第10章
MCP:连接到你的 PM 技术栈
你已经构建了一个从CSV文件合成客户反馈的技能。它有效。但工作流仍然涉及手动步骤:从Jira导出工单到CSV,运行技能,将洞察复制回Jira作为评论,将摘要发布到Slack。每个导出-复制-粘贴循环都会引入摩擦、延迟以及处理过时数据的风险。你正在有效地使用Claude Code,但你仍然在系统之间手动搬运数据。
MCP消除了这些交接。模型上下文协议(Model Context Protocol)将Claude Code直接连接到外部系统:Jira、Slack、Figma、数据库、分析平台。无需导出和导入,Claude Code直接在原地查询你的工具,分析数据,并将结果写回它们应该在的地方。反馈合成工作流变为:"查询Jira上个月标记为'checkout'的支持工单,合成主题,将摘要发布到#product-feedback。"一个提示,无需导出,结果出现在两个系统中。
本章解释MCP是什么以及它为什么对PM工作流重要,向你展示如何配置到常见PM工具的连接,提供了Jira、Slack、Figma和数据库的实际集成示例,并讨论了实际限制和成本影响。到本章结束时,你将理解MCP集成何时增加价值,以及何时导出-导入循环实际上更简单。
10.1 MCP如何消除导出-导入循环
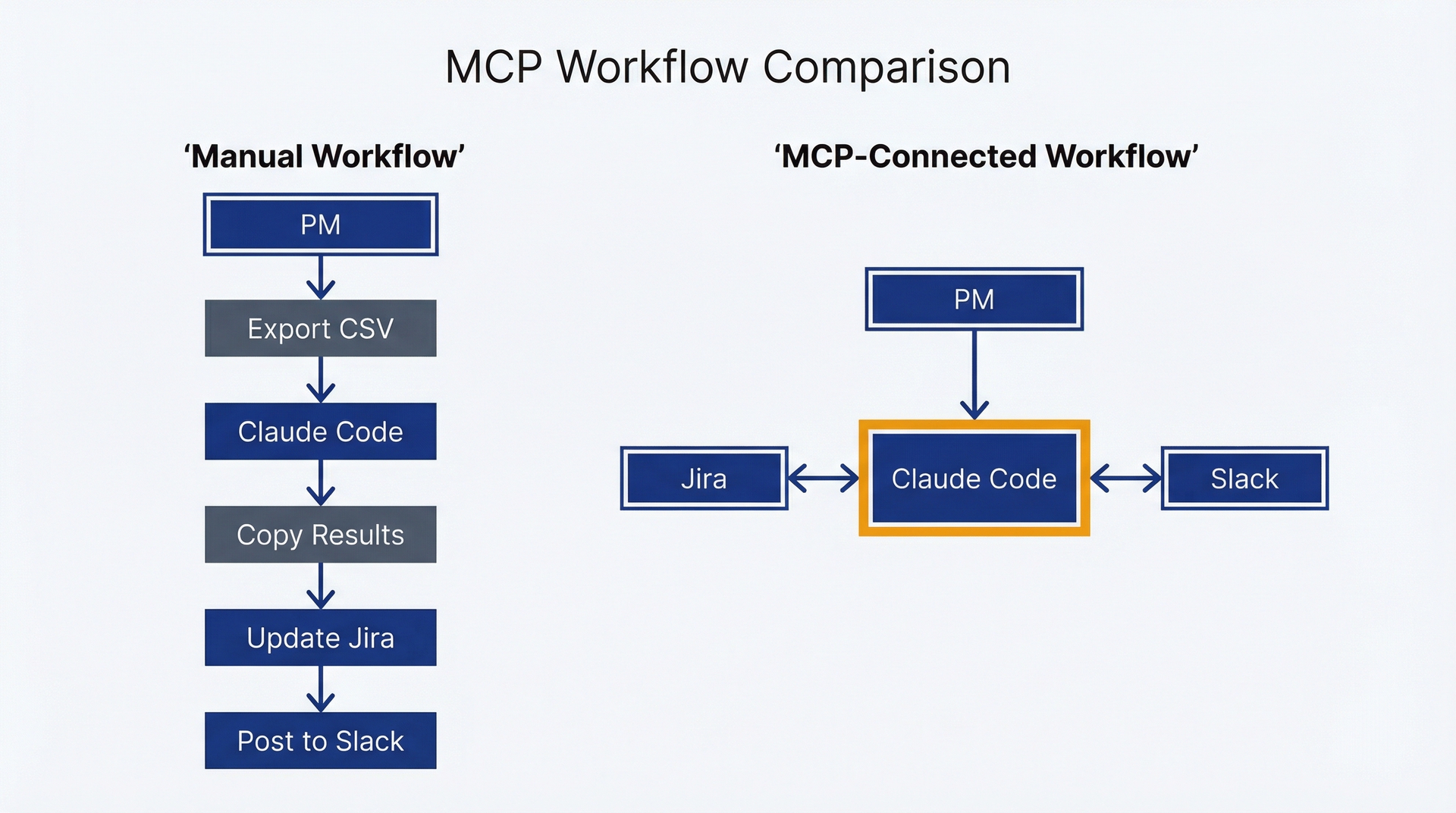
MCP通过将Claude Code直接连接到外部系统,消除了手动导出-导入循环
模型上下文协议是将AI智能体连接到外部系统的标准协议。Anthropic将MCP开发为一个开放协议(可以理解为AI集成的USB-C)。开发者不需要为每种工具组合构建自定义连接器,而是构建MCP服务器,将各自系统的能力暴露出来。一旦配置完成,Claude Code就可以在任何会话中使用这些能力。
对于PM来说,这意味着Claude Code可以读取Jira工单,发布到Slack频道,提取Figma设计规格,或者查询数据库,而你无需手动导出数据。集成在你的Claude对话中透明地发生。你描述你想要什么,Claude决定使用哪些工具,执行操作,并向你展示结果。
MCP服务器如何运作:MCP服务器是一个与Claude Code一起运行的小程序,暴露特定的工具。例如,当你配置Jira MCP服务器时,它提供诸如"search_jira_issues"、"get_issue_details"和"add_comment"等工具。在你的Claude Code会话中,当你询问关于Jira数据的问题时,Claude自动使用这些工具。你不是直接调用这些工具。你描述你的目标,Claude确定哪些MCP工具有助于完成它。
MCP服务器有两种类型。本地stdio服务器在你的机器上作为独立进程运行,通过标准输入/输出与Claude Code通信。它们适用于本地文件系统、你网络中的数据库或通过API密钥认证的云服务。远程HTTP服务器在外部基础设施上运行,通过HTTPS通信。一些SaaS提供商为其平台提供托管的MCP服务器。
认证模式:MCP服务器使用你提供的凭证向外部系统进行认证。最常见的模式:存储为环境变量的API密钥或令牌。配置Jira MCP服务器时,你需要提供Jira实例URL和API令牌。MCP服务器使用这些信息代表你发起请求。服务器在你的权限边界内运行。如果你的API令牌对Jira只有只读访问权限,那么MCP服务器也只有只读访问权限。MCP无法提升权限。
一些MCP服务器支持OAuth 2.1以获得更安全的授权流程。Claude Code提供了 /mcp命令,在需要时帮助完成OAuth认证。
