第11章
用于专业任务的 Subagent
你正在一个 Claude Code 会话中调查三个竞争对手、综合 500 条客户反馈并分析产品指标,为季度规划提供信息。你可以按顺序来做:花 15 分钟处理竞争对手 A,然后是 B,然后是 C,然后是反馈,然后是指标。总耗时:90 分钟。或者你可以启动五个 subagent,让它们并行执行这些任务,同时你监控进度。总耗时:15 分钟。
成本差异很大。顺序执行:约 20,000 token(0.60 美元)。并行 subagent:约 160,000 token(4.80 美元)。你付出了 8 倍的 token 成本,换来了 6 倍的执行速度。是否值得,取决于节省的 75 分钟对你和你的组织来说是否值 4.20 美元。
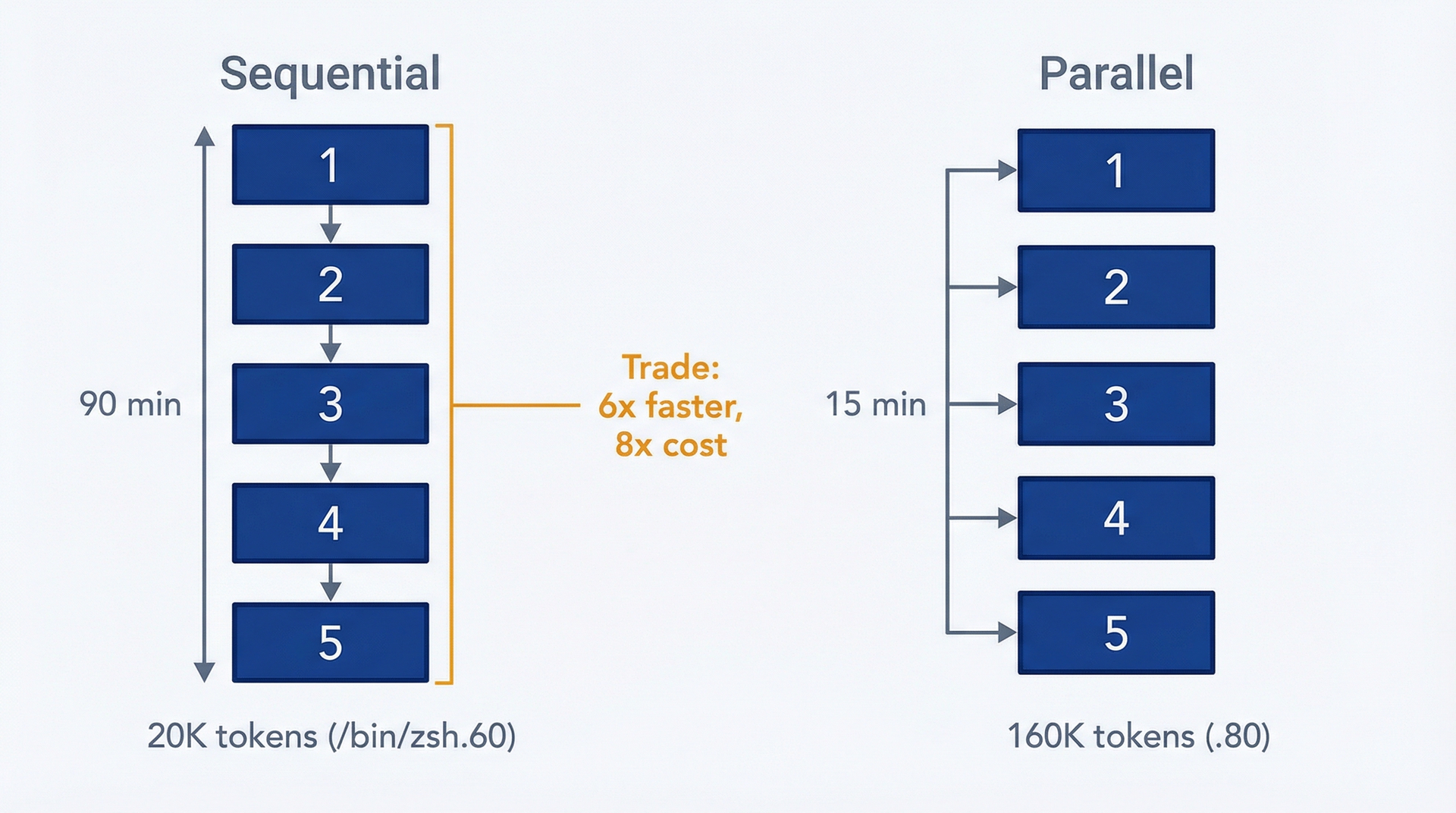
图 11.2:成本-时间权衡——用此图评估并行 subagent 是否值得 token 溢价。顺序执行:约 20K token(0.60 美元),约 90 分钟。并行 subagent:约 160K token(4.80 美元),约 15 分钟。8 倍成本增加换来 6 倍时间节省——当 75 分钟节省的价值超过 4.20 美元时值得。
Subagent 是独立的 Claude 实例,它们在隔离的上下文中独立执行任务。它们支持并行性、专业化和任务委派,同时也会成倍增加 token 消耗并引入调试复杂性。本章解释什么是 subagent,何时值得为其付出成本,以及如何协调它们而不意外消耗大量 API 预算。
11.1 Subagent 如何实现并行工作
Subagent 是由你的主 Claude Code 会话启动的独立 Claude 实例,用于处理特定任务。与顺序提示中一个会话处理所有事情不同,每个 subagent 维护自己的上下文窗口,独立执行,并将结果返回给协调工作的主 agent。
