第6章
客户反馈与 UX 调研综合
6.1 反馈综合的挑战
你手头有上个季度的 847 张支持工单、200+ 条 NPS 回复、15 份客户访谈转录,还有一个用户每天发布功能请求的 Slack 频道。你的 VP 想要洞察。哪些主题正在浮现?我们应该优先处理什么?客户到底在告诉我们什么?
传统做法:通读所有内容,高亮看起来重要的东西,做一个带分类的电子表格,试图记住三个小时前读到什么,最后产出一份总结——其中 60% 是你清晰记得的内容,40% 是因为新鲜或戏剧性而在脑海中挥之不去的内容。这需要好几天时间,而且会遗漏分散在零散来源中的模式。
你需要系统化的综合:一致的分类、频次分析、主题之间的联系、每个洞察的支持证据。在规模上进行手动综合是不可靠的。你的记忆会优先筛选新鲜度和显著性,而不是实际的频次或重要性。你在阅读过程中理解加深,分类标准前后不一致。你会遗漏隐藏在大量数据中的微弱信号。
Claude Code 系统化了反馈综合。它读取你的所有数据,应用一致的分类标准,追踪频次,识别共同出现的主题,并生成带有支持引述的结构化报告。相同的分析方法论可重复执行。每季度的 NPS 分析每个季度都使用相同的流程,使结果具有跨期可比性。
体量问题:太多反馈,太少模式。随着你的产品增长,反馈体量会压倒手动分析。你需要处理成百上千个数据点来找到信号。Claude Code 穷举而非有选择性地处理数据。它读取全部 847 张工单,而不是抽样。它对全部 200 条 NPS 回复进行一致分类。
格式问题:数据分散在不同工具和格式中。反馈存在于 Zendesk、Intercom、Google Forms、电子邮件、Slack、销售电话记录、Twitter 提及中。不同格式,不同结构。综合首先需要将所有内容转化为可分析的形式:导出、转换、整合。Claude Code 原生支持多种文件格式:来自 Zendesk 的 CSV、来自 Intercom 的 JSON、来自访谈转录的纯文本、来自会议记录的 markdown。
优先级问题:什么最重要?原始反馈不会自带优先级评分。你需要识别什么频繁出现、什么造成实际痛苦而非轻微不便、什么阻塞工作流而非制造麻烦。综合揭示模式。15% 的反馈提到导出速度慢,这可能是客户礼貌地只提过一次的关键路径问题,而不是五个用户反复要求的响亮功能请求。
Claude Code 解决这些问题,每次综合会话花费 $0.40-0.90,耗时 30-60 分钟。对比两天的体力劳动,产出不一致且难以重复或更新的结果。
这种方法大材小用的情况:如果你只有 20 条反馈,自己读。如果反馈已经是高度结构化的(数值型问卷回复、是否题),用电子表格。Claude Code 的价值体现在你有大量非结构化的定性数据(文本反馈、访谈转录、开放式回复),其中模式识别需要真正读完所有内容。
6.2 为分析准备数据
Claude Code 读取文件,而不是直接读取数据库或 SaaS 工具。你需要将反馈数据导出为 Claude Code 可以处理的格式。这需要 10-20 分钟的设置工作,之后在未来的综合周期中就可以重复使用。
从常见来源导出数据:大多数反馈工具都提供 CSV 或 JSON 导出。具体操作因工具而异,但目标是相同的:将数据变成文件。
Zendesk:导航到 Reporting → Explore → Create report → Select tickets → Filter by date range → Export as CSV。导出包含工单主题、描述、评论、状态、标签、自定义字段。每行一个工单,所有交互历史拼接在一起。文件大小因评论量而异:1,000 个工单通常生成 5-15MB。
Intercom:Go to Reporting → Conversations → Export conversations → Select date range and filters → Download CSV or JSON。CSV 格式更简单,适合分析;JSON 包含更丰富的元数据,如果你需要的话。典型导出量:500 个对话 = 3-8MB。
问卷工具(Typeform、Google Forms、SurveyMonkey):都提供 CSV 导出。回复导出为每人一行,每个问题作为一列。开放式文本回复是你需要的:那些段落长度的答案列,而不是选择题。
NPS 工具:导出数值评分和"你为什么给出这个分数?"的文本回复。文本比数字对综合更有价值。你想要理解什么驱动了评分。