安全考虑:你正在授予Claude Code使用你凭证读写外部系统的能力。这需要信任和谨慎:
- 将凭证存储为环境变量,永远不要硬编码在配置文件中
- 使用具有最小必要权限的API令牌(尽可能为只读)
- 永远不要将凭证提交到版本控制中
- 在运行会话前审计配置了哪些MCP服务器。你可能不希望在探索性代码工作中激活数据库写权限
- MCP操作会消耗外部系统的API配额和速率限制
与PM相关的可用MCP服务器:MCP生态系统正在快速增长。截至本书出版时,相关的服务器包括:
- Jira和Atlassian工具(Confluence, Jira Service Desk)
- Slack(读取频道、发布消息、搜索历史)
- Figma(访问设计规格、提取组件详情)
- GitHub(读取仓库结构、管理issues、pull requests)
- PostgreSQL、MySQL和其他数据库(建议只读查询)
- Linear、Asana、Monday.com(Jira替代方案的项目管理工具)
- 内部工具的专有服务器(如果你的组织自建)
像PulseMCP和MCP.so这样的目录列出了数千个可用服务器。大多数PM工作流只需要3-5个服务器。
MCP何时增加价值:当你重复执行涉及多个系统的工作流时,集成是有意义的。基于git历史加Jira工单生成发布说明。从Zendesk加Slack提及合成反馈。从Figma设计加现有代码模式创建用户故事。如果工作流你只做一次,手动导出-导入比配置MCP更快。如果你每月或每季度都在做,MCP在第二次运行时就开始回本。
何时跳过MCP:一次性分析。不跨系统边界的工作流。手动审查数据有助于你思考的任务(导出到CSV并在合成前阅读它可以提供有价值的上下文)。MCP自动化在数据收集是机械性的、而你希望将认知精力集中在分析和决策上而不是数据整理上时最有价值。
MCP是基础设施。你为每个工具配置一次,然后在会话中自然地调用能力。后续部分将向你展示如何设置到常见PM工具的连接并实际使用它们。
10.2 配置你的第一个集成
MCP配置在三个范围级别的JSON文件中进行。理解应该使用哪个范围对于团队协作和凭证安全非常重要。

三种配置范围控制MCP设置存放的位置以及谁可以访问它们
配置文件位置:
项目范围(团队共享):项目根目录中的.mcp.json。将其提交到版本控制。使用此仓库的每个人都会获得相同的MCP服务器配置。用于整个团队都需要的服务器:Jira、Figma、与此项目相关的Slack频道。永远不要在此文件中包含凭证。改用环境变量引用。
项目本地范围(个人,仅限此项目):项目目录中的.claude/settings.local.json。将其添加到.gitignore。用于不应共享的、特定于你工作流的MCP服务器或凭证。示例:你的个人分析数据库连接。
用户范围(个人,所有项目):主目录中的~/.claude/settings.local.json。在此配置的MCP服务器在你所有项目中都能使用。用于你在各处使用的工具:公司Slack工作区、你的Jira实例、个人数据库。
配置文件格式:
{ "mcpServers": { "jira": { "command": "npx", "args": ["@anthropic-ai/mcp-server-jira"], "env": { "JIRA_HOST": "https://yourcompany.atlassian.net", "JIRA_USER_EMAIL": "${JIRA_EMAIL}", "JIRA_API_TOKEN": "${JIRA_TOKEN}" } } }}
