第4章
调查 Bug 与用户问题
4.1 无需工程协助即可进行的Triage
一张支持工单到了:"我的付款没有通过,但被扣款了。"工程团队正在为发版打包。客户正在向你的VP升级投诉。你需要进行triage:这到底是个真实的bug、用户操作错误,还是边缘情况?你需要判断影响范围:是只影响这一个客户,还是系统性问题?你需要了解上下文:工程团队在开始调查之前应该知道什么?
传统PM的响应方式:把工单转发给工程团队,附上一句"可以看一下吗?",然后就是等待。工程师切换上下文、调查问题、然后汇报。如果是用户操作错误,你就为一个毫无意义的事情打断了冲刺。如果是真实的bug,你除了原始的客户投诉外没提供任何额外上下文。不管哪种情况,反馈循环都要几个小时甚至几天。
替代方案:打开Claude Code,自己调查支付流程,识别可能导致该行为的代码路径,然后在分配给工程团队之前整理好发现。总用时:20分钟。工程团队收到的是附带文件引用和假设的聚焦式调查。他们只需要确认和修复,无需经历发现阶段。
bug调查是Claude Code能够提供立竿见影、可衡量的PM价值的地方。你不是在修复bug——那是工程团队的工作。你是在收集上下文、形成假设并减少来回沟通。好的triage每周能节省数小时的工程时间。糟糕的triage则因为不完整且需要追问的交接而浪费所有人的时间。
你在bug调查中的角色:
是真实的bug还是用户操作错误?许多所谓的"bug"其实是用户不理解预期行为、配置错误或会话过期。调查往往会揭示系统运行正常而用户产生了误解。发现这一点就能避免工程团队浪费一个不必要的调查周期。
影响范围和严重程度如何?只影响一个客户还是很多客户?涉及数据丢失还是只是外观问题?间歇性的还是可复现的?这些上下文决定了优先级。Claude Code能帮助你理解什么条件会触发该问题,以及这些条件的波及范围可能有多广。
工程团队需要什么上下文?文件位置、相关的代码路径、类似的过往问题、你已识别的复现步骤。你提供的上下文越多,工程团队解决问题的速度就越快。未经调查的原始客户投诉只会制造更多工作,而非更少。
你不是被期望去修复bug,而是被期望进行智能化的triage、提供有用的上下文,并避免将工程时间浪费在那些你本可以自行解决或澄清的问题上。Claude Code让你无需阅读代码就能做到这一点。
4.2 将用户投诉转化为可测试的查询
用户的语言和代码的语言不匹配。客户描述的是症状:"页面坏了。""我的折扣没生效。""我登录不了。"工程师需要的是具体信息:错误消息、复现步骤、环境详情、数据状态。你的工作就是翻译。
将用户语言转化为技术查询。从模糊中提取具体信息。一份报告说"结账页面坏了"。具体是哪里坏了?他们看到了错误消息吗?他们当时正在尝试做什么?实际发生了什么,而不是他们预期应该发生什么?
如果你能访问原始的支持工单,提取这些细节。如果不能,就做合理的假设并在调查中注明。然后让Claude Code帮助识别什么可能导致所描述的症状。
以plan模式启动Claude Code:
claude --permission-mode plan
Prompt:症状翻译
一位用户反馈:"[粘贴确切的投诉内容]"
哪些代码路径可能导致这种行为?请识别:
- 哪些文件处理此功能
- 每一步可能出现什么问题
- 用户可能遇到哪些错误状态
- 什么数据或条件可能触发此问题
举个例子,针对"我的折扣码明明有效却没有被应用":
一位用户反馈:"我的折扣码明明有效却没有被应用。我正确输入了,它只显示'invalid code'。"
在折扣或结账流程中,哪些代码路径可能导致这种行为?识别潜在的故障点:代码验证逻辑、过期检查、使用次数限制、购物车要求、大小写敏感性。
Claude Code读取相关文件并返回类似这样的内容:"折扣验证在src/services/discount-validator.js中处理。代码检查:(1) 代码在数据库中存在,(2) 基于valid_until日期未过期,(3) 使用次数低于max_uses,(4) 购物车满足minimum_cart_value。任一检查为false时返回'invalid code'且没有具体的提示信息。大小写敏感性已强制执行,所以'SUMMER20'和'summer20'是不同的代码。"
你现在有了一个可测试的假设。那个通用的"invalid code"消息掩盖了实际的失败原因。客户的代码可能已过期、超出使用限制,或者输入的大小写不对。所有这些在用户看来都像是有效的代码,但都会被系统拒绝。
识别相关的日志模式和错误消息。如果你的应用记录了错误,问Claude Code存在什么日志:
折扣码验证有哪些日志或错误追踪?我在哪里可以找到折扣应用失败的日志?