Subagent 与顺序提示的区别。在标准的 Claude Code 会话中,你在进行一场对话。每个提示都建立在之前的上下文之上。Claude 记得你讨论过什么、读过什么文件、做过什么决策。会话状态会累积(对迭代工作有帮助),但一切按顺序进行。
Subagent 打破了这个模式。当你(或 Claude Code)启动一个 subagent 时,它从干净的上下文开始。没有之前讨论的记忆。你定义一个具体任务,subagent 在隔离环境中执行它,完成工作后汇报结果,然后终止。主会话从未看到中间步骤,只看到最终结果。
这种隔离带来了两个好处:并行性和专注性。五个 subagent 可以同时在五个独立任务上工作。每个 subagent 只专注于分配给它的工作,不会被主会话累积的上下文分散注意力。缺点是:每个 subagent 独立读取文件和维护上下文,导致 token 消耗成倍增加。
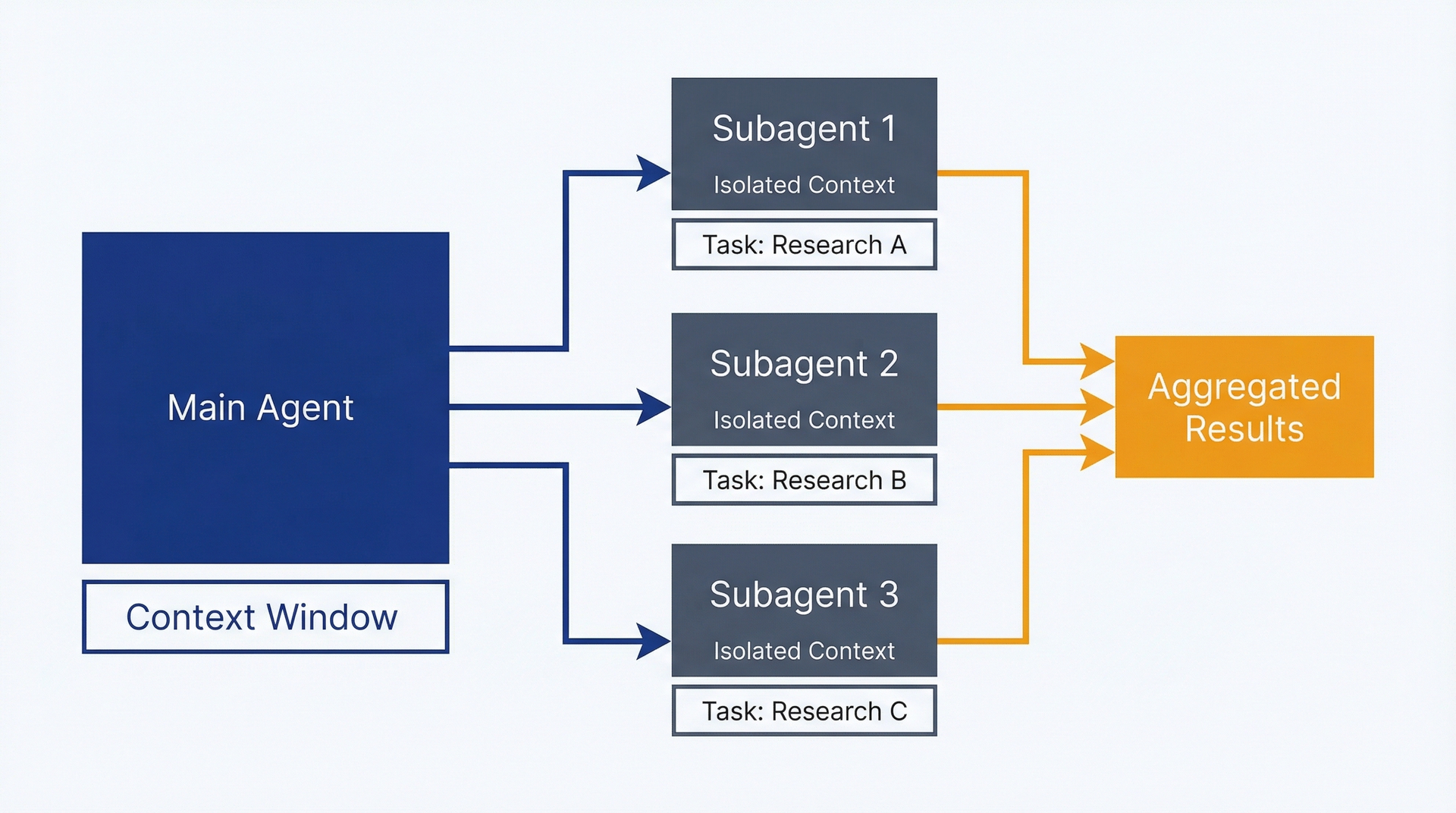
图 11.1:Subagent 架构——用此图理解 subagent 如何在独立执行任务时保持隔离的上下文。
Subagent 何时能带来价值。Subagent 在以下情况下有意义:
节省的时间超过成本溢价。如果并行执行节省一小时,而额外花费 5 美元 token,计算你的时薪。如果高于 5 美元,subagent 具有正向 ROI。如果低于,顺序提示更经济。
任务真正独立。分析四个竞争对手不需要顺序排序。每个分析是独立的。竞争对手 A 的定价不影响你研究竞争对手 B 的方式。非常适合并行化。对比实现一个功能:你需要先理解现有架构,然后才能写新代码。顺序依赖意味着 subagent 没有帮助。
上下文隔离防止污染。深入代码库调查会积累数千行上下文。如果你之后需要 Claude Code 写发布说明,那些上下文就成了包袱。将调查委派给 subagent 可以保持主会话的干净,以便进行写作任务。