Slack:对于频道中的功能请求或反馈,将相关讨论串复制到文本文件中,或使用 Slack 的导出功能。格式不太重要。Claude Code 可以处理频道导出(JSON)或你粘贴对话的纯文本文件。对于小体量,手动复制粘贴到文本文件比搞清楚 Slack 的导出 API 更快。
访谈转录:如果你录制并转录了用户访谈,你可能已经拥有文本文件或 Word 文档。将 Word 文档转换为纯文本(.txt)或 markdown(.md)。Claude Code 两者都能处理。如果你使用 Otter.ai 或 Rev 等转录服务,导出为纯文本。
邮件反馈:将相关的客户邮件转发到一个文件夹,然后导出该文件夹。或者复制粘贴邮件到文本文件中,邮件之间用清晰的分隔符。格式:每个邮件讨论串一个文件,或一个合并文件,用类似 --- 的分隔符在邮件之间。
Claude Code 能很好处理的文件格式:
CSV 是结构化反馈的理想格式,有统一的字段。每行是一个反馈项(工单、问卷回复、NPS 评论)。列是属性(日期、客户姓名、反馈文本、类别、评分)。Claude Code 原生读取 CSV,可以按行系统化地分析。
JSON 适用于包含嵌套数据的更复杂导出。Intercom 导出包含对话讨论串、用户元数据、标签层级。Claude Code 解析 JSON 结构并提取相关字段。
纯文本(.txt)是通用格式。访谈转录、邮件讨论串、Slack 对话:任何内容都可以变成纯文本。最小限度地结构化,用空行或分隔符隔开每个反馈项。如果有用,可以内联添加基本元数据:"User: enterprise_customer_47 / Date: 2026-01-15 / Feedback: [text]"
Markdown(.md)类似纯文本但带有轻量级格式。用标题来区分反馈来源或访谈。对于你想保留发言者标签和问题结构的访谈转录很有用。
Claude Code 不能处理的:未经转换的二进制格式。Word 文档(.docx)、扫描文本的 PDF、手写笔记图片、音频文件都需要先转换为文本。对于 PDF,使用 PDF 导出工具提取文本。对于音频,使用 Otter.ai、Rev 或类似服务进行转录。
分析前清洗数据:你不需要完美的数据,但基本的清洗能改善结果。
移除 PII(个人身份信息)。客户姓名、电子邮件地址、电话号码、账户 ID:任何能识别个人的信息。替换为通用标签:"Customer_1"、"Enterprise_user"、"Trial_account"。你分析的是模式,不是追踪个人。移除 PII 可以防止意外暴露(如果你分享分析输出),并尊重隐私。
如果你的导出有"Name"列,将值替换为通用 ID。如果反馈文本中包含"Hi Sarah"或提到了电子邮件,进行查找替换或涂抹。Claude Code 不会自动清洗 PII。这是你在分析前要做的责任。
标准化文件内的格式。如果你的 CSV 有日期格式不一致(有些是"1/15/2026",有些是"January 15, 2026"),选择一种格式。如果有些反馈用花引号,有些用直引号,这没关系。如果回复混合了多种语言,注意这一点。Claude Code 处理多语言文本,但可能在跨语言分类时产生差异。
删除空行和非反馈数据。CSV 导出通常包含标题行、含导出元数据的尾部行,以及章节之间的空行。删除这些。每一行应该是一个反馈项。文本文件应该只包含反馈,不包含导出时间戳或系统消息。
隐私和 PII 注意事项:反馈数据是敏感的。客户分享意见是因为信任你会用来改进产品,而不是暴露他们的身份。
默认进行匿名化。除非你有特定需要按个人追踪反馈(客户流失风险分析、大客户高接触管理),否则移除身份信息。这使得分享综合输出更安全。你可以在 Slack 中发布主题报告或附加到 PRD 而无需担心隐私问题。
明确说明你在分析什么。如果你通过 API 使用 Claude Code,数据由 Anthropic 的系统处理,不会用于训练。如果你担心敏感反馈(医疗、金融、法律领域),查阅 Anthropic 的数据处理政策或考虑本地部署的替代方案。
不要分析客户在保密协议下提供的反馈。企业客户访谈通常包含 NDA 或保密协议。如果你承诺不将具体反馈对外分享,就不要将其放入数据管理方式你不太确定的系统中。如有疑问,排除该数据或咨询你的法务团队。
典型的准备工作流:
- 从源工具导出数据(多个来源 10-15 分钟)
- 在电子表格或文本编辑器中使用查找替换移除 PII(5-10 分钟)
- 清洗明显的数据问题——空行、格式不一致(5 分钟)