Claude Code会识别日志语句、错误处理器以及错误详情被捕获的位置。你会了解到失败的验证带有原因代码被记录到logs/discount-errors.log,或者失败根本没有被记录。日志的缺失本身就是改进调试的有用信息。
区分前端 vs. 后端 vs. 数据层面的问题。并非所有bug都是代码层面的bug。有些是配置问题、数据质量问题或环境不匹配。
Prompt:问题层面识别
一位用户经历了[症状]。请帮我判断这最可能是以下哪一类:
- 前端问题(显示、客户端逻辑、浏览器兼容性)
- 后端问题(服务端逻辑、API响应、业务规则)
- 数据问题(数据库状态、用户记录问题、缺失数据)
- 配置问题(环境设置、功能开关、第三方服务)
什么证据能够区分这些类别?
对于折扣码的例子,Claude Code可能会解释:"如果代码没有被正确发送,则是前端问题(检查网络请求)。如果验证逻辑存在bug,则是后端问题(我们审查过的代码)。如果数据库中折扣码记录格式错误或缺失,则是数据问题。如果该环境中折扣服务被禁用或Stripe未正常处理,则是配置问题。"
这会缩小你的调查范围。如果客户说"我输入了代码,立刻收到了错误提示",那很可能是前端或后端验证的问题。如果他们说"好像生效了,但折扣没有显示在我的收据上",那很可能是后续的处理步骤出了问题,也许是后端计算或数据持久化方面的问题。
复现调查的成本和时间。一次典型的复现调查会话(翻译用户投诉、识别相关代码、缩小到可能的原因)需要10-20分钟,消耗15,000-40,000 token。API用户的成本:$0.08-0.20。订阅用户的成本:已包含在内。与之对比的替代方案是:一张模糊的工单被工程团队退回要求更多信息,使解决时间增加一天。
4.3 从用户反馈到工程交接,30分钟内完成
结构化的调查胜过临时性的探索。遵循以下工作流,从用户反馈过渡到可执行的工程交接。
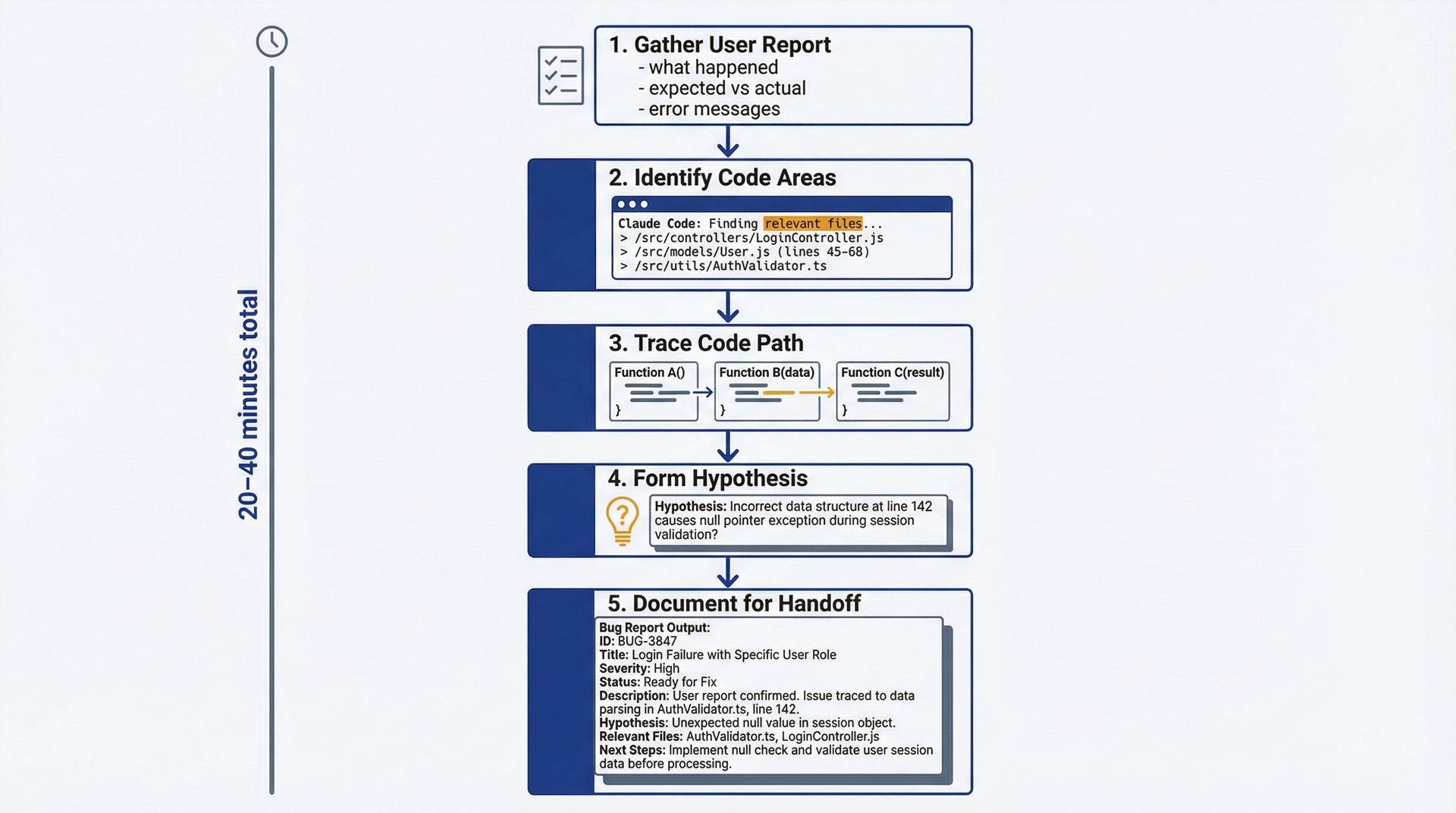
图 4.1:Bug调查工作流——用于组织你的bug triage流程。五个步骤:1) 收集用户反馈详情(5分钟),2) 利用Claude Code识别相关代码区域,3) 追踪代码路径,4) 形成可测试的假设,5) 记录发现以交接给工程团队。总用时:20-40分钟。
第1步:收集用户反馈详情。在接触Claude Code之前,从反馈中提取你能提取的一切信息:
- 用户试图做什么
- 他们预期会发生什么
- 实际发生了什么
- 他们看到的任何错误消息(尽可能获取确切文本)
- 发生的时间
- 他们使用的浏览器/设备/环境
- 他们能否复现,还是只是一次性发生的
这需要五分钟,并且能够防止在无效的调查循环上浪费时间。如果因为不知道用户使用的是过时的浏览器就去调查"登录有问题",你追踪的代码实际上运行正确。
第2步:让Claude Code识别相关代码区域。在收集了上下文之后,开始你的调查会话:
claude --permission-mode plan
Prompt:代码区域识别