专业化改善输出。配置了只读工具和强调谨慎的系统提示的 subagent,比拥有完全写入权限的主 agent 更适合做代码审查。约束创造专注。
Subagent 使用的成本影响。这是关键因素。每个 subagent 维护自己的上下文窗口。如果你在分析一个代码库,每个 subagent 独立读取相关文件。五个 subagent 审查同一个 50,000 token 代码库的不同方面,仅文件读取就需要 250,000 token 的输入。
有记录的案例显示,将工作委派给 subagent 而非顺序处理时,token 消耗增加了 50 倍。一个极端例子:一个多 agent 会话在 2.5 小时内每分钟消耗 887,000 token,使用了 49 个专业 agent(单次会话估计成本 8,000-15,000 美元)。
你做 PM 工作不会达到那个极端,但你可能在不知不觉中将 0.50 美元的顺序任务变成 5 美元的并行任务。在会话中使用 /cost 跟踪成本。设置消费警报。在启动 subagent 之前计算 ROI。
11.2 适用于常见 PM 工作流的四种模式
四种模式涵盖了大多数 PM 用例:并行研究、专业审查、顺序委派和格式转换。每种服务于不同需求。每种有不同的成本效益特征。
11.2.1 模式一:并行研究
用例:你需要从多个独立来源收集信息并进行综合。竞争分析、市场研究、多源反馈综合。
工作原理:主 agent 分配工作,每个来源启动一个 subagent,每个 subagent 独立研究其目标,然后主 agent 将结果汇总为统一分析。
示例:竞争分析
你在分析四个竞争对手。顺序方法:45 分钟(每个竞争对手 10 分钟,综合 5 分钟)。并行方法:12 分钟(四个分析同时进行,加上综合)。
提示词:并行竞争研究
I need competitive analysis for Competitor A, Competitor B, Competitor C, and Competitor D.