- 将文件保存到项目目录:feedback/2026-q1/,文件名带描述性,如 zendesk-tickets.csv, nps-responses.csv, interview-transcripts.txt
总准备时间:一次典型季度综合需要 20-40 分钟。这是每个综合周期的一次性工作。一旦数据准备好了,分析运行就很快。
数据量多大算太多?Claude Code 可以处理大文件,但 token 消耗随文件大小线性增长。一个包含 1,000 条反馈项(总共约 200,000-500,000 字)的文件完整处理花费 $1.00-2.50。将大型数据集拆分为较小的文件可以帮助管理成本。分别分析每个文件,然后汇总主题。
如果你有超过 2,000 条反馈项,考虑以下之一:- 抽样(分析随机子集,仍然比手动检查更系统化)- 批处理(按时间段或来源拆分,分别分析,然后对比)- 分层综合(按细分分别分析:企业 vs. SMB,新用户 vs. 老用户等)
对于典型的 PM 用例(季度综合、发布后反馈审查、路线图规划的主题分析),你通常处理 100-1,000 条反馈项。这在 Claude Code 的高效处理范围内。
6.3 在数百条回复中寻找模式
你已经准备好了反馈数据。现在需要提取主题:在你的数据中反复出现的主题、问题、请求和情绪。主题分析识别模式并量化每个主题出现的频次。
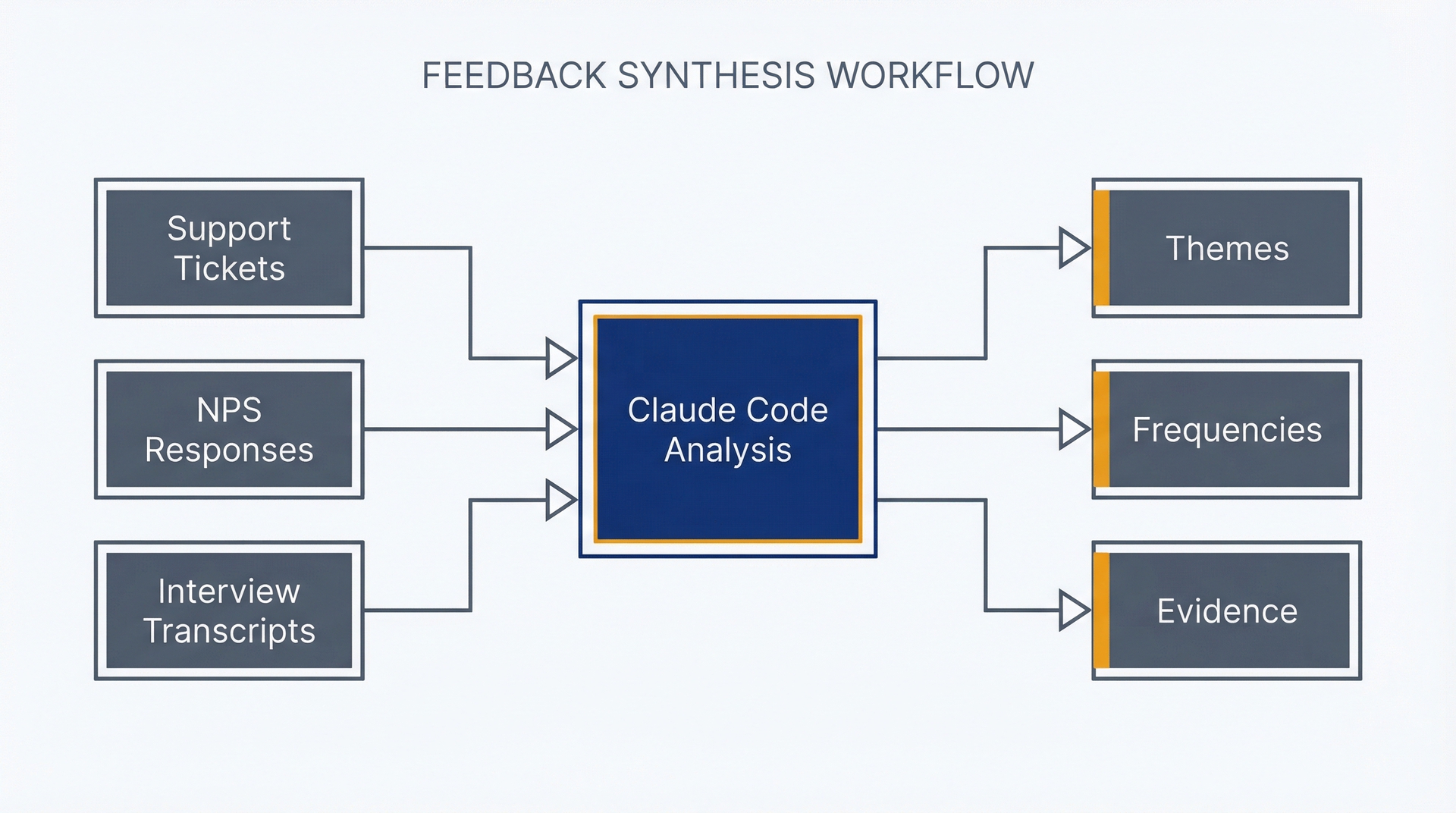
图 6.1:反馈综合工作流——使用此流程将分散的客户数据转化为可行动的洞察。原始数据源(支持工单、NPS、访谈)通过 Claude Code 分析,生成带有频次、情绪和支持证据的结构化主题。
提示词模板:反馈分类。从让 Claude Code 识别主题开始。如果你知道自己要找什么,可以预先定义类别;也可以让主题从数据中自然涌现。
以计划模式启动 Claude Code——你正在读取和分析,还没有写入文件:
claude --permission-mode plan
提示词:自然涌现主题识别
读取 feedback/2026-q1/ 中的所有反馈,识别反复出现的前 10-15 个主题。
对于每个主题:
- 主题名称:简洁标签(3-5 个词)
- 描述:这个主题代表什么(1 句话)
- 频次:有多少条反馈提到了这个主题
- 代表性引述:2-3 条说明这个主题的示例引述
按频次排列。除非代表关键问题,否则只纳入出现至少 5 次以上的主题。
Claude Code 读取你的反馈文件,识别反复出现的主题,计数出现次数,并提供结构化输出。你会得到类似这样的结果:
Theme: Slow Export PerformanceDescription: Users report that exporting large datasets takes too long or times out.Frequency: 87 mentions across tickets and NPS responsesRepresentative quotes:- "Tried to export 50k records and it timed out after 10 minutes. This is unusable for our reporting needs."- "Export feature is frustratingly slow. Takes 5+ minutes for medium-sized exports."- "Please fix export speed—this is blocking our monthly reports."## Theme: Missing Bulk Edit CapabilitiesDescription: Users want to edit multiple items simultaneously rather than one at a time.Frequency: 64 mentionsRepresentative quotes:- "I need to update 200 records with the same tag. Having to do this one-by-one is painful."- "Why can't I select multiple items and apply changes? This is standard in every tool we use."- "Bulk editing would save me hours per week."