分解配置:
- "jira" 是服务器名称(你自行选择;使其具有描述性)
- "command" 是启动服务器的可执行文件(npx运行Node包,python用于Python服务器,node用于JavaScript文件)
- "args" 是传递给可执行文件的命令行参数(包名或文件路径)
- "env" 是服务器所需的环境变量(URL、API密钥、配置)
环境变量引用:${JIRA_TOKEN}语法告诉Claude Code在运行时用JIRA_TOKEN环境变量的值进行替换。这确保了密钥不在配置文件中。在shell配置文件(~/.bashrc、~/.zshrc)或启动Claude Code前加载的.env文件中设置环境变量:
export JIRA_EMAIL="your-email@company.com"export JIRA_TOKEN="your-jira-api-token-here"
使用绝对路径:如果你的MCP服务器是本地脚本,使用绝对文件路径:
{ "mcpServers": { "custom-tool": { "command": "node", "args": ["/home/user/projects/mcp-servers/custom.js"] } }}
像./mcp-servers/custom.js这样的相对路径可能在会话之间因工作目录改变而失败。
通过命令行添加MCP服务器:
Claude Code提供了一个命令,无需手动编辑JSON即可配置服务器:
claude mcp add --scope project jira -- npx @anthropic-ai/mcp-server-jira
这会创建或更新适当的配置文件。范围选项: - --scope project → .mcp.json(团队共享) - --scope local → 项目中的.claude/settings.local.json(个人) - --scope user → 主目录中的~/.claude/settings.local.json(个人,所有项目)
如果不指定,默认为--scope local。
测试连接:
配置MCP服务器后,重启Claude Code(配置更改需要重启)。启动一个会话并使用 /mcp命令列出已配置的服务器:
/mcp
你将看到哪些服务器已加载及其状态。如果服务器启动失败,检查: - 命令和参数是否正确 - 环境变量是否已设置并导出 - 如果使用本地脚本,文件路径是否为绝对路径 - 如果使用远程HTTP服务器,网络连接是否正常
常见故障排查:
服务器已配置但不出现:配置更改后你没有重启Claude Code。完全退出并重新启动。
认证错误:API令牌无效或已过期。独立验证凭证是否可用。用curl测试API或登录网页界面。确保令牌拥有必要的权限(读取Jira issues、发布到Slack频道等)。
静默失败:MCP服务器已启动但工具不工作。检查你的API凭证是否有权限访问你正在查询的特定资源。示例:Jira令牌可能有效,但没有访问特定项目看板的权限。
上下文窗口警告:MCP服务器消耗上下文。每个服务器仅在对话开始前的工具定义上就增加5,000-10,000个token。配置5个以上服务器可能消耗40%的上下文窗口。解决方案:只为给定项目或工作流配置实际需要的服务器。对不同任务类型使用不同的Claude Code会话(一个会话用于Jira工作,另一个用于代码调研)。