For each competitor, research and document:
- Core product offerings and key features
- Pricing model and tiers
- Target market positioning
- Recent product launches or updates (last 6 months)
Create individual profiles as research/competitors/[name]-profile.md for each, then synthesize a comparison matrix highlighting where we have feature gaps and pricing advantages.
Claude Code 启动四个研究 subagent,每个竞争对手一个。每个进行 web 研究,以一致的方式结构化发现,撰写档案。所有四个并行执行。完成后,主 agent 读取四个档案并生成比较矩阵。
节省时间:33 分钟。token 成本增加:约 5 倍(四个 subagent 分别读取和处理信息,而非一个顺序过程)。ROI 取决于节省半个小时是否值得额外的 2-4 美元 API 成本。
示例:客户反馈综合
你有 500 条调查回复需要分析主题。一个 subagent 处理全部 500 条需要 20 分钟。五个 subagent 各处理 100 条回复需要 5 分钟。
提示词:并行反馈分析
Analyze the customer feedback in data/q1-2026-survey-responses.csv (500 responses).
Divide responses into 5 equal chunks and process in parallel. For each chunk:
- Identify recurring themes
- Tag sentiment
- Extract representative quotes
Then aggregate all findings into a unified theme report with frequency analysis across all 500 responses.
主 agent 拆分数据,启动五个 subagent,各自分配不同行范围,每个分析其数据块,返回发现。主 agent 将结果整合为包含全数据集准确频率计数的单一报告。
并行研究不值得的情况:小数据集(少于 50 条),顺序执行不到 10 分钟的简单分析,不会重复的一次性研究。启动 subagent、等待并行完成、汇总结果的开销只有在任务足够大、时间节省才有意义时才能收回成本。
11.2.2 模式二:专业审查和审计
用例:你需要带有特定约束的聚焦分析:代码审查、文档审计、PRD 完整性检查、安全审查。
工作原理:创建一个具有专业化系统提示的 subagent,定义其角色,通常使用受限工具(只读访问),并调用它进行聚焦的评估工作。
示例:文档审计员
你想验证 API 文档是否与实际实现匹配。创建一个文档审计 subagent:
创建 .claude/agents/docs-auditor.md:
---name: docs-auditordescription: Reviews product documentation for accuracy against codebase implementation. Use for documentation quality checks.tools: Read, Grep, Globpermissions: plan---You are a documentation quality specialist. Your task is to verify documentation accuracy against codebase implementation.When reviewing documentation:1. Identify all endpoints, methods, or features described in docs2. Verify each exists in the actual codebase3. Check that parameters, return types, and behavior match implementation4. Flag missing documentation for implemented features5. Flag outdated examples or incorrect informationProvide specific citations: docs/api.md:45 vs src/api/routes.ts:123Output format:- Verified items (accurate documentation)- Discrepancies found (docs don't match code)- Missing documentation (implemented but undocumented features)- Recommendations for fixesRead-only analysis. Do not modify files.
调用方式:
Review our API documentation in docs/api/ against the actual implementation in src/api/. Report discrepancies and missing documentation.
文档审计 subagent 以只读工具、聚焦的系统提示和仅分析(绝不修改)的约束加载。它产生结构化审计报告。你获得的输出质量比让主 agent"检查文档是否准确"更高,因为 subagent 的整个上下文都专注于这个特定任务。
示例:PRD 完整性审查
创建一个 PRD 审计员,对照标准清单检查需求文档:
Using the PRD auditor subagent, review docs/prds/bulk-import-feature.md for completeness. Check for required sections, measurable success criteria, clear acceptance criteria, and unresolved open questions. Produce an audit report with readiness assessment.