定义类别:用户定义 vs. 自然涌现。你有两种分类方法。
自然涌现主题:让 Claude Code 识别数据中出现的内容,不带着预设的类别。这是探索性的;你会发现客户实际在谈论什么。当你对反馈主题没有强烈的假设,或者想验证你的预设类别是否匹配现实时使用这种方法。
预定义类别:给 Claude Code 提供具体的分类标准。当你已经建立了分类体系(功能请求、bug、可用性问题、性能投诉、文档缺口)并且希望随着时间推移对反馈进行一致的分类时使用这种方法。
提示词:预定义类别分类
读取 feedback/2026-q1/ 中的所有反馈,将每个反馈项分类到以下类别中:
- 功能请求
- Bug 报告
- 性能问题
- 可用性/UX 问题
- 文档缺口
- 集成需求
- 定价/计费问题
- 其他
对于每个类别:
- 统计有多少条反馈项属于该类别
- 列出该类别中被提到最多的前 5 个具体问题
- 提供 2-3 条代表性引述
如果一条反馈涉及多个类别,在每个适用类别中都计数。
这将产生一个结构化的分解,显示你收到了 127 个功能请求(前三大请求是 X、Y、Z),89 个 bug 报告(集中在 A、B、C 区域),64 个性能问题,等等。
使用哪种方法:自然涌现用于发现和验证。预定义用于一致性及跨时间段对比。你可以先使用自然涌现分析来建立类别体系,然后在未来季度将这些类别作为预定义分类体系来追踪主题分布的变化。
频次分析与优先级排序。原始频次很重要,但不是一切。10 条关于关键工作流阻塞的投诉可能比 50 条关于外观小毛病的投诉更重要。Claude Code 帮助你在频次之上叠加上下文。
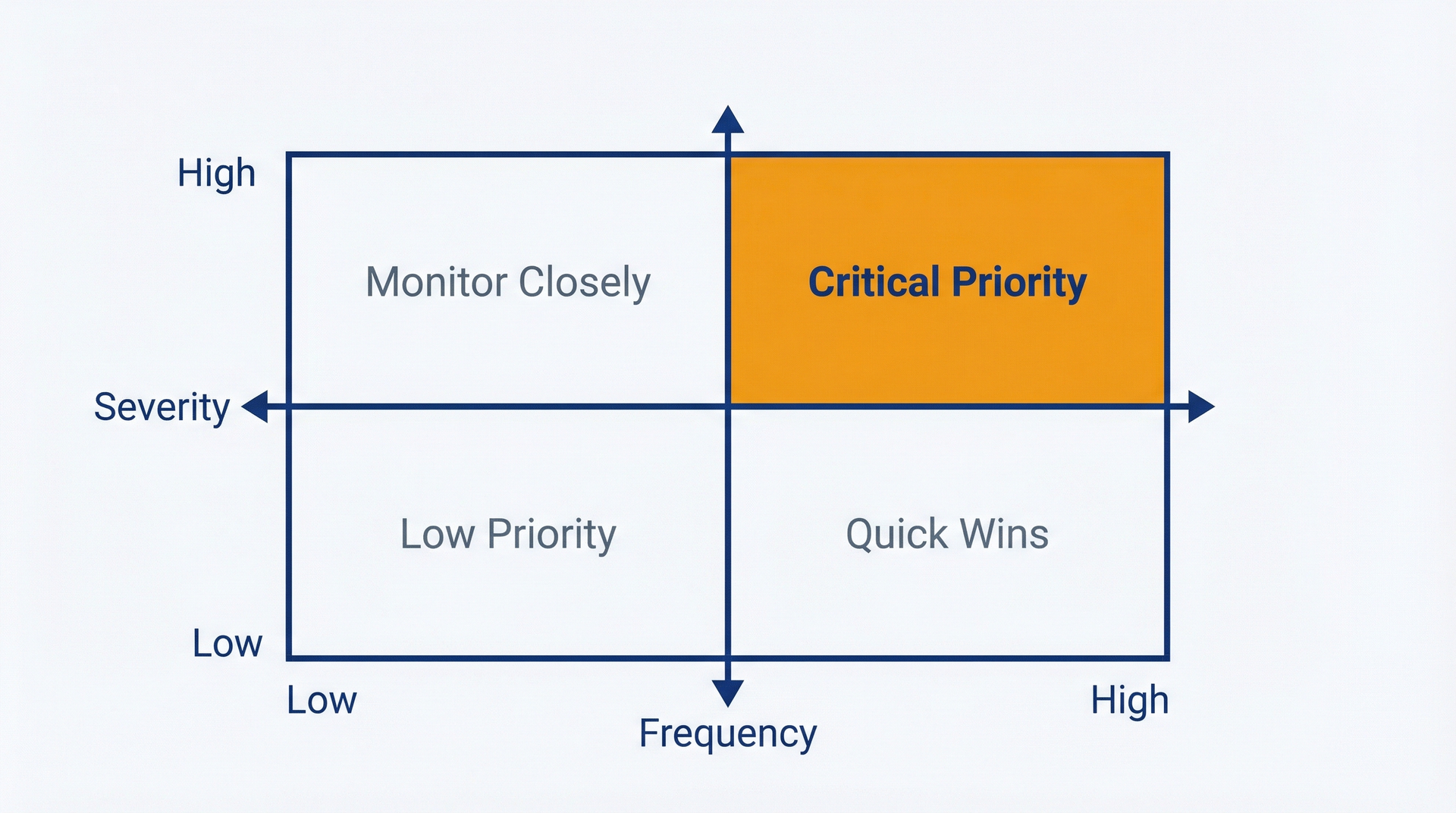
图 6.2:优先级矩阵——使用此矩阵识别哪些反馈主题需要立即关注。x 轴为频次,y 轴为严重性。高频次 + 高严重性象限(右上角)表示应驱动路线图决策的关键优先级项。
提示词:频次与影响分析
审查之前分析中识别出的主题。对于每个主题,评估:
频次层级:
- 高:超过 10% 的反馈项提到
- 中:5-10% 的反馈项提到
- 低:少于 5% 但仍值得关注
严重性信号(基于使用的语言):
- 严重:语言如"阻塞"、"无法完成工作"、"致命问题"、"正在考虑替代方案"
- 高:语言如"令人沮丧"、"耗时"、"痛苦"、"需要修复"
- 中:语言如"会很好"、"改进"、"建议"
- 低:语言如"小问题"、"不紧急"、"锦上添花"
创建一个优先级矩阵:频次 × 严重性。突出那些既频繁又严重的主题。
这会揭示"沉默杀手":很多客户用高严重性语言提到的问题,而你如果只追逐最大声的反馈可能会忽略它们。同时也能降低噪音的优先级,即很多人提到但用的语言影响程度低,说明这实际上并没有阻塞他们的工作。
在主题上叠加情绪分析。除了频次和严重性,你还需要了解情绪。客户对此是愤怒还是轻微烦恼?正常运行时会感激还是无所谓?