Windows上的路径问题:即使在Windows上也使用正斜杠(C:/Users/Name/server.js),或使用WSL(Windows Subsystem for Linux)以获得更可靠的MCP设置。
设置你的第一个MCP连接:Jira示例操作指南。
- 从Atlassian账户设置中获取Jira API令牌(Settings → Security → API tokens)
- 在shell中设置环境变量:
export JIRA_HOST="https://yourcompany.atlassian.net"export JIRA_EMAIL="your-email@company.com"export JIRA_TOKEN="your-api-token-here"
- 添加到shell配置文件(~/.bashrc或~/.zshrc)使其自动加载
- 将MCP配置添加到项目的.mcp.json中:
{ "mcpServers": { "jira": { "command": "npx", "args": ["@anthropic-ai/mcp-server-jira"], "env": { "JIRA_HOST": "${JIRA_HOST}", "JIRA_USER_EMAIL": "${JIRA_EMAIL}", "JIRA_API_TOKEN": "${JIRA_TOKEN}" } } }}
- 重启Claude Code
- 测试: > Query Jira for all tickets assigned to me in the current sprint
如果Claude返回工单数据,你的MCP连接就成功了。如果显示"I don't have access to Jira"或错误信息,请检查上述排查步骤。
MCP设置的时间投入:第一个服务器:15-30分钟(获取API令牌,搞清楚配置语法,调试)。第二个服务器:5-10分钟(你已经理解了模式)。第三个及以后:每个2-5分钟。当你在重复工作流中消除手动导出-导入循环时,这些设置时间就回本了。
10.3 无需离开Claude Code即可查询和更新Jira
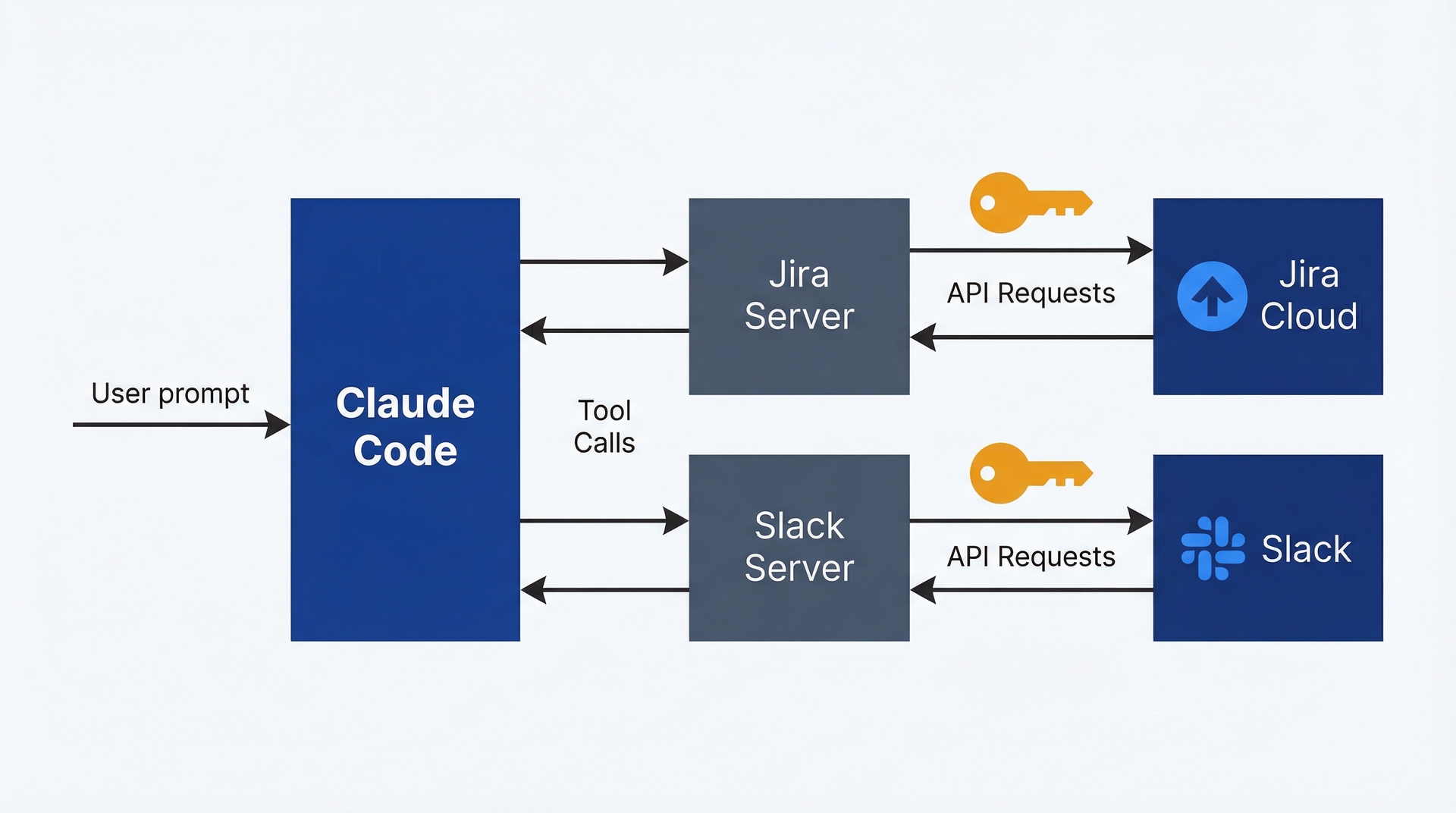
数据从你的提示流经Claude Code到达MCP服务器,后者认证并与外部服务通信
Jira MCP集成赋予Claude Code查询issues、读取工单详情、更新字段、添加评论以及分析项目数据的能力,无需导出到CSV。对于PM来说,这消除了backlog管理中最大的上下文切换税:在Jira中查看数据和在其他工具中进行分析之间来回切换。
Jira MCP服务器可用的操作: - 使用JQL(Jira查询语言)搜索issues - 获取特定工单的详细信息 - 读取评论和活动历史 - 更新issue状态、负责人、优先级、标签 - 为工单添加评论 - 创建新issues - 读取项目结构和看板配置
你不需要了解JQL语法。用自然语言描述你想要什么,Claude Code将其转换为适当的查询和API调用。
Jira连接工作流的提示模式:
工单分析与汇总:
Query Jira for all tickets in the "Ready for Grooming" state. For each ticket, summarize: title, acceptance criteria, linked dependencies, and any open questions in comments. Format as a structured list.