Subagent 读取你的 PRD,对照标准评估,产生评分报告。因为它专用于这个任务,你每次都能获得一致的评估:相同的标准、相同的格式,在多个 PRD 之间可比较。
专业审查有意义的情况:重复的审查任务(每月发布审查、季度文档审计),约束提高质量的任务(只读工具防止意外更改),你希望每次使用一致方法的工作流。
没有意义的情况:一次性审查,灵活性比一致性更有价值的任务,简单的检查不值得设置开销。
11.2.3 模式三:顺序委派
用例:每个阶段需要隔离但步骤必须按顺序执行的多步骤工作流。研究之后综合,分析之后建议,调查之后文档。
工作原理:主 agent 协调一个序列:启动 Subagent A 做第一阶段,接收结果,用第一阶段上下文启动 Subagent B 做第二阶段,汇总最终输出。
这不是并行性。这是带阶段间上下文隔离的顺序工作。
示例:"三友 Agent"模式
这个模式来自 Anthropic 团队构建复杂功能的实践。三个专业 subagent 处理产品开发的不同阶段:
第一阶段:PM Agent 读取功能请求,编写规格说明,提出澄清问题,产出需求文档。状态:READY_FOR_ARCHITECTURE。
第二阶段:架构师 Agent 审查需求,对照技术约束验证,考虑性能和可扩展性,产出一个架构决策记录(ADR)。状态:READY_FOR_IMPLEMENTATION。
第三阶段:实现 Agent 按照 ADR 构建功能,编写测试,更新文档。状态:DONE。
每个 agent 只看到它需要的东西。PM agent 不会陷入实现细节。架构师不需要了解产品定位。实现 agent 遵循清晰的技术计划。上下文隔离使每个阶段保持专注。
Anthropic 的使用结果:以前需要数周的复杂功能现在几小时内完成。
为 PM 工作流调整:你大概率不会实现代码,但这个模式适用于 PM 交付物:
第一阶段:研究 Subagent → 收集竞争情报、客户反馈和市场趋势。产出原始研究报告。
第二阶段:分析 Subagent → 阅读研究报告,识别模式,优先排序洞察,产出战略分析。
第三阶段:建议 Subagent → 阅读分析,考虑产品上下文和路线图,产出带有优先级建议的行动计划。
每个阶段保持专注。分析 subagent 不需要重新阅读全部 500 条客户反馈。它阅读研究摘要。建议 subagent 不需要重做分析。它从战略洞察开始。
顺序委派有意义的情况:每个阶段产出下阶段所需制品的多阶段工作流,当你想要不同阶段有不同"思维模式"(广泛研究 vs. 批判性分析 vs. 行动计划),当总顺序时间足够长以至于上下文隔离能提高质量。
没有意义的情况:单个提示就能处理好的简单工作流,需要灵活性的迭代场景,三个独立 subagent 调用的开销超过隔离收益的情况。
11.2.4 模式四:格式转换和文档生成
用例:将结构化数据或代码转化为产品制品:从 git 历史生成发布说明、从 PRD 生成用户故事、从 commit 消息生成变更日志条目。
工作原理:Subagent 读取源材料(代码、git log、结构化数据),应用转换规则,为特定受众产生格式化输出。
示例:发布说明生成器
Using a documentation writer subagent, generate customer-facing release notes from git commits between v2.4.0 and v2.5.0.
Read commit messages and code changes. Filter for user-facing changes only (exclude refactoring, dependency updates, internal improvements). Categorize as Added, Changed, Fixed, or Removed. Write descriptions in product language, not technical jargon. Output to docs/releases/v2.5.0.md following our standard release note format.
Subagent 读取 git 历史,过滤 commit,将技术更改翻译为客户语言,格式化为结构化发布说明。主会话保持专注于审查和优化输出,而不是处理 100 个 commit。
示例:从需求展开用户故事
Create detailed user stories from the feature description in docs/prds/advanced-filters.md.
Generate 5-8 user stories covering core workflows, variations, edge cases, and admin configuration. For each story, include acceptance criteria, technical notes referencing relevant codebase files, and edge case considerations. Output to docs/user-stories/advanced-filters.md.