提示词:按主题的情绪分析
对于每个识别出的主要主题,分析提到该主题的反馈中的情绪:
- 正面:客户满意、赞扬、感谢
- 中性:事实性报告、无情绪的建议
- 负面:沮丧、失望、愤怒
- 混合:既有正面又有负面(例如,"很喜欢这个功能但性能太差")
提供情绪分布(例如,"Slow Export Performance: 5% positive, 15% neutral, 75% negative, 5% mixed"),如果数据中可见,注意不同客户细分中的情绪模式。
情绪揭示紧迫性。一个有 90% 负面情绪的主题无论如何都需要关注,无论频次如何。一个情绪混合的主题可能说明该功能在某些用例中运作良好但在其他情况下不适用——意味着需要针对性改进而不是全面变更。
输出格式:带支持引述的主题报告。综合输出应该简洁可操作。不是 50 页的文档,而是一个你可以在路线图规划中引用的结构化报告。
提示词:生成主题报告
基于主题分析,在 feedback/2026-q1/theme-report.md 中创建一份反馈综合报告。
结构:
- 高管摘要(1 段):按频次排前 3 的主题和按严重性排前 3 的主题
- 详细主题(每个主题一个章节):
主题名称和描述
- 频次及占总反馈百分比
- 严重性评估
- 情绪分布
- 代表性引述(3-5 条引述)
- 受影响的客户细分(如果可识别)
- 建议的行动或调查方向
- 交叉模式(1 段):经常共同出现的主题
- 微弱信号(要点列表):值得监控的低频主题
总报告控制在 6 页以内。优先考虑清晰度而非完整性。
Claude Code 生成结构化的报告文件。切换到普通模式以允许文件写入:
/exitclaude
再次运行提示词。Claude Code 将主题报告写入你的仓库。提交:
git add feedback/2026-q1/theme-report.mdgit commit -m "Add Q1 2026 feedback synthesis report"
主题分析的时间与成本:读取并分析跨多个文件的 500 条反馈项:20-30 分钟,60,000-120,000 token,$0.30-0.60。生成结构化主题报告:10-15 分钟,25,000-45,000 token,$0.13-0.23。完整主题综合总计:30-45 分钟,$0.45-0.85。
主题分析会失效的情况:如果反馈过于异质,每个客户想要的东西完全不同,主题就无法浮现。这意味着你的产品服务了太多用例,或者你的客户群体太过多样,无法进行有意义的综合。先按细分(行业、公司规模、用户角色)分组,然后分别分析各细分。
如果反馈极其稀疏(50 条反馈覆盖 30 个不同的主题),统计模式就不存在。直接手动读取反馈即可。主题分析在规模上增加价值,对小数据集没有意义。
如果反馈质量低(单字回复,只说"好/坏"而没有解释),就没有什么可以综合的。这是数据收集问题,而不是分析问题。通过改进问卷问题、访谈提纲和支持工单模板来提升反馈收集质量。
6.4 从访谈转录中提取洞察
反馈工单告诉你什么出了问题。UX 调研告诉你用户为什么挣扎以及他们试图完成什么。综合调研需要不同于反馈的技术。你是在分析叙事,而不是分类投诉。
分析访谈转录。用户访谈产生丰富的定性数据:故事、工作流、痛点、心智模型。综合从这些叙事中提取洞察。
准备转录:每个访谈一个文件,或一个带清晰分隔符的合并文件。一致地标注发言者(Interviewer: / Participant: 或 Q: / A:)。移除身份信息。
典型结构:
Interview with Enterprise_Customer_12Date: 2026-01-15Role: Operations ManagerCompany size: 500 employeesQ: Walk me through how you currently handle [workflow].A: We start by exporting data from our CRM, which is already frustrating because...[rest of transcript]
启动 Claude Code:
claude --permission-mode plan
提示词:访谈综合
读取 research/interviews/interview-[ID].txt 中的访谈转录,综合关键洞察。
提取:
- 痛点:什么让这个用户沮丧?什么出了问题或难以使用?(要点列表,附引述)
- 工作流:用户试图完成什么?他们的流程是什么?(叙事描述)
- 变通方法:他们使用什么技巧或替代工具来弥补不足?(要点列表)
- 心智模型:用户如何理解问题空间?他们使用什么术语?(段落)
- 未满足的需求:什么能让这个用户的工作更轻松?存在哪些缺口?(要点列表)
- 成功标准:这个用户如何定义该工作流的成功?(要点列表)
聚焦于用户所说的直接洞察,而非解读。用引述来支持每一点。
Claude Code 读取转录并生成结构化输出。你会得到带有支持引述的痛点、以用户原话描述的工作流,以及清晰表述的需求。
提示词模板:访谈综合。对于单个访谈,上述方法有效。对于多个访谈(来自一项调研研究的 10-20 份转录),你需要汇总:
提示词:多访谈综合
读取 research/interviews/ 中的所有访谈转录,综合跨访谈的模式。
对于以下每个类别,识别跨多个访谈出现的主题(不是个别的一次性提及):