Claude运行Jira查询,读取每个工单的详情,分析评论线程中未解决的问题,并生成一份grooming准备文档。相比手动点击浏览工单,一个典型的10个工单的grooming环节可节省20-30分钟。
Sprint速率与指标:
Pull all completed tickets from the last three sprints. Calculate velocity (story points per sprint). Identify if velocity is trending up, down, or stable. Note any outlier sprints and check ticket comments for context on why.
无需导出到Excel并手动计算,Claude提取数据、运行分析并提供上下文。约需2分钟,而手动方式需要15-20分钟。
功能进度追踪:
Search for all tickets with the epic link "PROD-1234". Group by status (To Do, In Progress, Done). Show percentage complete and flag any tickets blocked or with unresolved comments.
适用于每周干系人更新。消除了手动审查状态看板的工作。
Bug分诊上下文:
Find all bugs reported in the last 30 days tagged "checkout flow". Categorize by root cause based on descriptions and engineering comments. Identify patterns.
帮助你发现系统性问题与孤立bug。手动分类50个bug报告需要一小时。使用MCP:5分钟。
示例:基于代码库调研自动丰富工单信息。
你使用Claude Code在plan模式下调了一个bug,在特定文件中找到了可能的原因,并希望将发现记录在Jira工单中:
I've identified that the checkout bug in ticket PROD-5678 is likely caused by null validation missing in src/services/payment.ts:142. Add a comment to PROD-5678 with this finding and link to the relevant file in our GitHub repo.
Claude读取工单确认其存在,将你的技术发现和GitHub链接构造为一条格式正确的评论,并发布到Jira。工程团队在接手该工单时会看到你的调研结果。不需要单独的Slack消息或邮件线程。
示例:Sprint评审数据收集。
你的sprint评审会议在一小时后开始。你需要准备一个关于已发布内容的摘要:
Pull all tickets completed in sprint "2026-Q1-S3". Categorize by: new features, improvements, bug fixes. For new features, extract the user-facing description. Format as bullet points suitable for a stakeholder presentation.
Claude查询Jira获取已完成的sprint,读取每个工单,根据issue类型和标签分类,提取面向客户的描述(通常在工单摘要或验收标准中),并生成可直接演示的摘要。总计时间:3分钟。手动等效操作:20-30分钟点击浏览工单和复制粘贴。
局限性和手动步骤:
复杂JQL查询:Claude能很好地处理典型查询("all bugs assigned to me"、"tickets in sprint X"),但非常复杂的JQL包含自定义字段或嵌套条件时,可能需要你提供明确的查询,或先手动运行一次。
需要审批的批量更新:如果你要更新大量工单(将50个工单改为新状态),Claude会执行此操作,但你应该先审查影响。使用plan模式预览将更新什么,然后如果更改正确,切换到acceptEdits模式。
看板配置和工作流自定义:Claude不能修改Jira看板设置、工作流转场或自定义字段配置。这些需要在Jira网页界面通过管理员访问权限完成。
速率限制:重度使用Jira API(单个会话中查询数百个工单)可能触发Atlassian的API速率限制。如果看到速率限制错误,请间隔执行查询或缩小范围。
上下文消耗:读取50个以上工单的详细信息会消耗大量token(每个工单的描述、评论和历史记录都会累积)。对于大型分析,要求Claude分批查询或边查边汇总,而不是一次性将所有内容读入上下文。
Jira MCP集成何时值得:你每周进行sprint规划,每月进行backlog审查,或每季度进行路线图更新,这些都需要拉取工单数据、分析模式并记录发现。你经常进行bug分诊,并希望用代码调研的技术上下文丰富工单。你管理跨职能的工作流,其中Jira是单一真实来源,但你需要与其他数据源(客户反馈、分析、代码变更)进行合成。
何时跳过:一次性查询,打开Jira直接看比写提示更快的情况。手动审查工单有助于你思考的工作流(自己阅读描述和评论能提供摘要所缺失的上下文)。不重度使用Jira的团队或工单数据质量差的情况。垃圾进,垃圾出:Claude无法从模糊的工单描述中提取洞察。
对于生活在backlog管理中的PM来说,Jira集成非常有价值,能够减少为分析和沟通收集和格式化工单数据的机械性开销。
10.4 自动拉取上下文和发布更新
Slack MCP集成将Claude Code连接到团队的沟通频道。对于PM来说,这意味着从讨论中拉取上下文、自动发布摘要,以及消除分析工具和团队更新之间的复制粘贴工作流。
Slack MCP可用的操作: - 从你有权限的频道读取消息历史 - 发布消息到频道(以你自己或bot身份,取决于认证方式) - 跨频道和私信搜索特定关键词或线程 - 读取线程回复和反应 - 获取频道成员列表和元数据
Slack连接工作流的提示模式:
从团队讨论中收集上下文:
Search the #customer-feedback channel for mentions of "checkout" in the last 30 days. Summarize the main issues customers reported and how frequently each appears.