我正在调查一个用户反馈的问题:[一句话摘要]
上下文:
- 用户操作:[他们当时在做什么]
- 预期:[本应该发生什么]
- 实际:[实际发生了什么]
- 错误消息(如有):[确切文本]
请识别可能涉及的代码区域。展示给我:
- 入口点(该用户操作在代码中的起始位置)
- 执行路径中的关键文件
- 错误在哪里被捕获和处理
- 哪里可能会失败
Claude Code会绘制出相关的代码区域。对于支付失败的调查,你可能会得到:"用户点击支付 → CheckoutButton.tsx分发action → checkout.service.js验证购物车 → payment-processor.js调用Stripe API → 响应在payment-response-handler.js中处理 → 订单在order.service.js中创建。每一步都有错误处理;Stripe集成在stripe-errors.js中有特定的错误映射。"
第3步:请求对可疑代码路径进行解释。一旦知道了该看哪里,就进一步问细节:
请逐步解释payment-processor.js做了什么。重点关注:
- 什么可能导致它失败
- 当Stripe返回错误时会发生什么
- 用户看到的是具体的错误消息还是通用消息
- 支付失败时记录了什么日志
Claude Code读取文件并翻译:"该处理器验证支付方式存在,检查购物车总额与扣款金额一致,调用Stripe的charge API,然后处理响应。Stripe错误被捕获并映射。'card_declined'变为'Your card was declined','insufficient_funds'出于隐私原因也显示相同消息。所有失败都将Stripe错误代码记录到payments.log,但向用户显示通用消息。如果Stripe返回成功但之后的订单创建失败,存在一个对账队列来捕获这些孤立的支付。"
现在你开始有进展了。用户说他们被扣款了但支付"没有通过"。这可能意味着:Stripe成功扣款,但订单创建失败,触发对账队列。客户被扣了款却看到了错误,因为失败发生在支付之后。
第4步:形成假设。基于你的调查,形成一个可测试的假设:
"用户很可能已被Stripe成功扣款,但随后的订单创建失败了。这可能是数据库错误、超时或验证问题。系统在支付成功的情况下显示了通用错误消息。对账队列中应该有这个案例。如果是这样,该笔支付存在于Stripe中,用户需要手动创建订单或退款。"
这是可执行的。工程团队可以检查对账队列,在Stripe中验证,并解决这个具体案例,同时调查订单创建失败的原因。
第5步:为工程团队整理调查发现记录。整理你的调查:
Prompt:调查摘要
总结我对这个bug的调查以供交接给工程团队。包含:
- 用户反馈了什么
- 我调查了什么
- 我审查了哪些文件和代码区域
- 我对根本原因的假设
- 给工程团队的具体问题
- 建议的后续步骤
Claude Code生成的摘要可以粘贴到Jira、Slack或邮件中。附上它找到的文件引用、你的假设,以及工程团队应该验证的内容。这种交接尊重了工程团队的时间,他们不需要从零开始。