痛点(反复出现的问题):
- 主题名称
- 有多少个访谈提到了这个(例如,"8 of 12 interviews")
- 来自 2-3 个不同访谈的代表性引述
- 基于使用语言的严重性评估
工作流模式(用户如何完成任务):
- 描述的常见工作流
- 有多少用户遵循这种模式
- 提到的变体或替代方法
未满足的需求(用户希望存在的东西):
- 需求描述
- 有多少用户表达了这一点
- 该需求产生的情境或用例
细分差异(如果适用):
- 注意任何按用户角色、公司规模、行业或其他可见细分不同的模式
按频次排序——聚焦于至少在 3 个访谈中出现的主题,除非某一次提及代表了一个关键洞察。
这产生跨访谈的模式。你会发现 12 个访谈中有 9 个提到了数据导出慢是一个痛点,7 个提到手动数据输入是缺乏集成的变通方法,5 个表示需要实时协作功能。
识别痛点和未满足的需求。两者的区别很重要:
痛点是对当前状态的不满:那些出错的、令人沮丧的、缓慢的、令人困惑的东西。这些对应着 bug、性能改进、可用性修复。例如:"导出太慢"是对你产品的痛点。
未满足的需求是缺口:用户想要但没有的东西。这些对应着功能请求、集成、工作流增强。例如:"我希望能在工具内直接给团队成员分配任务"是一个未满足的需求。
有时反馈同时表达两者:"我不得不手动复制数据到 Slack 来通知团队[痛点],这既耗时又容易出错。我希望有 Slack 集成[未满足的需求]。"
让 Claude Code 区分这些:
提示词:痛点 vs. 未满足的需求
审查调研综合,将洞察分类为:
- 痛点:需要修复的当前产品问题
- 未满足的需求:用户想要但目前不存在的功能
对于每一项,注意:
- 频次(有多少用户提到)
- 紧迫性(基于语言和上下文)
- 潜在解决方案(什么可能解决此问题)
这为路线图规划创建一个优先级列表。痛点进入 bug/性能待办列表;未满足的需求进入功能路线图。
从定性数据创建用户旅程地图。旅程地图可视化用户工作流并突出用户在哪里挣扎。Claude Code 不能画图,但它可以结构化旅程数据供你可视化或分享。
提示词:旅程地图数据
基于 research/interviews/ 中的访谈转录,为[具体工作流]过程创建结构化的用户旅程地图。
对于用户旅程的每个步骤:
- 步骤名称:用户正在做什么(动词短语:"Exporting data"、"Reviewing results")
- 用户目标:他们在这一步中试图完成什么
- 采取的行动:他们所做的具体事情(点击、输入、等待、切换工具)
- 痛点:在这一步中什么令人沮丧或困难
- 情绪状态:用户感受如何(基于使用的语言:frustrated, satisfied, confused, neutral)
- 使用的工具:涉及哪些系统/工具
- 机会:哪些改进可以提供帮助
以结构化列表或表格的形式输出,我可以转换为可视化的旅程地图。
Claude Code 生成结构化的旅程数据:
Step 1: Gathering Source DataUser goal: Collect all necessary data from multiple systems before analysisActions taken:- Export CSV from CRM (5-10 minutes wait time mentioned in 7 interviews)- Download spreadsheet from finance system- Copy-paste from email threads or Slack- Combine into master spreadsheet manuallyPain points:- "Exports are slow and sometimes time out" (9 interviews)- "Data formats don't match, have to reformat" (6 interviews)- "I never know if I have the latest data" (4 interviews)Emotional state: Frustrated ("tedious", "annoying", "waste of time" mentioned)Tools used: CRM system, finance ERP, Excel/Google Sheets, email, SlackOpportunities:- Speed up export performance- Standardize export formats- Real-time data sync instead of manual export- Unified dashboard eliminating manual gathering
你拿着这些结构化数据,在 Miro、Figma 或 PowerPoint 中创建可视化旅程地图。洞察工作已经完成。Claude Code 通过分析用户的表述来识别痛点、机会和情绪状态。
跨多个访谈汇总洞察。10-15 个访谈时,手动综合可行但耗时。20-30 个访谈时,手动综合不可靠。你读到后面的访谈时就会忘记前面访谈的细节。Claude Code 一致地处理所有访谈。
提示词:调研研究摘要
将 research/interviews/ 中的所有访谈综合为 research/study-summary.md 中的高管调研摘要。