Claude搜索Slack消息,识别相关讨论,分类问题,统计频率。当客户反馈分散在零散的Slack线程中,你需要在构建功能或确定修复优先级之前进行合成时很有用。
发布自动化摘要:
Query Jira for tickets completed in the last sprint, categorize by type, then post a summary to #product-updates in this format: [template you provide].
此工作流结合了Jira MCP和Slack MCP:从Jira拉取数据,分析和格式化,发布到Slack。消除了手动起草更新和复制到Slack的步骤。你的团队获得一致的sprint摘要,而你无需每次花15分钟来格式化。
交叉引用讨论与工单:
Find all Slack threads in #eng-standup where someone mentioned "performance issues" in the last 2 weeks. Check if Jira tickets exist for these issues. Report which issues don't have tickets yet.
帮助捕获那些被讨论过但从未进入backlog的事项。手动等效操作:滚动浏览Slack历史,逐一检查Jira。需要30分钟以上。使用MCP:2分钟。
示例:发布自动化摘要。
你已经配置了Slack MCP和Jira MCP。每两周,你运行这个工作流:
Pull all tickets completed in sprint [current sprint name] from Jira. For each ticket, extract the title and user-facing description. Format as a bulleted list. Post to #product-updates with this intro: "Here's what shipped in [sprint name]. Thanks to the team for another productive sprint!"
第一次运行,可能需要5分钟来优化格式和措辞。之后,你复制粘贴提示,30秒内运行完成。总计节省时间:每次sprint 15分钟 × 每年26个sprint = 每年6.5小时。
示例:从多个渠道聚合反馈。
你的公司在#customer-success、#sales-insights和#support-escalations频道中讨论客户反馈:
Search the following channels for mentions of "data export" or "export feature" in the last 90 days: #customer-success, #sales-insights, #support-escalations. Categorize feedback by: feature requests, bugs, performance complaints. Count frequency and extract representative quotes.
Claude搜索所有三个频道,聚合结果,分类,并生成包含支持性引用的合成报告。手动版本:在三个频道中滚动浏览,复制粘贴引用到文档,手工分类。需要数小时。使用MCP:3-4分钟。
合理使用和团队规范:
不要向频道刷屏。发布自动化摘要是有用的。发布每个分析结果会使频道杂乱。建立规范:什么会被自动发布vs.什么在相关时手动分享。
尊重隐私。如果Claude搜索你拥有权限的私有频道或私信,请注意分享其发现。汇总主题是可以的。未经许可引用他人的私信则不可以。
自动化使用bot令牌。如果你定期发布摘要或更新,创建一个具有描述性名称的Slack bot("Product Updates Bot"),而不是以你自己身份发布。这样可以明确区分自动消息和人工编写的消息。Bot令牌设置:Slack Admin → Create New App → Bot Token Scopes → Install to Workspace。
发布前验证。使用plan模式首先生成消息,审查它,然后切换到acceptEdits模式实际发布。自动发布带有拼写错误或不正确数据的帖子令人尴尬,也会侵蚀信任。
局限性:
跨私信搜索受限。Slack API限制搜索他人的私信,即使你是管理员。Claude只能搜索你是成员的频道和你自己的私信。
历史消息限制。免费Slack工作区有90天消息历史限制。MCP只能搜索可用历史范围内的内容。付费工作区有无限历史。
格式化复杂性。Slack使用一种特定的markdown变体进行格式化(mrkdwn)。包含表格、嵌套列表或自定义布局的复杂格式化可能无法如预期渲染。保持自动化帖子简洁:项目符号、粗体、链接。
速率限制。重度使用Slack API(快速发布大量消息、广泛搜索)可能触发速率限制。对于批量操作,请间隔执行。
上下文消耗。拉取长消息历史或多次频道搜索会快速消耗token。明确指定日期范围和关键词,以最小化拉入上下文的数据量。
Slack MCP集成何时值得:你经常合成来自多个频道的讨论,用于路线图规划或干系人更新。你运行周期性工作流(sprint摘要、每周指标发布),涉及向Slack发布格式化更新。你的团队使用Slack作为主要沟通工具,重要上下文存在于消息线程中。
何时跳过:你的团队轻度使用Slack(大部分沟通是邮件、会议或其他工具)。你很少需要合成Slack对话。偶尔手动审查就足够了。自动发布对你们的团队文化来说显得不够人性化。
当你要消除重复性发布任务,或者有价值的上下文分散在多个频道中、手动搜索很繁琐时,Slack集成才能真正发光。
10.5 以编程方式提取设计规格
Figma MCP集成使Claude Code能够访问设计文件、组件规格和设计系统token。对于PM来说,这消除了在编写规格、创建用户故事或验证实现是否符合设计时与设计师的来回沟通。
Figma MCP可用的操作: - 访问设计文件层次结构和框架结构 - 读取组件属性、变体和实例 - 提取文本样式、颜色token和间距值 - 读取自动布局属性和约束 - 下载设计资源(图片、图标) - 比较设计版本
设计连接工作流的提示模式:
提取设计规格:
Open the Figma file for "Customer Dashboard Redesign". List all top-level frames, the components used in each, and key spacing/layout properties. Format as a structured spec document.