完整工作流耗时:中等复杂度的bug约20-40分钟。Token消耗:30,000-80,000 token。对于API用户,成本为$0.15-0.40。一次能够为工程团队节省一小时发现时间的彻底调查,其价值远超此数。
4.4 在工程团队之前识别Bug类型
某些bug类别在不同产品中反复出现。识别这些模式能帮助你更快地调查问题,并与工程团队更精确地沟通。你不是在调试代码,而是在将症状与已知的问题类型进行模式匹配。
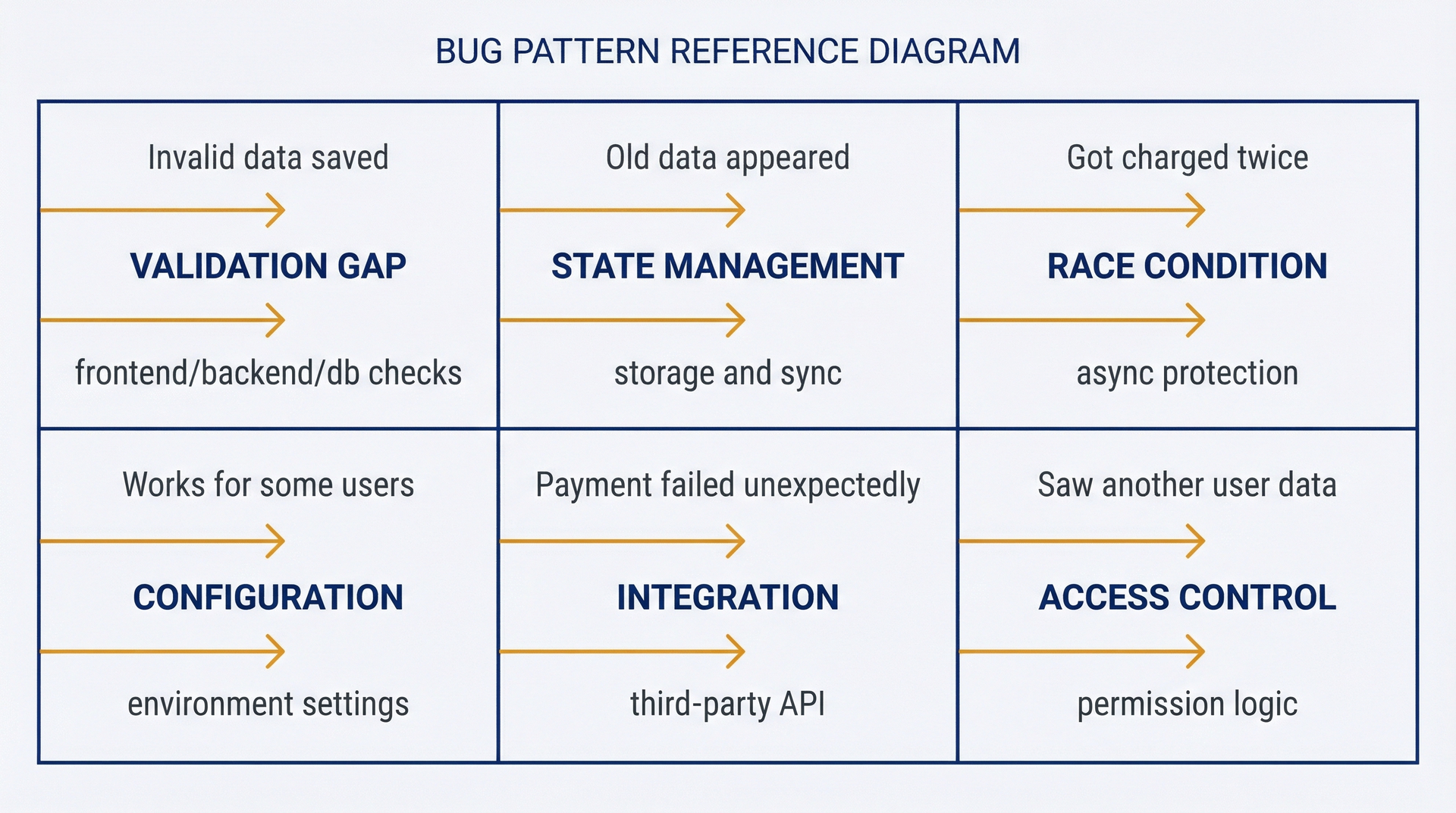
图 4.2:Bug模式参考——用于快速分类用户反馈的问题。六种常见模式:验证缺陷(无效数据被保存)、状态管理(旧数据显示出来)、竞态条件(被重复扣款)、配置不匹配(对某些用户有效)、集成失败(支付意外失败)、访问控制(看到了其他用户的数据)。将症状与模式匹配以加快调查速度。
数据验证缺陷。不应该通过的用户输入却通过了。表单接受无效的邮箱地址。价格字段允许负数。必填字段可以被绕过。这些bug源于不完整或前后端不一致的验证逻辑。
Prompt:验证调查
在这个功能中,[字段/输入]是如何被验证的?请检查:
- 前端验证(表单在提交前检查什么)
- 后端验证(服务器在接收数据时检查什么)
- 数据库约束(schema强制执行什么)
是否存在无效数据可能通过验证的漏洞?
Claude Code比较每一层的验证。你可能会发现前端检查了邮箱格式,但后端没有,允许API调用绕过前端验证。这就是你的假设:症状(数据库中的无效数据)匹配了模式(验证缺陷)。
状态管理问题。UI显示过时数据。导航后更改没有持久保存。用户看到了别人的数据。这些bug涉及应用如何追踪和同步状态。
Prompt:状态调查
[功能]的状态是如何管理的?请追踪:
- 状态存储在哪里(本地、会话、服务器)
- 用户操作后状态如何更新
- 状态何时被刷新或同步
- 什么可能导致状态过时或不正确
状态bug很微妙,因为代码"能运行",只是没有正确地协调好。Claude Code可以发现:用户资料被缓存到本地,但更新发生在服务端,而缓存在更新时没有被无效化。症状匹配了模式。
竞态条件(概念性识别)。两个不应该同时发生的操作发生了冲突。用户双击按钮被重复扣款。并发编辑互相覆盖。这些是时序bug,需要特定条件才会触发。
虽然无法通过静态分析来调试竞态条件,但可以识别其潜在的易发性:
[功能]可能存在竞态条件吗?请查找:
- 触发异步操作的用户操作
- 没有点击保护机制的按钮或表单
- 对共享资源的并发访问
- 应该是原子操作但实际上不是的操作
Claude Code可能会发现:"结账按钮触发了异步支付处理,但在点击时没有禁用。多次点击可能会发起多次支付调用。Stripe调用中没有幂等性key来防止重复扣款。"
在缺乏运行时测试的情况下,你无法确认这就是根本原因,但你已经识别出了这个模式。你的bug报告写道:"怀疑是竞态条件。结账按钮缺少点击保护,支付调用可能不具备幂等性。用户可能双击了。"
