配置选项
- 过时的示例或截图
创建一份使文档与实现同步所需的文档更新列表。
Claude Code读取文档和代码,识别漂移,并生成待办列表。你排定优先级并修复最重要的差距。
示例工作流:为功能发布更新文档。你即将发布批量用户导入功能。在发布之前,确保文档准备就绪:
- 更新README:将"批量用户导入"添加到功能列表
- 更新变更日志:为包含此功能的版本添加条目
- 创建用户指南:编写
docs/guides/bulk-user-import.md,包含分步说明 - 更新API文档:如果导入使用API,在
docs/api/中记录端点 - 更新管理员指南:添加关于用户管理及导入的章节
Claude Code帮助完成每一项:
在docs/guides/bulk-user-import.md中为批量用户导入功能生成用户指南。
包含:
- 批量导入是什么以及何时使用
- 分步说明及截图占位符:[Screenshot: Upload CSV button]
- CSV格式要求和模板下载链接
- 常见问题排查(验证错误、文件格式问题)
- 常见问题解答部分
语气:清晰且有帮助。假设读者是具备中等技术技能的管理员。
审查生成的指南,添加实际截图,亲自测试说明以确保准确性,然后提交。
时间和成本。README更新:5-10分钟,10,000-20,000 tokens,$0.05-0.10。从git历史生成变更日志:10-15分钟,15,000-30,000 tokens,$0.08-0.15。创建用户指南:20-30分钟,30,000-60,000 tokens,$0.15-0.30。文档审计:15-25分钟,25,000-50,000 tokens,$0.13-0.25。
文档即代码不适用的场景。有些文档适合放在仓库之外:
- 营销内容(产品页面、落地页)存放在CMS或营销工具中
- 面向最终用户的支持文章存放在帮助台软件(Zendesk、Intercom)中以获得搜索和分析能力
- 销售资料存放在销售赋能工具中
- 长篇幅内容(如此书)更适合使用专门的创作工具
文档即代码适用于:- 技术文档(设置、API、架构) - 面向开发者的内容 - 随代码变化的产品知识(功能、配置、工作流) - 供团队使用的内部文档
根据受众和更新频率选择存放位置。随代码变化的文档放在仓库中。独立变化的文档放在专用工具中。
现在你可以使用Claude Code从研究数据中生成用户画像,创建包含验收标准和边界情况的全面用户故事,生成作为版本控制产物的PRD,并维护与实现同步的产品文档。这些能力将文档从你回避的繁琐任务转变为你作为正常工作流一部分来创建的集成产物。
第8章从单个文档转向可重复的工作流——构建将你的PM流程编码化以便持续一致执行的技能。