无需安排与设计师的会议来浏览文件或手动标注截图,Claude读取Figma文件结构并生成技术规格。在向工程交接或创建用户故事时很有用。
设计到用户故事工作流:
Review the Figma file "Mobile Onboarding Flow". For each screen, identify the user actions, form fields, and navigation elements. Generate user stories in the format: "As a [user], I want to [action] so that [benefit]." Include acceptance criteria based on the design specs.
Claude分析Figma框架,将UI元素解释为用户交互,并起草包含基于设计信息的验收标准的用户故事。你负责审查和优化,但将设计转化为故事的机械性工作实现了自动化。对于5个屏幕的流程,可节省60-90分钟。
示例:根据规格验证实现。
工程团队声称他们已经实现了新dashboard。你想验证它是否与设计匹配:
Compare the implemented dashboard at [staging URL] to the Figma design in "Dashboard-Final-v3". Identify any discrepancies in: spacing, color usage, component placement, typography.
这需要将Figma MCP与截图分析或HTML检查相结合。Claude读取Figma规格,检查已实现的版本,并报告差异。然后你可以决定差异是可接受的还是需要修复。
示例:提取设计文档。
你的设计系统存在于Figma中,但工程需要书面规格:
Extract all color tokens from the "Design System" Figma file. List token names, hex values, and usage notes (if present in component descriptions). Format as a markdown table.
Claude读取设计文件,识别颜色定义,并生成参考文档。工程现在可以在不打开Figma的情况下引用颜色。在引导新工程师或维护文档时很有用。
编程式设计访问的局限性:
设计意图并不总是明确的。Figma文件包含视觉属性(间距、颜色、尺寸),但并不总是包含设计决策背后的推理。Claude可以告诉你一个按钮高度48px、padding 16px,但它不能告诉你设计师为什么选择这些值,除非在评论或描述中有记录。
复杂交互需要设计师解释。动画、微交互、条件状态可能未在静态Figma框架中完全指定。Claude可以描述设计中的可见内容,但交互行为通常需要设计师澄清。
版本与分支复杂性。具有多个分支或版本历史的大型Figma文件可能难以通过编程方式导航。要明确说明你所引用的版本或分支。
认证与访问控制。Figma MCP需要一个具有适当权限的Figma访问令牌。如果你尝试访问的文件在不同的工作区中,或你没有查看权限,MCP服务器将静默失败。
资源导出局限性。虽然Figma MCP可以下载资源,但复杂的矢量图形或设计元素可能无法在所有用例中干净地导出。对于生产级的资源交接,设计师仍应使用适当设置导出资源。
Figma MCP集成何时值得:你经常将设计转化为用户故事或规格。你的团队使用Figma作为产品规格的单一真实来源,而你需要在编写文档时引用设计细节。你正在管理一个设计系统,并且需要保持工程文档与Figma定义同步。
何时跳过:你的团队不使用Figma,或设计文件在PM工作中很少被引用。你更喜欢协作式的设计评审会议,一起浏览文件(自动化会消除有价值的讨论)。设计文件经常变化,编程式提取很快就会过时。
当设计规格足够稳定、可以进行编程引用,并且你有明确的工作流(设计 → 用户故事、设计 → 实现验证)能够从自动化提取中受益时,Figma集成是有价值的。
10.6 无需编写SQL即可拉取指标
将Claude Code直接连接到数据库或分析平台,使你可以拉取指标、查询客户数据和分析趋势,而无需导出到CSV或构建自定义仪表板。对于经常需要"快速拉取数据"以提供决策依据的PM来说,这消除了一个主要瓶颈。
可用的数据库MCP服务器:
- PostgreSQL
- MySQL / MariaDB
- SQLite
- MongoDB
- Redis(用于缓存或会话数据)
- 云数据仓库(Snowflake、BigQuery,通过自定义MCP服务器)
安全要求与访问控制:
使用只读数据库副本。永远不要将Claude Code连接到生产写数据库。如果你的数据库崩溃,你不希望是因为Claude执行了一个锁定表或消耗资源的查询。请使用只读副本或分析数据库。
最小权限原则。创建一个数据库用户,权限为只读,范围限定到仅分析所需的表和schema。不要使用管理员凭证。
网络访问。如果你的数据库在VPN或防火墙后面,Claude Code需要网络访问权限。对于云数据库,将你的IP加入白名单或使用SSH隧道。
数据隐私。如果你正在查询客户数据,注意PII(个人可识别信息)。在可能的情况下,在查询中进行聚合和匿名化处理。除非你有合法需求和适当的数据处理实践,否则不要要求Claude拉取客户邮件列表或个人信息。
连接到只读数据库副本:
PostgreSQL配置示例:
{ "mcpServers": { "analytics-db": { "command": "npx", "args": ["@modelcontextprotocol/server-postgres"], "env": { "DATABASE_URL": "${ANALYTICS_DB_URL}" } } }}
设置环境变量:
export ANALYTICS_DB_URL="postgresql://readonly_user:password@analytics-replica.company.com:5432/analytics"
这会连接到你分析副本数据库上的只读用户账户。
查询生成与执行:
你不需要编写SQL。用自然语言描述你想要什么,Claude生成查询,通过MCP服务器执行它,并分析结果:
Query the analytics database for the number of new user signups per week for the last 12 weeks. Show the trend (increasing, decreasing, or stable).