配置不匹配。功能在某些环境中有效但在其他环境中无效。暂存环境的行为与生产环境不同。某些用户体验到问题而其他人没有。这些bug源于环境特定的设置。
Prompt:配置调查
什么配置控制着[功能]?请展示:
- 影响行为的环境变量
- 功能开关或切换标志
- 不同环境之间有差异的设置
- 用户特定或账户特定的设置
你会了解到该功能使用了一个第三方API,该API在不同环境中具有不同的凭证,而生产环境的凭证已过期。或者一个功能开关只为beta用户启用了该功能,而受影响的用户不在beta组中。
第三方集成失败。外部服务返回错误、超时或行为异常。支付处理器拒绝有效的银行卡。邮件服务静默失败。分析事件未出现。
Prompt:集成调查
这个功能如何与[第三方服务]集成?请展示:
- API调用在哪里发起
- 如何处理来自该服务的错误
- 失败是否被记录以及如何记录
- 当集成失败时用户看到什么
Claude Code追踪集成细节。你会发现Stripe错误被记录了,但用户看到的是通用的"出了点问题"消息。或者邮件发送是fire-and-forget且没有错误处理,所以失败会静默消失。
权限和访问控制方面的bug。用户可以访问他们不应该访问的内容。用户无法访问他们应该访问的内容。仅限管理员的功能出现在普通用户面前。
Prompt:访问控制调查
[功能]的权限是如何被检查的?请展示:
- 访问控制逻辑在哪里
- 什么条件授予访问权限
- 系统如何确定用户角色/权限
- 访问被拒绝时会发生什么
你会发现权限检查只发生在前端,因此用户可以通过直接的API调用来绕过它。或者权限检查中有一个本应是AND的OR。症状匹配了模式:访问控制逻辑有缺陷。
模式参考表:
用户反馈…可能的模式调查重点"无效数据被保存了"验证缺陷比较前端/后端/数据库的验证"旧数据显示出来"/ "更改没有保存"状态管理追踪状态存储、更新、同步"被扣了两次款"竞态条件查找没有保护机制的异步操作"别人能用但我用不了"配置不匹配检查用户特定或环境特定的设置"支付失败,但按理说应该成功"第三方集成追踪外部API调用和错误处理"我能看到其他用户的数据"访问控制审查权限逻辑和执行情况
识别模式能将调查速度从"可能是什么问题"提升到"是不是这个具体的问题?"。你不是在调试,而是在对症状进行分类,以便更精确地与工程团队沟通。
4.5 工程团队真正愿意看的Bug报告
你的调查只有在有效沟通的前提下才有价值。工程团队需要具体信息才能快速行动。一份结构良好且附带调查上下文的bug报告能将解决时间从天缩短到小时。
工程团队需要什么:
复现步骤。他们如何触发该问题?从起始状态到出现错误的编号步骤。"1. 创建新用户账户。2. 将商品加入购物车。3. 使用折扣码'SUMMER20'。4. 点击结账。5. 观察错误消息。"如果你无法复现,就如实说明,并描述用户反馈了什么。
环境。这发生在哪里?生产环境/暂存环境/开发环境。浏览器及版本。设备类型。用户账户类型(新用户 vs. 现有用户,免费 vs. 付费)。任何可能影响行为的因素。