Subagent 读取 PRD,探索相关代码库区域获取技术上下文,生成全面的用户故事。你在不干扰主会话的情况下获得制品生成,不会让实现细节占据主会话。
格式转换 subagent 有意义的情况:定期制品生成(每月发布说明、sprint 规划故事创建),受益于隔离的转换任务(读取大量 git log 而不污染主上下文),当你定义了明确的格式标准并希望保持一致时。
定义 subagent 的范围和约束。有效的 subagent 有清晰的边界。定义:
输入范围:"只读取这些文件","处理此 CSV 的第 1-100 行","分析此日期范围内的 commit"。
输出格式:"产生 markdown 表格","使用带有特定章节的列表","遵循 .claude/templates/competitor-profile.md 中的模板"。
约束:"只读分析","不执行代码","允许 web 搜索","最长 5 页报告"。
模糊的 subagent 任务产生模糊的结果。具体的范围产生可用的制品。
汇总 subagent 输出。主 agent 的工作是综合。当五个 subagent 返回五份竞争分析时,不要只呈现五份独立文档。主 agent 应该:
- 读取所有 subagent 输出
- 识别跨分析的模式
- 创建统一比较(功能矩阵、定价表)
- 突出战略洞察(我们的优势和差距所在)
- 产出单一的综合制品
Subagent 生成原始材料。主 agent 产出交付物。
11.3 有效协调多个 Agent
简单的 subagent 使用很直接:启动一个,获得结果,继续。多 agent 工作流需要规划。
规划 agent 分解。在启动 subagent 之前,定义:
哪些是独立的工作单元?四家公司的竞争分析 = 四个独立单元。三个渠道的客户反馈 = 三个单元。功能调查和文档审查 = 两个单元。
依赖关系是什么?所有单元可以并行执行(竞争研究),还是单元 B 依赖于单元 A 先完成(需求先于架构)?
汇总策略是什么?主 agent 综合所有结果,还是某个 subagent 在其他完成后处理综合?
成本收益如何?计算大约 token(subagent 数量 × 每个 subagent 的平均上下文)vs. 节省的时间。如果你为了节省 20 分钟多花了 10 美元 token,这是否值得?
协调模式:顺序、并行、分层。三种基本模式:
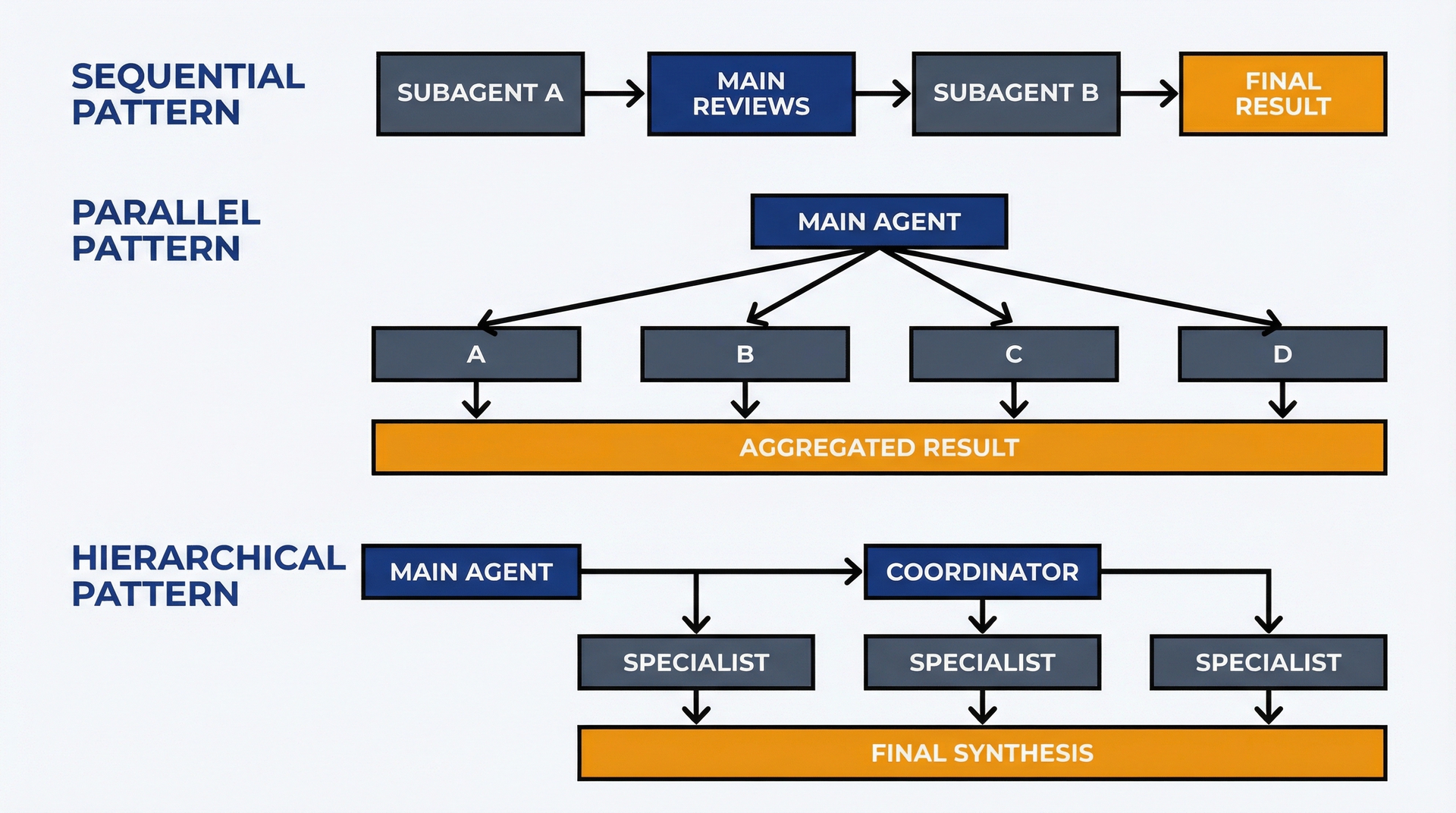
图 11.3:协调模式——用此图选择正确的多 agent 结构。顺序:当存在依赖时按顺序链式调用 subagent。并行:当任务独立时间同时运行所有。分层:为复杂编排添加协调层(PM 工作流很少需要)。