Claude编写SQL查询,执行它,检索结果,并计算趋势。你既能看到查询(为了透明性),也能看到分析结果。
示例:拉取指标进行分析。
你正在准备季度业务review,需要当前的产品指标:
From the analytics database, pull the following metrics for Q4 2025:
- Total active users (monthly)
- Average session duration
- Feature adoption rate for "export to PDF"
- Conversion rate from free to paid
Format as a summary table with month-over-month changes.
Claude生成必要的SQL查询,执行它们,聚合结果,计算变化,并生成格式化的表格。你将其复制到QBR演示文稿中。与手动编写SQL查询或等待分析团队相比,节省30-45分钟。
示例:客户队列分析。
你想按注册队列了解留存率:
Query the users table for all customers who signed up in January 2025. Calculate what percentage are still active (logged in within last 30 days) as of today. Repeat for February, March, April, May, June cohorts. Show as a cohort retention table.
Claude编写队列分析SQL,执行它,并格式化结果。这种类型的查询手动编写很繁琐,但用自然语言描述很简单。
何时使用vs.专用分析工具:
在以下情况使用Claude Code + 数据库MCP:
- 你需要现有仪表板中没有的临时分析
- 问题是探索性的,你会迭代查询
- 你想将数据库指标与其他数据源(Jira工单、Slack讨论、客户反馈)结合
- 你的分析团队积压了大量请求,而你今天就需要答案
在以下情况使用专用分析工具(Looker、Tableau、Metabase):
- 该指标需要定期跟踪,应该作为仪表板
- 多个干系人需要访问相同的视图
- 你需要复杂的可视化(图表、图形)
- 查询运行缓慢,应由分析工程师优化
数据库MCP是为了PM的敏捷性和临时性问题。它不是对正式分析基础设施的替代,而是一种补充,用于当你需要比仪表板团队能构建它们更快的速度得到答案时。
数据库查询的token成本:
数据库查询本身快速且便宜(MCP服务器执行它们,Claude不会逐字节处理SQL)。但查询结果在加载到上下文时会消耗token。一个返回1,000行、10列的查询可能消耗20,000-50,000个token,具体取决于内容密度。
优化:要求Claude在查询中进行聚合或过滤。不要写:
Pull all user records from the last 90 days and analyze churn patterns.
这可能会返回100,000行并耗尽你的上下文窗口,而使用:
Write a SQL query to analyze churn patterns for users from the last 90 days. Aggregate by week and return only the weekly churn counts and percentages.
这会将结果集保持得很小(13周对应13行),消耗最少的token,同时仍提供你需要的分析。
局限性:
性能与超时。长时间运行的查询(30秒以上)可能超时。如果你的查询命中了一个没有索引的大表,可能会失败。保持查询聚焦,让数据库查询优化原则引导你。
数据新鲜度。如果你查询的是每小时同步一次的副本,你的数据可能滞后一小时。对于实时指标,你需要一个实时连接或更新更频繁的副本。
复杂连接和schema知识。Claude可以为常见模式生成SQL,但非常复杂的跨多表连接,或需要深入schema知识的查询,可能产生不正确的SQL。在假设结果准确之前要审查查询,特别是在刚开始使用时。
schema变更。如果你的数据库schema发生变化(表被重命名、列被添加/删除),Claude的查询可能会中断。你需要更新描述或提供当前的schema信息。
对于需要快速数据访问并且能够审查SQL查询正确性的PM来说,数据库集成非常强大。它不是正规分析工程的替代品,但它填补了"我现在就需要答案"和"让我们构建一个仪表板"之间的空白。
你现在理解了MCP是什么,如何配置到常见PM工具(Jira、Slack、Figma、数据库)的连接,以及集成何时增加价值vs.手动工作流何时更简单。MCP消除了重复工作流的导出-导入循环,但也引入了配置复杂性和上下文消耗的权衡。
第11章将介绍subagent:Claude Code如何生成专门化实例来进行并行工作或专注任务,以及这一能力何时对PM工作流很重要。