包含:
- 调研概览:多少访谈、我们与谁对话(角色、细分)、我们问了什么
- 关键发现:跨多个访谈出现的前 5-7 条洞察(按频次和重要性排序)
- 痛点:用户面临的主要问题(按频次和严重性排名)
- 未满足的需求:主要的功能/能力需求(按频次排名)
- 细分洞察:按用户细分不同的模式(如果适用)
- 建议:基于发现建议的产品/设计行动(3-5 条要点)
- 支持证据:按主题组织关键引述的附录
目标长度:4-6 页。针对利益相关者的可读性进行优化。
Claude Code 生成一个你可以与领导层、设计和工程团队分享的综合文档。这成为驱动路线图讨论的产出物。
UX 调研综合的时间与成本:单份访谈分析:10-15 分钟,20,000-40,000 token,$0.10-0.20。多访谈综合(10-15 个访谈):30-45 分钟,80,000-150,000 token,$0.40-0.75。旅程地图数据提取:15-20 分钟,30,000-50,000 token,$0.15-0.25。
局限性:Claude Code 综合的是用户所说的内容,而不是他们的真实意思。它不能读取肢体语言,不能解读语调,也无法捕捉讽刺。它不理解你拥有但没有记录下来的上下文:用户明显感到困惑,通过长时间的停顿表现出沮丧,在讨论某个特定功能时眼睛发亮。人类研究员带来的解读是 Claude Code 不具备的。
用 Claude Code 做机械性工作:读取转录、识别反复出现的主题、统计频次、提取引述。用你自己的判断来做解读:理解用户为什么挣扎,什么才是真正重要的,哪些需求与产品愿景对齐。
6.5 从洞察到行动
没有行动的综合只是"研究表演"。你需要将洞察与决策联系起来:什么进入路线图,什么被优先处理,什么基于你学到的东西被降级。
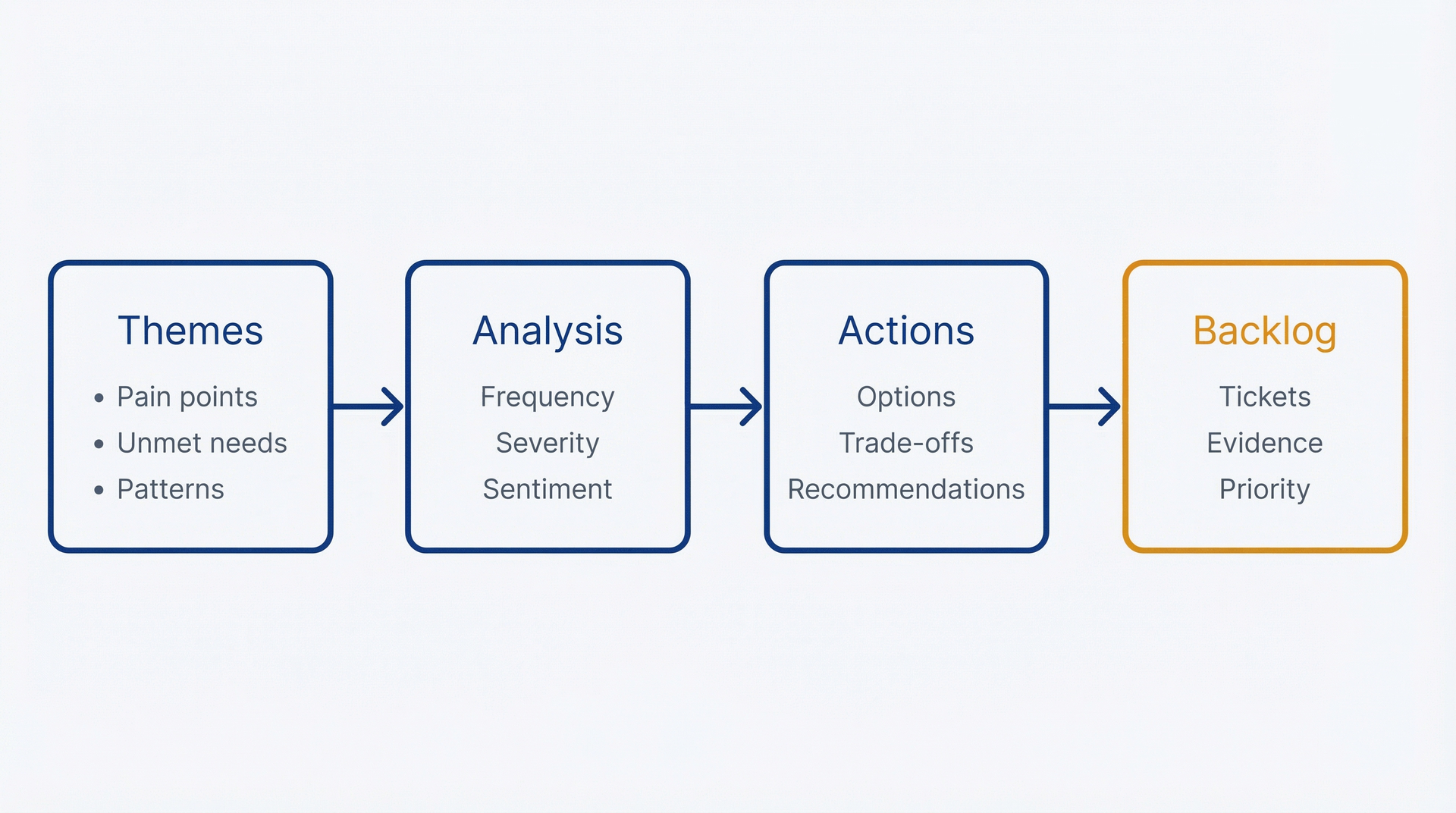
图 6.4:从研究到产出物的流水线——使用此流程将原始反馈转化为优先级排列的待办项,同时在关键决策点保持人工监督。流水线从原始数据(反馈、NPS、工单)经过 AI 分析(模式检测、主题)到人工判断关卡,PM 在此应用领域知识、业务上下文和优先级判断,然后生成经过验证的、可行动的待办项。
将反馈主题与产品决策关联。你综合中的每个主题都应该对应一个潜在的产品行动。不是每个主题都会成为路线图条目,但每个主题都值得被考虑。
提示词:洞察到行动映射
审查 feedback/2026-q1/theme-report.md 中的主题报告,将每个主要主题映射到潜在的产品行动。
对于每个主题:
- 主题:名称和简要描述
- 当前状态:我们今天做的(如果适用)
- 可能的行动:2-4 个解决此问题的选项(bug 修复、功能增强、新功能、流程变更、文档完善、不处理)
- 权衡:每个行动需要什么(工程工作量、设计工作量、时间、复杂度)
- 建议:考虑到频次、严重性和可行性,哪个行动最合理
对权衡要实事求是。不是所有事情都可以是 P0。有些可能是"监控但暂不行动"。
Claude Code 生成一份映射文档:
Theme: Slow Export PerformanceCurrent state: Export feature exists, works for small datasets (<10k records), degrades performance for larger datasets.Possible actions:1. Optimize existing export - Investigate and fix performance bottlenecks - Trade-offs: 2-3 weeks eng effort, might not solve for very large exports2. Implement async export: Move large exports to background processing with email notification - Trade-offs: 4-5 weeks eng effort, requires infrastructure changes, but scales to any size3. Add export limits: Cap export size and suggest alternative approaches - Trade-offs: Minimal eng effort, but doesn't solve user need4. Don't address: Accept that export is slow for large datasets - Trade-offs: None, but continued user frustration and potential churnRecommendation: Option 2 (async export). High frequency (87 mentions) and high severity justify the investment. Solves the root cause rather than papering over it. Aligns with enterprise growth strategy where large exports are expected.