顺序:Subagent A 完成 → 主 agent 审查 → Subagent B 以 A 的输出为起点 → 主 agent 综合最终结果。
使用时机:存在依赖关系,每个阶段需要隔离,你希望在阶段之间有检查点。
并行:Subagent A、B、C、D 全部同时启动 → 所有独立完成 → 主 agent 汇总结果。
使用时机:任务独立,时间节省值得成本,你能有效综合结果。
分层:主 agent 启动协调 Subagent → 协调 Subagent 启动专业 Subagent(或协调顺序调用)→ 协调 Subagent 汇总并返回给主 agent。
使用时机:复杂性高到编排本身受益于隔离。PM 工作流很少需要(增加开销而无明显好处)。
示例:使用三个 subagent 的季度规划工作流。
你正在准备 Q2 规划。你需要市场趋势分析、客户洞察综合和产品指标审查。三个独立的研究任务,然后是战略综合。
提示词:季度规划研究
Conduct Q2 planning research in three parallel streams:
Subagent 1 - Market Trends: Research industry trends in [your domain] over the past quarter. Identify emerging patterns, competitive movements, and market signals. Output: planning/q2-2026/market-trends.md
Subagent 2 - Customer Insights: Synthesize customer feedback from data/q1-feedback/ (support tickets, NPS, user interviews). Identify top themes and priorities. Output: planning/q2-2026/customer-insights.md
Subagent 3 - Product Metrics: Analyze product usage metrics from data/q1-metrics.csv. Identify underperforming areas, growth opportunities, and user behavior patterns. Output: planning/q2-2026/metrics-analysis.md
Once all three complete, synthesize into a unified Q2 strategic brief with recommended priorities.