预期与实际行为的对比。应该发生什么?实际发生了什么?要具体。"预期:折扣应用且购物车总额更新。实际:错误消息'Invalid code'出现,尽管该代码在管理面板中是有效的。"
错误消息。确切的文本,而非改写后的。错误代码(如果可见的话)。用户提供的截图。如果你有权限访问,附上日志条目。
利用Claude Code的输出丰富报告。你的调查生成了文件引用、代码解释和假设,把它们包含进去:
Prompt:Bug报告生成
基于我的调查,生成一份bug报告,包含:
- 问题摘要
- 复现步骤(基于我的理解)
- 环境详情
- 技术上下文(涉及的文件、代码路径)
- 我对根本原因的假设
- 给工程团队的建议调查点
- 我无法回答的待解决问题
Claude Code将你的会话综合为结构化的输出。你仍然需要审阅和编辑(添加它未看到的用户反馈细节,删除你没有把握的推测),但它能创建一个扎实的初始草稿。
包含相关的代码片段而不假装自己是专家。你发现discount-validator.js:45-78中的折扣验证可能导致此问题。引用它而不假装你理解每一行代码:
"我调查了折扣验证流程,在discount-validator.js:45-78找到了相关逻辑。根据我的阅读,代码检查了[列出条件]。用户的场景可能在[具体条件]处失败,因为[假设]。我不确定这就是根本原因,但这是我会首先查看的地方。"
这提供了有用的上下文而不越界。你在说"我查看了这里,这看起来相关",而不是"我确切知道问题出在哪里"。工程师会欣赏这种上下文,并不会反感这种恰如其分的谦逊。
模板:经过PM调查的bug报告:
Summary[一句话描述该问题]## User Report- 用户操作:[他们试图做什么]- 预期:[本应发生什么]- 实际:[实际发生了什么]- 错误消息:[如有,提供确切文本]## Environment- 环境:生产 / 暂存 / 等。- 用户类型:[账户特征]- 浏览器/设备:[如已知]- 时间:[相关日期/时间]## Reproduction Steps1. [步骤1]2. [步骤2]3. [观察:具体行为](注明复现是由PM确认的还是基于用户反馈推断的)## PM Investigation### Files Reviewed- path/to/file.js - [该文件处理什么]- path/to/other.js - [该文件处理什么]### Findings[你从阅读代码中学到了什么。流程是什么样的。哪里可能出问题。]### Hypothesis[你对根本原因的最佳猜测,以假设而非结论的形式表述]### Open Questions- [你无法从代码中确定的事情]- [需要运行时验证的事情]## Suggested Next Steps- [ ] 在日志中验证[具体事物]- [ ] 检查[具体状态或数据]- [ ] 测试[具体场景]## Priority Assessment[你的建议:P1/P2/P3及其原因。影响范围评估——影响一个用户还是多个?]