这成为你路线图对话的基础。你不仅仅是说"用户想要更快的导出"。你是在呈现带权衡的选项和基于推理的建议。
提示词模板:洞察到行动映射。关键是从"我们了解到 X"转变为"因为 Z,所以我们应该做 Y。"
Claude Code 中的优先级框架。你有相互竞争的洞察、有限的工程资源、以及利益相关者的各种意见。优先级框架帮助你做出系统化的决策。
提示词:RICE 优先级排序
将 RICE 优先级框架(Reach × Impact × Confidence / Effort)应用于洞察到行动映射中识别出的潜在行动。
对于每个潜在行动,估算:
- Reach:这影响多少用户?(评分:1-10,10 = 大多数用户)
- Impact:这将多大程度上改善用户体验?(评分:3 = 巨大,2 = 高,1 = 中,0.5 = 低)
- Confidence:我们对 Reach 和 Impact 估算的信心程度?(评分:100% = 高信心,80% = 中,50% = 低)
- Effort:这需要多少工作量?(以人周评分:1, 2, 4, 8, 12)
计算 RICE 得分:(Reach × Impact × Confidence) / Effort
按 RICE 得分排列行动。标记出那些信心评分低、需要在排序前做更多验证的行动。
Claude Code 为每个潜在行动打分并排名。你获得数据驱动的优先级排序,而不仅仅是直觉。此框架使假设明确化。你可以争论某个功能的"Impact = 2"是否合适,但至少你是在争论具体问题,而不是模糊的"这个似乎很重要"。
替代框架:
Value vs. Effort 矩阵(比 RICE 更简单):> 对于每个行动,评定:> > - Value:用户影响 × 频次(高/中/低)> - Effort:工程复杂度和时间(高/中/低)> > 绘制在 2×2 矩阵上:> > - 高 Value + 低 Effort = 现在就做> - 高 Value + 高 Effort = 规划到下个季度> - 低 Value + 低 Effort = 锦上添花> - 低 Value + 高 Effort = 不做
Kano 模型(用于功能优先级排序):> 对于每个未满足的需求,分类:> > - Must-have:缺失会导致不满(痛点修复、关键缺口)> - Performance:越多越好(速度提升、容量增加)> - Delight:意想不到的、让用户眼前一亮的功能(新颖能力)> > 优先级:Must-haves 优先(基本门槛),然后是 Performance(竞争优势),最后是 Delight(差异化)
选择一个框架,系统化地应用,记录结果。你的路线图变得经得起推敲,因为你可以解释优先级排序逻辑。
创建由反馈驱动的待办项。综合结果输入你的待办列表。每个可行动的洞察变成一个工单:bug、功能请求、技术债、设计任务。
提示词:生成待办项
基于洞察到行动映射中优先级排列的行动,为前 5 个行动起草待办项。
对于每个行动,按以下格式创建工单:
- 标题:[简洁的、面向行动的标题]
- 问题:我们正在解决什么用户问题?(2-3 句话,引用综合发现)
- 证据:来自综合的支持数据(频次、严重性、代表性引述)
- 建议方案:我们正在考虑什么(高层次,不是详细规格)
- 成功标准:我们如何知道这解决了问题(最好可衡量)
- 估算工作量:粗略大小(小/中/大 或 T 恤尺码)
- 优先级:基于应用的优先级框架给出建议
- 相关反馈:链接到主题报告章节以获取完整上下文
Claude Code 生成你可以复制到 Jira、Linear 或你的待办工具中的草稿工单。你仍然需要完善(添加技术细节、与工程协调、根据其他因素调整优先级),但从调研到待办的连接是明确的。
示例待办项:
Title: Implement async export for large datasetsProblem: Users exporting large datasets (>10k records) experience timeouts and extremely slow performance, blocking their reporting workflows and causing frustration.Evidence: Q1 2026 feedback synthesis identified slow export as #1 pain point - 87 mentions across tickets and NPS responses (10.3% of all feedback). Severity assessed as high based on language ("blocking", "unusable", "considering alternatives"). Representative quote: "Tried to export 50k records and it timed out after 10 minutes. This is unusable for our reporting needs."Proposed solution: Move large exports (>5k records) to background processing. User initiates export, receives email when ready. Allows exports of any size without browser timeout constraints.Success criteria:- Users can successfully export 100k+ record datasets- Export requests complete within 10 minutes for datasets up to 100k records- Reduction in "slow export" support tickets by >70%- NPS score improvement among users who frequently exportEstimated effort: Large (4-5 weeks eng + infrastructure changes)Priority: P1 - High impact, high frequency, aligns with enterprise growth strategyRelated feedback: See feedback/2026-q1/theme-report.md section "Slow Export Performance"
这个工单将用户证据直接连接到工作。工程团队理解为什么这很重要。领导层看到调研基础。利益相关者可以引用实际数据来挑战假设。
洞察到行动的时间与成本:将主题映射到行动:15-20 分钟,25,000-40,000 token,$0.13-0.20。应用优先级框架:10-15 分钟,15,000-30,000 token,$0.08-0.15。生成待办项:10 分钟,15,000-25,000 token,$0.08-0.13。总计:35-45 分钟,$0.30-0.50。
这种方法会失效的情况:如果你的产品策略是高度主观的(创始人驱动的愿景、设计主导的创新),反馈综合可以起到参考作用但不能决定一切。不是每个客户需求都与你产品的方向一致。用综合来理解战略选择的影响,而不是让客户设计你的产品。
如果反馈是相互矛盾的——一半用户想要 X 而另一半想要相反的东西——综合能揭示冲突但无法解决它。这是一个细分问题。要么以不同的方式服务这两个细分,要么选择你为哪个细分构建产品。
如果你的待办列表已经超负荷且不可更改(已承诺的路线图、受监管行业、技术债占主导),综合会成为你无法做什么的记录,而不是你将做什么的文档。理解机会成本仍然是有价值的,但不要期望它能重塑优先级。
你现在可以系统化地综合客户反馈和 UX 调研,将其转化为可行动的产品洞察。你已经将 847 张支持工单和 15 份访谈转录从压倒性的噪音转变为带有支持证据、优先级评分和待办项的结构化主题。这一能力将你的 PM 工作流从被动救火转变为策略性的、以调研驱动的规划。
第 7 章将 Claude Code 应用于需求文档:创建存在于你的仓库中并与实现保持同步的 PRD、用户故事和用户画像。