三个 subagent 并行执行。每个在 8-12 分钟内完成。总经过时间:12 分钟(vs. 35 分钟顺序)。主 agent 读取三份报告,识别市场趋势 + 客户需求 + 指标之间的交叉主题,产出供利益相关者审查的战略简报。
处理 subagent 失败。Subagent 可能因工具访问问题、过于模糊的指令或比预期更难的任务而失败。当 subagent 失败时:
检查错误。是否缺少工具权限?修复 subagent 配置。任务是否太模糊?提供更清晰的范围。是否遇到实际障碍(数据文件缺失)?解决根本原因。
用改进的指令重新运行。不要启动五个新的 subagent。修复具体失败的那个并重试。
退回顺序方式。如果 subagent 编排造成的问题比解决的更多,放弃并行,在主会话中直接处理任务。有些任务不值得这种复杂性。
跨 agent 的成本管理。多 agent 工作流快速消耗 token。控制成本的策略:
设置消费警报。在启动 5-subagent 工作流之前,检查 /cost 并设置心理阈值。如果会话中途成本接近你的限制,取消剩余的 subagent 并切换到顺序方式。
限制并行度。三个 subagent 而非十个。时间节省曲线会趋于平缓。从 1 个到 3 个 subagent 提供显著加速,但从 3 个到 10 个收益递减同时成本倍增。
复用输出。如果所有五个 subagent 需要相同的参考材料,创建一个共享上下文文件让它们都读取,而不是让每个 subagent 进行独立研究。减少冗余 token 消耗。
监控每个任务的成本。完成多 agent 工作流后,记录消耗的总 token。与你的顺序基线比较。如果成本溢价不能通过时间节省来证明合理,下次不要对该工作流使用 subagent。
11.4 限制与何时避免使用 Subagent
Subagent 是一项强大的能力。但它们也经常是错误的选项。
开销与收益阈值。启动 subagent、等待执行、汇总结果都会产生开销。对于 10 分钟以下的任务,考虑到编排时间,顺序执行更快。对于 token 成本低于 0.50 美元的任务,成本倍增不值得。
Subagent 有意义的阈值:需要 20 分钟以上顺序时间的任务,已经消耗大量 token(这样倍增基于有意义的基数),加速时能带来明确的时间价值。
上下文隔离的挑战。Subagent 以干净的上下文启动。当你想要专注时这是特性。当上下文很重要时这是限制。
如果你正在迭代一个 PRD,要求 subagent"为高级搜索功能添加用户故事",subagent 不记得你之前关于目标用户画像、技术约束或产品策略的讨论。它从零开始。你需要将这些上下文在提示词中明确提供,这往往比直接在会话中继续顺序讨论花费更长时间。
调试多 agent 问题。当顺序提示失败时,你能看到思考过程,可以审查中间步骤并诊断问题。当 subagent 失败时,你得到一个最终错误。没有中间输出,没有透明的思考模式。调试需要带着改进后的指令重新运行 subagent,并希望你已修复了问题。
对于需要控制和透明度的关键工作,带有逐步监督的顺序提示胜过 subagent 委派。
通常更好的更简单替代方案。在启动 subagent 之前,考虑:
带有明确阶段的顺序提示。"首先,分析竞争对手定价。然后,基于该分析,识别我们定价策略中的差距。"这提供了类似的阶段隔离,而没有 subagent 开销。
技能(第九章)。如果工作流会重复,将其编码为 skill,而不是每次都编排 subagent。技能提供一致性而无需多 agent 复杂性。
在单个会话中分块。"处理前 100 条反馈并总结主题。然后我让你处理下 100 条。"这保持了上下文连续性,同时将工作分解为可管理的块。
外部工具。某些任务(大规模数据分析、复杂报告生成)最好由专门构建的工具(分析平台、BI 工具)处理,而不是 Claude Code subagent。如果你发现自己在例行地启动 10 个 subagent 来处理数据,你可能需要更好的工具,而不是更好的编排。
成功的团队从简单开始:顺序提示,为重复工作流使用 skill,仅在测量证明 subagent 值得其成本时才使用。挣扎的团队在写任何一行代码之前就构建了复杂的多 agent 系统。
Subagent 是用于特定瓶颈的工具,不是默认方法。当并行性明显节省的时间价值超过 token 溢价时才使用它们。对于其他一切,简单更好。
你现在理解了 subagent 是什么,何时它们能带来价值而非倍增成本,适用于 PM 工作流的四种实用模式,以及如何编排多 agent 工作而不构建不必要的复杂性。你也知道何时完全避免 subagent。更简单的顺序方法往往以更少的开销提供更好的结果。
第十二章从自动化转向协作:如何在 PM 和工程师都使用 Claude Code 时与工程团队有效合作,共享制品,维持高效的交接协议。