不要包含的内容。不要包含大量你看不懂的代码堆砌。不要把假设当作结论来陈述。不要将责任归咎于特定的commit或工程师。不要对修复方案"有多显而易见"发表评论。坚持观察、假设和问题。
这样一份bug报告能将模糊的"某东西坏了"转变为可执行的工程工作。你已经完成了调查的前30%,工程团队完成剩下的70%,但剩下的工作是聚焦而高效的,而不是从零开始。
4.6 知道何时停下来
调查的回报是递减的。在某个节点之后,进一步的PM调查会浪费你的时间,并延迟工程团队的介入。要认清这些边界。
你已经收集到足够上下文的信号:
你能解释清楚流程。你理解了功能做什么、数据如何在其中移动以及在代码中的哪个位置发生。即使你不能流利地阅读代码,你也能描述从用户操作到结果的路径。
你有了可测试的假设。你已经形成了关于问题可能出在哪里的合理猜测。"折扣验证失败,因为代码区分大小写,而用户输入了小写。""支付成功但订单创建因数据库超时而失败。"假设不一定是正确的——它们给工程团队一个起点。
你已经识别出相关文件。你可以指向问题可能所在的具体文件路径。这为工程团队省去了探索阶段。
你知道自己不知道什么。你的调查遇到了限制:你看不到的运行时行为、你无法验证的数据状态、你无法访问的配置。记录这些空白有助于工程团队聚焦他们的调查。
如果这四条标准都已达到,那么你已经掌握了足够的信息。写出bug报告,然后交接。
你已力不从心的信号:
代码太复杂,无法总结。如果Claude Code的解释即使变成了通俗语言仍然难以理解,那么逻辑可能超出了调查能厘清的范畴。交接给工程团队。
你在原地打转。同样的问题你已经用了三种不同的问法问了三次,没有得到新的信息。这个问题需要运行时调试,而不是代码阅读。
涉及安全敏感性。认证、授权、数据访问、加密:任何处理不当都会产生严重后果的领域。你的假设可能危险地错误。工程安全审查是强制性的。
需要生产环境访问权限。检查数据库状态、读取生产日志、使用真实用户数据测试。Claude Code读的是代码,不是实时系统,你已到达了边界。
你已经花了一个多小时。对于大多数bug,如果一个小时的调查还没有产生明确的假设,那么这个问题已经复杂到应该由工程团队接手了。在这个节点之后,你的时间回报率呈递减趋势。
尊重工程时间的交接方案。当你交接时,清晰沟通:
"我花了30分钟进行调查。以下是我的发现:[摘要]。我的假设是[假设]。我停下来是因为[原因,如需要生产数据或代码过于复杂]。你能从这里接手吗?"
这告诉工程团队你做了什么、你怎么想的,以及从哪里开始。他们不会重复你的工作,也不会疑惑你已经尝试了什么。
回报递减曲线。前20分钟的调查产生了80%的上下文价值。你了解到相关文件,形成了假设,并识别出不足之处。接下来的40分钟大概只产生15%的额外价值:确认细节、排除替代解释、记录边缘情况。超过一个小时后,你可能只是在原地迭代而没有实际进展。
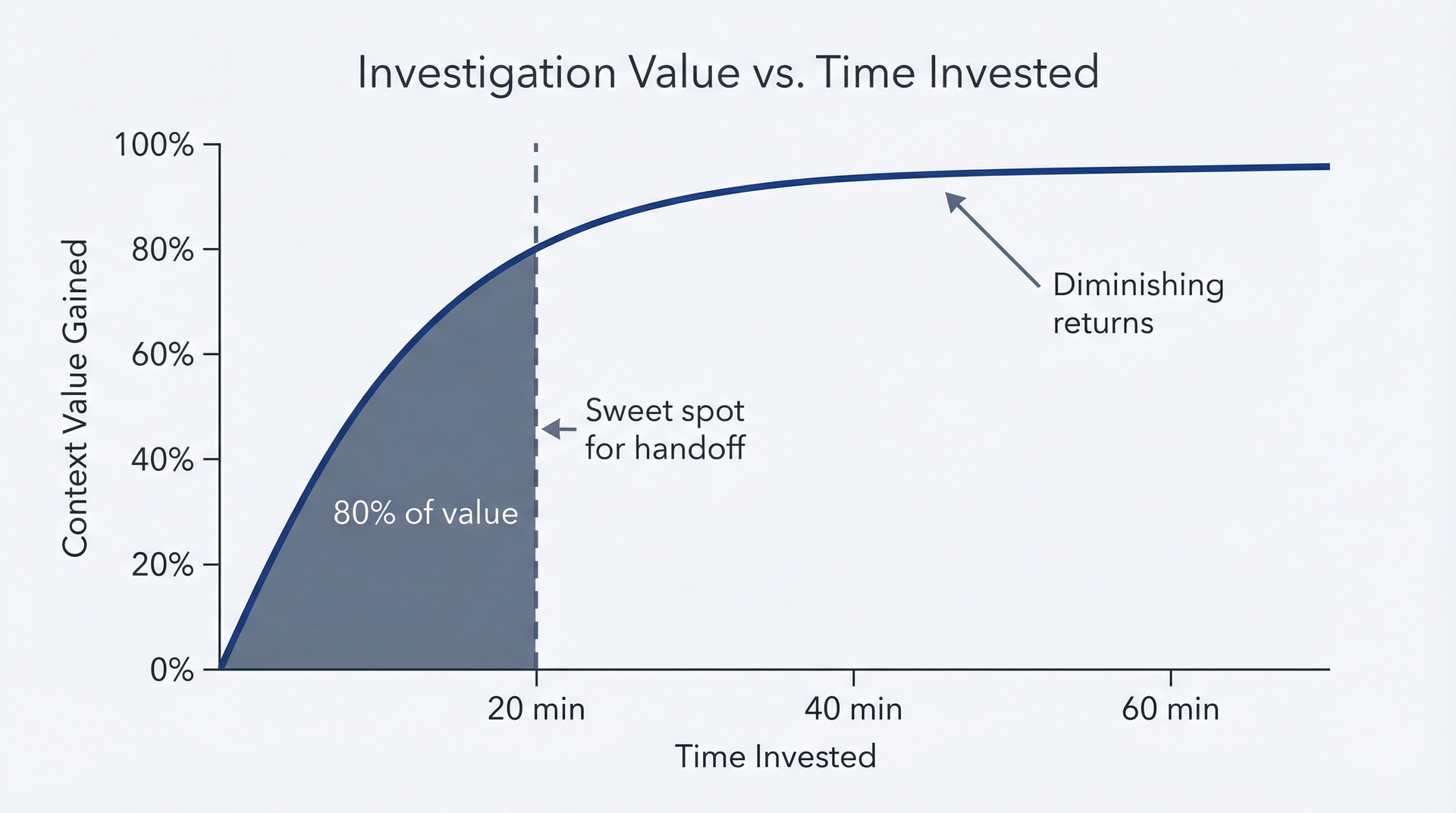
图 4.5:调查价值曲线——用于了解何时应该停止调查并交接给工程团队(20分钟规则)。曲线在前20分钟内急剧上升,捕获80%的上下文价值,随后显著趋于平坦。20分钟处有一条粗体竖线,标注为"交接点",并附有提示:"在此停止——工程师从此处接手。"绿色区域(0-20分钟)表示PM价值高;黄色区域(20-40分钟)表示收益适中;灰色区域(超过40分钟)表示回报递减。
对于简单的bug:15-20分钟的调查,然后交接。
对于复杂的bug:最多30-45分钟,然后带着清晰记录你尝试过什么的文档交接。
对于关键/紧急的bug:10分钟收集初步上下文,然后与工程团队并行工作,而非串行交接。
何时应该完全跳过调查。有些问题不需要PM进行前期调查:
- 用户报告的安全漏洞:立即向安全团队上报
- 生产环境宕机:事故响应由工程团队处理,而非PM
- 需要立即hotfix的问题:调查会延迟行动
- 复现步骤明确且影响显而易见的bug:直接提交工单
当收集上下文所节省的工程时间超过它所耗费的PM时间时,调查才产生增量价值。对于显而易见或紧急的问题,跳过调查直接交接。
现在,你可以在不依赖工程团队进行初步triage的情况下调查bug了。你理解了如何将用户投诉翻译为技术查询、遵循结构化的调查工作流、识别常见的bug模式、撰写有用的bug报告,以及知道何时该停下来。这种能力改变了你与工程团队的关系。你是调查中的合作伙伴,而不仅仅是一个工单转发器。
第5章将焦点从代码库工作转向研究:利用Claude Code进行市场和竞争分析,产出可持久化、可版本化的成果。